This page is a supplemental resource for the application
programs and other
software available on this site.
Initially posted after the first major applications release on
June 15, 2017, this page hosts two content sections with
their own indexes (which toggle here if JavaScript is enabled
in your browser):
Why this page? Although each application program comes with a
README.txt file that
describes known issues and workarounds at the time of its latest publication,
new items are bound to arise over time in any nontrivial software. This page
documents issues uncovered after major releases and hence unmentioned in prior
versions' documentation, and logs later software releases. Users are invited to
consider this page a virtual docs appendix, and check back for updates over time.
The latest content update here:
February 23, 2022.
This section announces new releases of published applications and programs. Note
that this list is primarily focused on the larger apps enumerated here;
see the Programs page at large for other programs not
covered on this page. To see this section's index, go to the TOC.
The Mac app packages of the
Frigcal and
PyMailGUI programs were rereleased on August 14, 2017,
to address a rare output error that likely stems from an issue in the
Mac's app-launcher system. Users of prior releases of the Mac app versions of
Frigcal and PyMailGUI are encouraged to fetch and install the new versions;
see your program's main
README file for upgrade pointers.
The source-code packages of these two programs
were also rereleased with the fix's code, but just as examples for developers;
the error occurs only when these two programs are run as Mac apps—not
when they are run as source code on Macs, and never on other platforms.
No other program packages were updated.
The complete description of the fix applied to Frigcal and PyMailGUI apps
is
off-page here,
because it is mostly of interest to developers.
In short, the main GUI in these two programs runs as a child process
spawned by a launcher GUI. Likely due to a misfeature or bug in the Mac's
app-launching system, it was not impossible that printed console output
generated by these apps' main GUIs could eventually trigger a broken-pipe
exception after the launcher GUI exited. Though rare, generally harmless,
and an issue in Mac apps only, these failures would manifest as GUI popup
error messages naming "Broken Pipe" as cause. The only observed consequence
to date was the need to rerun a calendar save operation in Frigcal just
once in nearly one year of daily usage.
PyGadgets, a set of 4 smaller GUI programs, was released as an addition to
the applications available on this site. Its main page lives
here, and its entry on the main programs page
is here. Though less broadly focused
than the other applications here, the PyGadgets toolset—a calculator,
clock, photo viewer, and game—are both potentially useful and educational;
work the same on all major desktop platforms; and are available as both
stand-alone executables and full source code. Note that this was a separate,
additional package release; no other application packages were updated.
PyGadgets was rereleased (all its packages) to fix
a minor defect in
PyClock,
which delayed redraws of the analog
display's minute and hour hands too long in some contexts. These two
hands are normally not redrawn until the second hand reaches 12, as a
valid and important optimization. This delay can be problematic, though,
if used after any state that precludes analog clock updates — including
window minimization, digital-display mode, system suspend, and menu and
modal-dialog view on some platforms. In all such cases, the analog time
might not be current or correct until the second hand again reaches 12.
To avoid this lag, PyClock now monitors the last-analog-redraw time to
force all hands to be redrawn immediately in all these contexts.
As a related optimization, PyClock now also avoids updating the analog
display's AM/PM label every second, just like the minute and hour hands.
This seems to have further reduced the memory leakage that occurs while
the analog display window is open on Macs: open-window growth is now just
1M per 20 minutes, which translates to 3M/hour, 72M/day, and 500M/week.
This is roughly half what it was formerly — a compelling reason to
retain the prior paragraph's optimization — and some popular Mac apps
use substantially more memory over time (see your Mac Activity Monitor).
Oddly, the digital display now leaks memory fastest, but is likely lesser-used;
optimizing it remains a low-priority TBD.
Also changed
PyCalc
to automatically set the focus on new "cmd" popups'
entry fields (which also shifts focus to their windows on Windows), and
added a Mac All Desktops tip
(below) to the README.
tagpix—a command-line script used to normalize photo collections—has been released
in a much-enhanced version, with new support for duplicates resolution, error recovery,
by-year grouping, and much more. For the full story, including a list of changes
in this version, see the new User Guide.
To download a copy, visit the tagpix web page.
Update:
tagpix was released again in 2018 with new support for copy-based file transfer
modes, customizable subfolder skips, prior-result-deletion verifications, and
improved duplicates handling. For more details, see its
release notes.
PyGadgets was rereleased (all its packages) to
include a new version of
PyPhoto,
which stores a folder's thumbnail images in
a single pickle
file,
instead of individual image files in a
subfolder.
This new design requires no more space or time, but avoids extra files (15k
images formerly meant 15k thumbnail files); multiple file loads and saves;
and nasty modtime-copy issues for backup programs too rare and complex
to cover here. See the source code for full
details.
This is a mildly backward-incompatible change. Prior PyGadgets/PyPhoto version
users: when upgrading to a newer release, run the included
delete-pyphoto2.0-thumbs-folders.pyscript
(or its frozen executable) from a command line to delete all former PyPhoto
thumbnail subfolders. This program is run with no
command line arguments, and asks for a folder path and delete verifications.
In the Mac app, it's an executable at PyGadgets.app/Contents/MacOS
(see Show Package Contents); in other packages, it's in your install folder.
PyPhoto will still work if you don't delete the former subfolders,
but they will be unused trash.
Apart from this compatibility fix, the main user-visible artifact of this
upgrade is a single _PyPhoto-thumbs.pklfile
per opened folder, instead
of the former thumbs subfolder. This thumbnail cache is still built on
first open and auto-updated on changes as before, to make later opens fast.
Though less prominent, the new PyPhoto also displays images in the same
order
everywhere;
uses a placeholder thumbnail for photos with
errors
(instead of omitting); and works on unwritable folders (though slowly).
PyPhoto now also supports a new NoThumbChanges configuration-file setting
and command-line argument, which can be used to prevent rare but spurious
thumbnail regenerations for large, static archives, when file modification
times are skewed between platforms or filesystems. See
PyGadgets_configs.py.
This setting's False default need not be changed in typical usage. For
example, PyPhoto photo archives and thumb caches have been seen to work
correctly without this change when used on a single platform, burned to
BD-R discs, or transferred between Mac OS and Windows on exFAT drives.
This release also applied a minor change to
PyCalc,
to allow fractional
floating-point numbers to be entered with a leading . instead of 0..
To halve a number, for instance, 24 * .5 and 24 * 0.5 both now work.
Numbers with E exponents allow both forms too: .1E-99 or 0.1E-99.
Version 3.1 of the Mergeall content backup and propagation
application includes multiple minor enhancements for all download packages, and is a
recommended upgrade for all users (be sure to save and restore your
mergeall_configs.pycustomizations).
In this release:
Where supported, Mergeall and the cpall module it uses now propagate
modtimes of folders too
Mergeall flushes the output of its Linux executable to avoid buffer lag in the
GUI
Diffall and cpall have a new -u unbuffered switch for use with
tail on their apps and executables
The Mac app package preserves the original modtimes of its resource files,
including tests
For the full story on these changes, see the
release notes.
The PyPhoto
image-viewer GUI program included in the PyGadgets bundle has
been updated to include three enhancements, the first two of which were borrowed from the
thumbspage image-gallery builder. The new PyPhoto:
Automatically rotates tilted images with "Orientation" Exif tags to display right-side
up—both the thumbnail when stored, and the image when viewed. This is especially
useful for photos shot on smartphones. Unlike thumbspage, full-size images in PyPhoto
are rotated in memory only, and their files are never changed. See the before and
after rotation screenshots
here and
here.
Includes a workaround for a Pillow library bug which could trigger too-many-open-files
errors in rare contexts (mostly, for Mac OS source-code use, as described
ahead on this page).
The fix allows an arbitrarily large number of thumbnails to be created in a single step
on all platforms and with all PyPhoto packages.
Includes a workaround for an obscure buffer-file format issue in older Pillows,
that could trigger errors on thumbnail saves, and impacted some source-code users
only—apps used a Pillow version without the issue, and newer Pillows are fixed.
This workaround is not required in thumbspage, as that program does not use buffer files.
This PyPhoto upgrade is now available in all PyGadgets download
packages.
Users of the prior PyPhoto version should delete their
_PyPhoto-thumbs.pkl cache files in image folders to
enable the image auto-rotation enhancement.
Otherwise, images will rotate when viewed, but already-created thumbnails
will remain askew till deleted and recreated.
For more details, see the version 2.2 release notes in code files
here and
here
This section collects usage tips for published applications that
arose after releases, and hence are not covered in earlier releases'
documentation. Note that dates below reflect first postings;
some items have been revised later, per their entries' updates.
To see this section's index, go to the TOC
On recent Mac OS X systems, and on Windows 7, 8, and 10, you may get a warning when
first trying to use this site's applications, because of defaults regarding unverified
sources —
arguably overkill at best, and a step towards proprietary lockdown at worst.
You can safely ignore these, but may have to approve a program the first time
you use it; see the warning popup for more details, where available.
On Macs, for example, Open in the two-finger-press or control-click menu
approves a program quickly and permanently, and may be faster than opening the
Security & Privacy preferences screen.
This inconvenience is regrettable, but this site's proprietor is an
independent developer who does not work for Apple or Microsoft, and has no
interest in the supplication inherent in program registration.
Some web browsers can be Orwellian about zipfiles
too;
and Windows 10 S, unfortunately, is
right out.
Update:
there's more on the first-run story ahead on this page—jump to the 2020
addendums for expanded coverage of launching this site's apps on
Mac OS and
Windows 10.
Synopsis: the warnings may be growing nastier, but you can still use
trusted independent apps freely after an initial rightclick+Open on Macs,
and a Run or click+Run anyway on Windows. For now?
On Windows, you should generally avoid saving unzipped exe folders in
C:\Program Files because neither you nor programs may have permission to
save files there. The current program READMEs
suggest this location as one possibility, but this can lead to issues.
For instance, using that folder can complicate config-file edits (you may need
to run editors as administrator), and can even prevent the Frigcal launcher from
closing (it won't find a sentinel file because one cannot be written in its
install folder). To avoid such issues, save your unzipped exe folders to your
Desktop or elsewhere instead (despite the advice!).
On Mac OS X, the apps have not been tested or built with
Python 3.X and Tk 8.6 from Homebrew
(a leading alternative distribution that supports the newer Tk)
because the Homebrew install is currently broken—Python
and Tk build correctly, but crash immediately with an "Abort trap: 6."
This is a widespread issue that impacts both app builds and source-code
use, and makes it difficult to explore possible fixes for Tk 8.5 Mac
issues (e.g., Dock zombies and scroll speed).
Given the requirements of a manual
build, this effectively puts further research on hold.
You can read others' reports about this issue
here and
here. The latter
includes a curt refusal to fix from the project, delegating the
job to impacted users. No, really. It's not clear where this bug lies,
but projects that publish a product clearly have some responsibility for
that product. That is: broken + rude = punt; Homebrew is currently neither
viable nor recommended. Hopefully, python.org's Mac Python3 will support Tk 8.6 soon.
Update: as of August 7, it appears that this critical Homebrew Tk 8.6
bug may have been fixed, per later posts on the GitHub
thread.
Apparently, an early release of the next version of Tk was required.
This is good news if true (and the Mac apps here may be revisited soon),
but the outright crash on startup doesn't exactly instill confidence in
Homebrew and/or its Tk on Macs going forward. To be fair, though, the Mac's
rich user interface is stateful enough to pose challenges to any GUI toolkit.
Update:
after testing Homebrew Python 3.6 + Tk 8.6 on Mac OS Sierra
in September, 2017, it now appears that Tk 8.6 on Mac is a non-starter.
It does indeed fix the Dock menu zombies problem of ActiveState's
Tk 8.5.
But 8.6 also:
Scrolls Mergeall output slower than 8.5:
8.6 can take 90 seconds instead of 60 to scroll a 2-second run's output
Has a new and nasty redraw-on-deiconify bug that opens some
widgets blank and redraws parts on mouse-over
Though less pronounced than 8.5, still leaks memory
when updating PyClock's canvas display
Still runs into Abort trap 6 hard-crashes in
some contexts, even after the start-up fix noted above
Alas, Tk on Mac is not always all it should be. It's possible to
use it for programs like those on this site,
but this requires substantial workarounds (of the duct-tape-and-twine sort),
and the resulting programs have to live with a set of defects that varies
per Mac Tk release.
If you're developing commercial-grade GUIs, see
PyQt for one portable alternative, and
PyObjC for a non-portable option;
and mind the pitfalls inherent in development under the open-source "batteries included"
banner, and its proprietary cousins.
Update: as of spring 2018, python.org now
offers Python 2.7 and 3.6 installers for Mac OS 10.9 and later that include Tk 8.6.
This is welcome news and obviates the need to install Tk separately from third-party
sources, though early testing suggests that the new install may pose issues and
bugs of its own. See the details ahead.
A technical note for PyEdit users only:
as documented in PyEdit's
UserGuide.html
and
textConfig.py,
its auto-save feature always writes text with unsaved changes to files using the
general UTF-8 Unicode encoding scheme. This is necessary, because there may be no known
encoding (e.g., the text may not yet have been saved to a file), and a known encoding may
fail (e.g., Unicode symbols may be inserted into the text of a file originally opened as
ASCII, precluding ASCII encoding on saves).
This UTF-8 policy may cause issues, however, for HTML files that declare a different
encoding explicitly using <meta> tags. If you must recover such a file from the
auto-saves folder, you can either change its <meta> tag to declare UTF-8, or
convert its text back to the original encoding. For the latter, you can easily
restore the original encoding by:
Opening the auto-saved file in PyEdit as UTF-8
Clicking the File=>Save As menu action (or typing its control/Alt-s accelerator)
Entering your desired Unicode encoding name in the popup issued in the GUI
Naturally, this assumes your text is still compatible with the encoding you enter
(else, PyEdit will generally fall back on UTF-8 again), and be sure to use Save As
(Save silently uses the encoding provided on Open if the text came from a file).
This issue is both rare and subtle, but unavoidable in files with explicit and
usage-specific encoding declarations that may diverge from actual content.
For more encoding-conversion options, see
savesUseKnownEncoding in
textConfig.py,
and the command-line conversion utility
script unicodemod.
As mentioned in the main
README
files of all the complete applications available on this site, the current
releases of the Mac apps can leave zombie entries for closed windows
in their Dock menus due to a bug in the underlying Tk 8.5 GUI library used. This
remains a to-be-fixed item, pending adoption of a new Tk version
(which now seems unlikely; see above).
Fortunately, it turns out that there is a standard and easy way to see
the apps' truly active windows anyhow: simply use a 3-finger downswipe
on the trackpad (or its control+downarrow keyboard equivalent) to activate
the "App Exposé" view of active app windows. This gesture can be performed on
any of the app's windows, or on its Dock icon. When run on the Dock
icon, this is no more difficult than opening the Dock menu with a
2-finger click, and yields an arguably better and full-screen display
that does not include any zombie entries.
This is a standard Mac feature, but may be unknown to some users, and
is mentioned only in passing in the apps' READMEs.
You may need to enable it once in System Preferences by clicking the
App Exposé checkmark. Once enabled, though, this provides a simple
way to view an app's open windows, and is immune to Tk 8.5 zombies.
Semi-related tip:
as noted in
app docs,
Mac OS Tk also scrolls text slowly, which impacts the
Mergeall program's status display of log messages
on this platform (only). If this grows too slow to tolerate, and Mergeall's
toggle
for suppressing comparison messages doesn't suffice, you may be able
to skip scrolls by simply minimizing the program's window to the Dock;
on reopening, scrolls will be either advanced or finished.
Update:
the February 2022 rebuild of Mergeall's macOS app no longer has the dock-menu zombie
issue, because it uses a newer Tk.
The rebuild does, however, no longer reset widgets to their active style after a
minimize+restore—thus trading a fix for a breakage.
Other programs have not been rebuilt (yet?), and hoard zombies just as greedily
as before.
In hindsight, it's also possible that Mergeall's code may have made it immune
earlier, because it builds no Toplevels, but
the verdict must await other apps' rebuilds.
Similar to the Windows exes note above: one user has
reported that the Frigcal Mac app can fail if copied to and run from Desktop
on Mac OS X Sierra, because the app does not have permission to write files
(Frigcal needs to create an initial calendar file on first run, and a sentinel
file on each run). This couldn't be recreated on El Capitan or Sierra machines,
may be user-specific, and is outside the apps' scope. If your apps have
similar problems on your Desktop, though, copy them to your /Applications folder
instead; this has the added advantage of adding the app to Launchpad for
quick access.
For reasons to be determined, import statements in code run by
PyEdit's RunCode
can fail if they attempt to import a module package having no __init__.py file.
That is, Python 3.3+ namespace packages don't seem to be fully operative in code
run by a normal compile()/exec() pair, despite all the run-time context set
up by PyEdit's code proxy. This may reflect an anomaly or bug in Python's import
machinery (which changes so often as to be fairly accused of thrashing), and may
require use of Python's
runpy module or similar code.
Barring a future fix, though, the workaround is simple: simply make sure all
your package folders to be used in RunCode have an __init__.py, even if it's
completely empty. Unless your use case really requires namespace packages
(and almost none do), an __init__.py is good and recommended practice anyhow.
It makes your package imports more efficient, and your code's structure more
explicit. For more on PyEdit's RunCode, see its Tools menu
docs.
For a primer on 3.3+ namespace packages, try Chapter 24 in
Learning Python, 5th Edition.
PyGadgets'
calculator
and
clock,
for example, are the sorts of desktop utilities you might want to access
occasionally and quickly.
Simply open once and set to All Desktops per above, then minimize when not in use,
and click the Dock icon to reopen. This both displays an open gadget on
every desktop, and reopens a hidden gadget immediately on the current desktop.
Perhaps best of all, this avoids the annoying and attention-shattering
desktop switches that occur by default when you reopen an app assigned
to its single, original desktop.
Two fine points here. First, this works whether your Dock preferences set "Minimize
windows into application icon" or not, but the All Desktops setting is in the
Dock's application icon. Second, this can also be used for the
Frigcal
calendar GUI (which also reopens its month image on the current desktop), but may be
less desirable for apps like the
PyEdit
text editor that create many windows or take special actions on Dock clicks
(see Programs for both).
Though usually not a concern, PyEdit's memory usage on Mac OS
might grow high if used for a long time without a restart. The exact cause remains to be isolated,
but this seems to occur when using PyEdit's Run Code option to run edited programs;
is noticeable only after intense work spanning multiple days; and isn't particularly
grievous by Mac standards. The worst case to date saw PyEdit reach 2G memory
(from its 36M start) on El Capitan, but it was still #3 on the worst-memory-offenders
list at the time, behind both Firefox and WindowServer, and just ahead of Excel. Moreover,
almost all of PyEdit's memory space was compressed (not in active use).
Still, if this grows problematic on your machine, the simplest solution is to
periodically close all PyEdit windows and restart—an unfortunately common
cure for Mac app ills. For a related topic, see the memory leak workarounds in
the PyClock program of PyGadgets, covered in its
README; though nonfatal,
memory issues seem a recurring theme for Tk apps on Macs.
Update: The preceding memory-growth issue no
longer occurs in 2024's version 4.0 of PyEdit on macOS. It was apparently a memory
leak somewhere in the software stack below PyEdit and was fixed between the 2017
and 2024 PyEdit releases.
The Mergeall backup/mirroring application goes to great lengths
to avoid propagating "cruft" files (platform-specific trash), and in its
User Guide
points to the numerous .DS_Store hidden files on Mac OS as prime offenders. These files
can be pathological on Macs for anyone involved in programming or content production,
and were responsible for many of the changes required to support the Mac platform.
As of Mac OS Sierra (10.12), setting your defaults to display hidden files as described in that
guide still works as before, but Finder has been special-cased to never display .DS_Store files.
That is, the .DS_Store files are still there (and can be seen via an ls -a in Terminal, or
an os.listdir() in Python), but Finder will no longer show them to you; even if you ask it to.
You can read more about this curious new Finder policy on
the web.
This seems the worst of both worlds. Not only does Finder still create these files
in every folder you view (changing your folders' modification times in the
process),
but not displaying them can easily lead to major problems if they wind up being
inadvertently uploaded, transferred, or otherwise included with actual content.
Pretending a problem doesn't exist is not a valid solution to a
problem—especially when users may have to pay the price for the deception!
Luckily, you can still take control of cruft like .DS_Store files with tools like
Mergeall and ziptools that
callout such items explicitly to help you minimize their impacts. We can also hope
that Apple someday finds a better way to record Finder information than dumping it
in hidden-but-real .DS_Store files all over your drives. Sadly, this still
seems wishful thinking as of the new High Sierra and its oddly mandatory
APFS filesystem.
Footnote:
also in the oddly column, Mac OS High Sierra abruptly dropped the longstanding
and widely used ftp client program, in yet another agendas-versus-customers move.
See the
web for discussion;
in short, secure sftp is still present, but works only for sites that support it,
and this doesn't help programs or users that relied on the functionality removed.
Alas, open-source software is not the only domain where the whims of
the few can rudely trounce the needs of the many.
On the upside, a simple Python script can shatter many an
Orwellian decree...
Postscript:
and in the too-ironic-to-bear department, Mac OS High Sierra
also came with a massive
security flaw
which allowed anyone to gain root access to a machine without a password, and required
an emergency overnight patch. But ftp was too risky to ship.
The Mergeall content backup/propagation program is usually run from its GUI
launcher,
but can also be run from a command-line, and includes some extra
command-line scripts useful for managing archives. The most
notable of the extras may be
diffall,
a program which does a byte-by-byte comparison of everything in two folder trees,
as described in Mergeall's
User Guide.
Because diffall can run for a long time on large trees, it's
convenient on Unix to run it in the background and monitor its
output file with a tail using command-lines like the following
(typed in Terminal on Mac OS):
That works on Mac OS's El Capitan release, but not quite on its High Sierra.
For reasons that aren't clear, when redirected to a file, Python 3.5's stdout
stream—the target for basic print() calls—is not buffered (or not
buffered as much) on the former, but is fully buffered on the latter.
Hence the tail may not show anything for quite
some time on High Sierra, and even then, will print only in spurts.
Technically, El Capitan may buffer stdout too, but its buffer blocksize may be
so small that its output appears regularly, while High Sierra's does not.
To make printed text show up in the output file immediately on both
Mac OS versions (as well as other Unix-like platforms),
pass Python's -u unbuffered flag in the first command above:
Or, set the equivalent environment variable in your shell (e.g.,
in ~/.bash_profile) and skip the -u argument in the command line:
~$ vi ~/.bash_profile
export PYTHONUNBUFFERED=1
Either way, this forces Python print() calls to send their output
immediately on all platforms, so that it can be watched with a Unix
tail. Unfortunately, -u doesn't apply and the environment variable
has no effect in the Mac app's frozen diffall executable,
so app users will want to grab the source-code version to tail its stdout on
platforms where stdout is buffered. This isn't required on El Capitan,
because the frozen diffall's stdout is not buffered much there either
(though to be fair, it's not clear which systems are broken!).
For more possible-but-unverified ideas, see also this discussion
thread.
Per preliminary testing, however, its export NSUnbufferedIO=YES
suggestion appears to have no effect on the app's frozen diffall.
And if you're willing to change code, you can also reset sys.stdout
to an object whose write() method always calls flush(), or, in Python 3.3+
only, use the extended form print(x, flush=True) for all prints.
It's not clear that this should be done, though, as buffering is an
optimization, and diffall's output can be large (e.g., it's 6MB big and
144K-lines long for an archive with 101K files and 10k folders);
if implemented, this should probably be a diffall command-line option.
Consider these suggested exercises—until the next Mergeall
release (spoiler: it grew its own dedicated -u).
Short story: Mergeall may
report unexpected differences for files extracted by unzipping a zipfile,
due to unzip tools' inconsistent handling of modification times across time changes.
There is no complete fix for this, but you can use the
same unzip tool each time to lessen impact; use this site's ziptools
for zips and unzips to neutralize the issue in full; allow Mergeall to recopy
unzipped files after they are extracted; or avoid including frequently unzipped
files in your archive—include their zipfile instead.
Details
Due to inconsistent handling of file-modification times
across the many unzipping tools in use, it is not guaranteed that a given
file's times will survive a zip and unzip combination. Just as for FAT32,
zipfiles generally record file times in "local" time, which may or may not
be adjusted on unzips for daylight savings time (DST), and may be impossible
to adjust on unzips for time-zone changes. This can in turn throw
off any program that relies on file-modification times, including Mergeall;
its change-detection is fully dependent on timestamps.
As discussed in more detail in Mergeall's
User Guide,
the FAT32 issue can be addressed by using a different file system such as exFAT
for cross-platform drives to use Unix UTC time.
The unzip issue, however, is much more thorny: an unzipping program may actually
modify a file's recorded modification time as it recreates the file, and only
for files last modified in a given time zone or DST phase. Hence, the differences
reported by Mergeall are real but spurious (timestamps differ even if content
does not), and globally adjusting all files' times up or down with a script
like this
isn't an option
(only a subset of files may have their times changed on extracts).
Perhaps worse, different unzip tools may apply time-adjustment rules differently,
precluding an automatic workaround. For example, unzips in both the
ziptools system available at this site and the
unzip command on Unix produce modtime results which have been observed
to differ from those of the Archive Manager used by Finder on Mac OS—even when
zipping and unzipping in the same DST phase. Finder's results may be askew, but they
preclude a universally relevant adjustment.
In more detail, ziptools currently inherits the time.localtime() local-time
creation in Python's zipfile module for zips, and defers to the local-time
reversals of Python's time.mktime() for unzips. When zip archives
are created by ziptools' zip-create.py using this scheme and unzipped
in the same DST phase, Finder clicks produce modtimes that erroneously differ from
the original data for some (but not all) files, but both the Unix command-line
unzip and ziptools' own zip-extract.py yield no modtime
differences. Finder seems to expect a skew in the zip that does not exist.
For more background on this issue, try a web search like
this one.
The upshot of all these factors is that Mergeall may report differences and run recopies
for arbitrarily many files in an archive after they are re-unzipped from a zipfile.
This is a rare issue (and has arisen just once in 4 years of regular Mergeall use),
but has no absolute fix. It may be minimized by using the same unzipping tool every
time for a given set of files (see ziptools for a portable
option). Barring this, you'll need to allow Mergeall to recopy the unzipped files
that differ after unzips, or avoid keeping their unzipped versions in a Mergeall
archive tree in the first place. The latter may be the simplest approach for files
that will be unzipped often.
Interestingly, standard zip-file times are also limited to two-second precision
just like FAT32, but Mergeall automatically accommodates this thanks to former fixes.
The bizarre munging of time by some unzip tools can also impact thumbnail-change management in
the PyPhoto gadget, but in this context would
simply trigger one-time thumb rebuilds. Other programs may fare worse after unzips.
A full solution here, of course, may lie in either abandoning zipfiles altogether,
or standardizing time formats across all computer systems in use today. Given both
the popularity of zip and this industry's tendency towards fragmentation and flux,
the odds of either solution appearing in our lifetimes seem about as good as those
of an open-source project settling on a feature set...
Update: per the
docs in release 1.1 of
ziptools,
both DST and timezone issues in zipfiles can be
addressed by storing items' UTC timestamps in the zipfile using one of the
"extra fields" defined by the zip standard.
In particular, the "extended timestamp" extra field (code 0x5455)
added by Info-ZIP seems ideal for this purpose. When present on
unzips, these extra fields can override the main local-time field,
and are simply ignored by other zip tools that don't support them.
This is a full fix to zip's local-time issues, because UTC timestamps are
relative to a fixed point, and thus timezone- and DST-agnostic.
Naturally, this won't help for zipfiles created by tools that don't
record the extra field, and is difficult to code for Python's zipfile
library module. Still, it's likely to appear in a ziptools release near you soon.
Update: the UTC timestamp scheme of the
prior note was indeed implemented in release 1.2 of ziptools, in
April 2020. At least for zipfiles it makes, ziptools' modtimes are at last
fully immune to changes in both DST and timezone. See its
documentation
for the whole story.
Short story: if you wish to use
PyEdit to edit Unicode text files
that begin with a BOM character, be sure to open them with an
encoding name that discards the BOM if present (e.g., 'utf-8-sig'
for UTF-8, and 'utf-16' for UTF-16). You can also delete their
BOMs permanently by opening the same way and saving with an encoding
that doesn't add a BOM on output (e.g., 'utf-8' for UTF-8), or
removing the BOM in the edit window as it is displayed.
PyEdit doesn't add BOMs unless your encodings ask it to, but other
editors may insert them automatically. If not accommodated or removed,
a BOM will make the first line render oddly and difficult to edit,
though the effect varies per platform.
The Issue
To understand this issue, you need to know a bit about one of Unicode's
darker corners. In brief, text may start with an identifying marker known as a
BOM,
in the UTF-8, UTF-16, and UTF-32 encoding schemes. This marker
can be used to declare the bit order (little- or big-endian)
and encoding scheme of the encoded text that follows.
Widely used UTF-8 files, for example, can begin with a BOM or not.
When present, the BOM in such files is a nonprintable Unicode character
with code point \ufeff, which is encoded as bytes b'\xef\xbb\xbf'.
Because encodings handle BOMs differently, selecting the right one
can be crucial. In Python (and Python programs like PyEdit),
neither 'utf-8' nor 'utf-8-sig' require a BOM to
be present, but only the latter discards a BOM on input and adds one back on output.
It's easy to see this in code. A binary-mode file read always retains an
encoded BOM at the front, and text mode gives the BOM's decoded code point
unless it is discarded by 'utf-8-sig'. Here's the story for a BOM-laden
UTF-8 file in Python 3.X, the version PyEdit uses (codecs.open() works
essentially the same for text mode in 2.X, sans endline transforms):
This issue is rare, but it cropped up recently in the HTML of a web
page edited in PyEdit. Somewhere along the way, a text editor on Windows
or Mac OS silently inserted a BOM at the start of the file's UTF-8 content
(as usual, Windows Notepad is the prime suspect). The covertly added BOM
is harmless in web pages with content-type UTF-8, but causes the file's
first line to be munged in PyEdit when opened with its 'utf-8' encoding
default.
The effect is mild: the BOM renders as a blank character at
the start of the first line, which you can skip over or delete
as usual.
On Windows
The effect is moderate: the BOM renders as an invisible character
at the start of the first line, which requires an extra right-arrow
to skip over. It can, however, be deleted with a normal Delete press
at the start of the first line (and a leap of faith...).
On Mac OS
The effect is worst: the first line's content
appears to be doubled, and editing it is chaotic at best.
The BOM is actually the first character of the duplicate-text line;
it can be removed by deleting the first character displayed in the line,
but this isn't obvious, and retyping the line may seem the only recourse.
In other words, the BOM is rendered as the first character of the first
line—whether you can tell or not. To see what happens on your machine,
run code like the following to emulate the BOM-happy policies of editors
like Notepad, and open the created file in PyEdit as 'utf-8':
By contrast, PyEdit never discards or adds BOMs automatically,
because it supports the full spectrum of Python Unicode encodings for
both opens and saves, as a major distinguishing feature; it could not guess
your wishes for BOMs in output, especially if they were stripped; and it
refuses to enforce implicit global policies that are invariably incorrect
in some contexts eventually.
The last point is paramount; to be blunt, the simple-minded policies in
other editors are the reason that HTML files sprouted unwanted and
error-prone BOMs in the first place!
The Fix
Because explicit beats implicit in programs that you trust with your
content, PyEdit expects you to clarify your BOM goals, by either:
Handling the BOM properly on Open with an appropriate
encoding name (e.g., 'utf-8-sig')
Deleting the BOM by careful use of Save As
(e.g., Open with 'utf-8-sig' and Save As with 'utf-8')
Either approach works because 'utf-8-sig' discards a BOM if present
on input, and only 'utf-8-sig' adds one back on output. If you go
with the first option, be sure to use the correct encoding name on
each PyEdit Open; the second option is a one-time delete, after which
'utf-8' will suffice for every Open.
You can arrange these combinations in PyEdit's configurations file by either
fixing the open and/or save encodings, or having PyEdit ask for them
(save's encoding defaults to open's if not fixed; see the end of your
install's
textConfig.py
for more details).
Some might even propose that PyEdit should automatically use the
'utf-8-sig' of these schemes for opens and/or saves, but magic is
a very slippery slope: implicit BOM deletions and additions seem
equally error-prone (and rude); this wouldn't work for people
using other encodings like Latin-1; and most PyEdit users can safely
ignore the issue altogether and stick with the preset 'utf-8'default.
In fact, if you don't care to deal with encoding names, you can generally
accept the default 'utf-8' for both opens and saves, and simply delete any
BOM characters as they are displayed in PyEdit, if and when they are added by
other editors. The platform-specific renderings above
give display details, but a delete at the top of the file suffices for all.
This works well, but may not be as intuitive as explicit encoding names.
Either way, the net effect of deleting BOMs in PyEdit is also easy
to verify in Python. The following was run after using the PyEdit
Open/Save As combination on the UTF-8 web-page file we met earlier,
to save to a "-nobom" BOM-free copy:
UTF-8 is common for web pages, but it's not the only offender.
UTF-16 and UTF-32 files may also be BOM-ridden, though their encodings work oppositely.
In UTF-16, the general'utf-16' always both discards a BOM on input
and adds one on output (like the specific 'utf-8-sig'); but the more
specific'utf-16-le' does neither (like the general 'utf-8');
and ditto for UTF-32. To you, this means 'utf-16' and 'utf-32'
generally suffice in PyEdit, because they both strip and restore BOMs in files:
Finally, if you want to see which files in a folder tree may be
clandestinely harboring BOMs, try something like the following (this code
looks for UTF-8 BOMs in all HTML files in the current working directory;
tweak as needed):
import os
for (adir, subs, files) in os.walk('.'):
for file in files:
if file.endswith(('.htm', '.html')):
path = os.path.join(adir, file)
try:
text = open(path, 'r', encoding='utf8').read()
except:
print('Not UTF8:', path)
else:
if text[:1] == '\ufeff': # Or try file.read(1)
print('BOM=>', path) # This file has a BOM
When run by command line, file click, IDLE, or PyEdit's own
Run Code, your output will be similar to this:
Not UTF8: ./lp3e-updates-notes-python.html
Not UTF8: ./lp4e-preface-preview.html
BOM=> ./lp4e-updates-clarifications-first-printing.html
BOM=> ./lp4e-updates-clarifications-recent.html
For more background on the Unicode BOM—including more about its
behavior in the UTF-16 and UTF-32 encodings omitted here for space—see
the documentation at the top of the
unicodemod.py script on this site, as well as
the more in-depth coverage in the Advanced Topics part of the book
Learning Python.
For related tips, also see the Unicode conversion note
earlier on this page, and the next note.
Speaking of PyEdit's configurations file:
if you look at the Unicode settings near the end of
textConfig.py,
you'll notice that its fallback and prefill default encoding is
sys.getdefaultencoding()—which is Python 3.X's default for
string-object methods, and not locale.getpreferredencoding()—which
is Python 3.X's default for open().
This is by design, because the former's UTF-8 setting is the same everywhere.
If PyEdit used the latter, default file encodings could vary per platform.
The net effect would be that people who work across multiple machines with
different locale results (e.g., Unix and Windows) might have to remember
where each file was last edited in order to provide an encoding that opens it
properly! This is a major downside of 3.X's open() defaults, and one more
reason that you should use explicit encodings whenever possible.
That said, if you generally work on just one platform and really want to use
the locale module's setting (or any other value) as your PyEdit
encoding default, it's easy to do so; the configurations file is just a Python
module, after all:
If you use locale and skip the encoding-input dialog, though,
please remember that your files' encodings may vary per editing platform.
Python 2.X allows the sys module's setting to vary too (it can be
changed at start-up, and by dark hackery intentionally omitted here), but
Python 3.X, PyEdit's implementation language, makes it more of a constant.
For additional coverage of Python 3.X's encoding defaults, see the manuals
or the overview in this article.
Update:
be aware that 3.X file-encoding defaults in the locale module might
also vary per environment settings, and this can have substantial consequences in
some contexts. CGI scripts run on a server in a generic-user process, for example,
might not have expected or required settings, and thus run with a basic encoding
default like ASCII that won't handle richer types of text. Former victims of this
subtle trap can be explored at this site's
code-viewer and
site-search CGI scripts.
This update is half release announcement and half usage pointer, so it
shows up in both tables on this page. As of April 2018, the user guides
of all major apps (i.e., programs) on this
site are now mobile-friendly.
These guides' content is unchanged, but they have been restyled for viewing
on both desktop and mobile browsers and devices. They have also improved
in general, if only cosmetically, marginally, and subjectively.
At this writing, the new mobile-friendly versions are currently available
online only. The original desktop versions are still shipped in product
zipfiles, and are opened by in-program help widgets by default (these are desktop-only
programs, after all). The original versions are no longer kept online, as they
are prone to fall out of sync with upgrades; see your zipfile for prior versions.
You can find the new mobile-friendly user guides on program
pages, as well as here:
There are additional examples of how these render on mobile devices
here and
here;
their desktop rendering is similar.
These new versions may eventually find their way into zipped packages in future builds.
For now, to use any one of the new user guides locally on your machine, simply
save the new page's UserGuide.html file in your browser
(e.g., via right-click), and place it in the root folder of your program's
install location. These docs are self-contained HTML files.
Notice that the PyGadgets program is not listed above,
because it has no user guide document; for usage pointers, see its
README.txt
file and the in-program
help
of each of the programs it launches. Also note that the screenshot
pages of
major desktop apps are still not mobile-friendly; given that they span some
75 indexes among 25 zipped products (5 apps, 5 products each, and 3 platform
pages apiece), they too await future app releases.
Update: as of August 2018, the online versions
of all apps' screenshots have now also been converted to be mobile-friendly,
and have been refreshed to use the latest version of
thumbspage and its viewer-navigation pages.
Updating online was a smaller-scale task (just 15 index pages and folders among 5
zipfiles, one for each app including PyGadgets). The new screenshot galleries will be
incorporated into app zip packages over time as they are rereleased. To see the new
screenshots now, visit app screenshot pages here,
or browse the full set in the live demos list here.
As of spring 2018 and Pythons 3.6.5 and 2.7.15, python.org now offers
installers
for Mac OS 10.9 and later that bundle Tcl/Tk 8.6. Assuming the new
installs' Tks work properly, this means that users of any of the
source-code versions of apps on this site
who install these Pythons no longer need to install a Tk GUI library separately.
There are additional notes about this change on
this page,
and three fine points to keep in mind:
This change is irrelevant to frozen (a.k.a. standalone) apps and
executables on this site, because they come with all their library
dependencies automatically included.
This change doesn't lift extra install requirements for source-code
versions of programs that require additional libraries beyond Tk.
PyGadgets' PyPhoto, for example,
still assumes a Pillow install.
Though the new installs' Tks are expected to be usable, this has yet
to be verified for apps on this site, and the earlier results listed
above advise skepticism.
Verification results for the apps on this site will be posted here
as time allows. As always, though, solutions of the past are still
available if those of the present come up short.
Update: per early testing in May 2018,
it now appears that the new Mac Python 3.6 + Tk 8.6 install may have serious issues,
if not outright bugs. Notably, the new install crashed on a simple file-save
dialog immediately after it was launched. While this does not impact apps or
executables, such results make it difficult to recommend the new install for
users of GUI source-code packages on this site. At the least, users of the
new install should expect to find and resolve an arbitrary number of issues.
For the full story on the new install's testing results, see
this post.
As uncovered in thumbspage, the third-party Pillow
image library has a bug that can make it run into Too many open files
errors during thumbnails generation in the PyPhoto
program shipped with PyGadgets. In short, Pillow doesn't close image files
when it should, which can cause it to breach system limits.
This can occur only for very large folders, and runs that generate very many
new thumbnails (several hundred suffice). Moreover, it is generally a concern only when
running PyPhoto's source code from a shell (a.k.a. Terminal) on Mac OS,
because that platform's shell imposes a low open-files limit by default. This
bug has not been seen to impact Windows, Linux, or users of PyPhoto in the PyGadgets
Mac OS app. Where it does occur, the bug kills the PyPhoto GUI,
but doesn't write or corrupt thumbnail information.
Luckily, the workaround is simple. When using source-code PyPhoto in a Mac OS
shell, simply run the following command to raise the open-files limit
before starting PyPhoto to view a large folder:
ulimit -n 9999
This handles as many images as you're ever likely to have in one folder, but
use a higher number if needed. After running the above, launch PyPhoto's
source code as usual:
You can read much more about this Pillow issue in thumbspage's forked version
of the viewer_thumbs.py module, available
here.
That module uses a code workaround that makes the ulimit fix above
unnecessary, supports arbitrarily large folders everywhere, and may find its way
into a future PyPhoto (the trick is to take manual control of file opens and closes).
Given the obscurity of both the bug and use of PyPhoto's source code in general
(even its author had to scrounge for details...), this is a low-priority item.
Update: PyPhoto eventually incorporated
the thumbspage workaround too, in its 2.2 release that was included in PyGadgets'
September 2018 rerelease. This means that PyPhoto, like thumbspage, is immune to
the Pillow file-close bug. There's more on the PyPhoto patch release
above.
This tip comes from
showcode—a CGI
script that loads files by trying candidate Unicode encodings in a list,
and is used in conjunction with an Apache rewrite rule to display this
site's code and other text files in HTML pages. showcode doesn't belong
to the apps category, but this note's principles are widely applicable.
Notably, they also touch on both genhtml,
which uses a similar Unicode-choices scheme, and PyEdit,
which relies on user inputs and defaults to correctly open and save files.
Coders and users of any such system may find relevance here.
Short story:
when using the showcode script, a site's displayable text files should
generally all use a common Unicode encoding type for reliable display
(e.g., UTF-8, which handles all text, and is the preset first candidate).
Else, it's possible that some files may be loaded per an incorrect encoding
if their data passes under other schemes. This is especially possible if
files use several incompatible 8-bit encoding schemes: the first on the
encodings list that successfully loads the data will win, and may munge
some characters in the process.
The Issue
This issue cropped up in an older
file
at this site created with the CP-1252
(a.k.a. Windows-1252) encoding on Windows, whose tools have a nasty habit
of silently using its native encodings. This file's slanted quotes failed
to display correctly in showcode because Python happily loads the file as
Latin-1 (a.k.a. ISO-8859-1), despite its non-Latin-1 quotes. The loaded
text encodes as UTF-8 for transmission, but decodes with junk bytes.
Here's the story in code. Python does not allow the character “
to be encoded as Latin-1, in either manual method calls or implicit
file-object writes. This is as it should be: the quote's 0x201c
Unicode code point maps to and from byte value 0x93 in Windows'
CP-1252, but is not defined in Latin-1's 8-bit-oriented character set:
>>> c = '“' # run in Python 3.X
>>> hex(ord(c)) # same in 2.X (using u'“', codecs.open(), print)
'0x201c'
>>> c.encode('cp1252') # valid in CP-1252, but not Latin-1
b'\x93'
>>> c.encode('latin1')
UnicodeEncodeError: 'latin-1' codec can't encode character '\u201c' in position 0: ordinal not in range(256)
>>> n = open('temp', 'w', encoding='cp1252').write(c)
>>> n = open('temp', 'w', encoding='latin1').write(c)
UnicodeEncodeError: 'latin-1' codec can't encode character '\u201c' in position 0: ordinal not in range(256)
Conversely, decoding this character's CP-1252 byte to Latin-1 works
both in manual method calls and file-object reads. This is presumably
because byte value 0x93 maps to an obscure and unprintable
"STS" C1 control character in some Latin-1 definitions, though the decoder may
simply allow any 8-bit value to pass. It's not a CP-1252 quote in any event:
>>> b = b'\x93'
>>> b.decode('cp1252') # the proper translation
'“'
>>> b.decode('latin1') # but it's not a quote in latin1
'\x93'
>>> n = open('temp', 'wb').write(b)
>>> open('temp', encoding='cp1252').read()
'“'
>>> open('temp', encoding='latin1').read() # <= what showcode did
'\x93'
This is problematic in showcode, because this script relies on encoding failures
to find one that matches the data and translates its content to code points
correctly. Because a CP-1252 file loads without error as Latin-1, its UTF-8
encoding for reply transmission is erroneous; the quote's code point never
makes the cut:
The net effect turns the quote into a garbage byte that browsers simply
ignore (it's an odd box in Firefox's view-source, but is otherwise hidden).
The Fix
If your non-UTF-8 files are only CP-1252, replacing Latin-1 with CP-1252
in the encodings list fixes the issue. However, if your site's files
use multiple encodings whose byte ranges overlap but map to different
characters, using CP-1252 may fix some files but break others. Latin-1
files using the 0x93 control code, for example, would sprout
quotes when displayed (unlikely, but true). The real issue here is that
content of mixed encodings is inherently ambiguous in the Unicode model.
The better solution is to make sure your site's displayable text files
don't use incompatible encoding schemes. At showcode's site, the simplest
fix was to adopt UTF-8 as the site-wide encoding, by opening its handful of
CP-1252 files as CP-1252, and saving as UTF-8. The set of suspect files
can be easily isolated by trying UTF-8 opens (in a variation of other code
on this page):
>>> import os
>>> textexts = ('.html', '.htm', '.py', '.pyw', '.txt')
>>> for (dirhere, subshere, fileshere) in os.walk('/Websites/path'):
... for filename in fileshere:
... if filename.endswith(textexts): # or mimetypes
... pathname = os.path.join(dirhere, filename)
... try:
... x = open(pathname, mode='r', encoding='utf8').read()
... except:
... print('Failed:', pathname)
Converting to UTF-8 universally will not only help avoid corrupted text
in showcode, it might also avoid issues in text editors
that are given or guess encoding types.
If you give the wrong encoding to an editor, saves may corrupt your data.
If you expect a tool to deal with mixed encoding types, guessing may be
its only recourse. But guessing is overkill; is impossible to do accurately
anyhow; and is not science. Skip the drama and convert your files.
We can't fix Unicode's built-in ambiguity, but we can take it out of the game.
Because mixed encodings are such a common concern, you'll find ample
background on the web. As a sampler:
learn about encoding guesses
here;
read more about the Latin-1 encoding
here and
here;
and dig deeper into the politically charged Latin-1/CP-1252 encoding mess
here and
here.
Update:
in light of the above, 'latin1' was eventually replaced by
'cp1252' in showcode's preset input-encodings list, to accommodate
a few files at this site that are intentionally not UTF-8 (this is similar
in spirit to the policies for parsing web pages in
HTML5).
CP-1252 is a superset of Latin-1 and should work more broadly, but change as
needed for your site's files. This is still only a partial solution for
mixed-content ambiguity; use a common Unicode type to avoid encoding
mismatches altogether.
Footnote: Latin-1 Pass-Through (genhtml)
Subtly, some scripts, including this site's
genhtml page builder,
can often get away with treating CP-1252 files as Latin-1 files, because
bytes whose interpretations differ between the two are passed through
unchanged from load to save:
>>> c = '“'
>>> n = open('temp', 'w', encoding='cp1252').write(c) # save as cp1252
>>> open('temp', 'r', encoding='cp1252').read()
'“'
>>> L = open('temp', 'r', encoding='latin1').read() # load as Latin-1
>>> L
'\x93'
>>> n = open('temp', 'w', encoding='latin1').write(L) # save as Latin-1
>>> open('temp', 'r', encoding='cp1252').read() # retains CP-1252 quote
'“'
>>> open('temp', 'rb').read() # 0x93's meaning varies
b'\x93'
In other words, what Latin-1 reads and writes as 0x93 is still
“ to CP-1252. This means that 'latin1' generally works
as well as 'cp1252' and other 8-bit encodings in genhtml and other
pass-through contexts. In fact, it's tempting to think of Latin-1 files as bytes
files, because their encoded values are also code-point values for the
characters Latin-1 supports:
>>> x = 'Ä'
>>> ord(x) # Ä is code point 196
196
>>> x.encode('latin1') # a non-ASCII byte
b'\xc4'
>>> x.encode('latin1')[0] # Latin-1 encoded bytes == code points
196
>>> chr(196)
'Ä'
But this analogy doesn't quite survive contact with Unicode reality.
For one thing, Latin-1 can't decode text encoded outside its 8-bit
range—whether the text's characters are in the Latin-1 alphabet or not:
Latin-1 characters
>>> x = 'Ä'
>>> x.encode('utf8'), x.encode('utf16') # Latin-1 can't load these
(b'\xc3\x84', b'\xff\xfe\xc4\x00')
>>> x.encode('latin1').decode('latin1') # file save, file load
'Ä'
>>> x.encode('utf8').decode('latin1') # not an 8-bit encoding
'Ã\x84'
Non-Latin-1 characters
>>> c = '⻨'
>>> hex(ord(c)) # code point is > 8 bits
'0x2ee8'
>>> c.encode('utf8') # encoding is > 8 bits
b'\xe2\xbb\xa8'
>>> c.encode('utf8').decode('utf8') # Latin-1 can't encode or decode
'⻨'
>>> c.encode('utf8').decode('latin1')
'⻨'
For another, even in the limited 8-bit world, Latin-1's results will
fail to match text outside its character set (this was ultimately to
blame for showcode's missing quotes):
Load/save pass-through works
>>> '“'.encode('cp1252').decode('latin1').encode('latin1').decode('cp1252')
'“'
But comparisons may not
>>> '“'.encode('cp1252').decode('latin1') == '“' # cp1252's meaning is lost
False
Though only for non-Latin-1 code points
>>> for char in 'xē':
... print(char.encode('cp1252').decode('cp1252') == char, # load as cp1252
... char.encode('cp1252').decode('latin1') == char) # load as latin1
...
True True
True True
True False
In the end, Latin-1's pass-through behavior is a mixed bag:
It does make Latin-1 interchangeable with CP-1252 in
genhtml, but only if its decoding
results need not compare with text outside its character set
(like “).
It doesn't help in showcode
at all, because data loaded as Latin-1 is not written again as Latin-1;
encoding as UTF-8 in the reply makes the text munging permanent.
It does redeem inadvertent Latin-1 Open/Save combos of CP-1252 files in the
PyEdit text editor (no data is lost), but files
must still be opened with CP-1252 to display slanted quotes and other
non-Latin-1 text properly.
Using the correct encoding—and preferably just one encoding—is
still the safest bet.
Footnote: Bytes Mode May Suffice Too (ip-anon)
It's worth adding that, in some use cases, it's also possible to sidestep
encoding dilemmas altogether by processing files in bytes (not text) mode.
This works if the use case does not need to support text matches for arbitrary
Unicode keys (genhtml does), and does not need to
handle and communicate encodings explicitly for proper display in a web browser
(showcode does).
For example, a script that needs to replace an all-ASCII string of bytes in
mixed-encoding files can generally get by with bytes-mode files and ASCII
text comparisons, as long as the ASCII search string is stored as one ASCII
byte per character in all files. This scheme won't work if any UTF-16 files
are lurking about (their encoded ASCII text is not simple
bytes), but will
suffice for mixes of UTF-8, Latin-1, and others.
For one such tactical script that works this way, see
ip-anon.py.
By using bytes mode, this script manages to update nearly arbitrary Unicode files
while remaining fully encoding agnostic. Any CP-1252 “ characters
in the files, for example, are simply more bytes to be blindly copied.
Caution: multiple-line bytes strings in this scheme should use the end-line
sequence (\n or \r\n) of the file they are matched
against; else matching may fail, or files may wind up with mixed end-lines
that may trip up some programs. ip-anon is careful to mind this, but multiple-line
bytes literals embed \n per Python convention sans tweaks.
Footnote: Encoding Guesses, If You Must (chardet)
It's also worth noting that accurately guessing encoding from text content is
impossible
(and not advised in contexts where declarations or standards are available),
but the third-party chardet Python library described
here
may assist in use cases that have no other recourse. It's unknown how
well this library may address the Latin-1/CP-1252 “ confusion.
But don't quote me on that. (Hey, I had to get a pun on this page somewhere...)
The Mergeall incremental-backup and content-propagation
program has recently been tested on Android devices, as a possible way to simplify
synchronization of onboard content copies. Merges between the external SD card and
a connected USB flashdrive, for example, might make it unnecessary to pop the SD card
in and out of the phone. Results so far have been illuminating but mixed—and
in the end, exemplary of the designed-in limitations of mobile devices in general.
The Good News
Although Mergeall's
GUI
cannot be used on Android, both its interactive-console and command-line-script
usage modes run as
advertised on that platform, and without any code changes. For example, the console mode
can be used in the QPython3 app, and the command-line mode can be run in the Termux app
after installing its Python package (these apps currently run source code with Python
3.2 and 3.6, respectively; QPython also offers a 2.X option). Mergeall's GUI mode
won't work, because it is based on the Tk desktop GUI toolkit which has yet to be
ported to Android. The underlying Mergeall script which its GUI launches, however,
can be used directly anywhere that Python runs—an advantage of decoupled
program architecture.
The Bad News
While Mergeall's console and command-line modes on Android can correctly
read and compare files on both SD cards and USB flashdrives (using their
/storage/xxxx-xxxx access paths on devices tested), these modes
still cannot change content on either type of device. This unfortunately
makes Mergeall mostly useless on Android: its comparison phase works well,
but its resolution phase fails to update any files, and produces an error message
for each change attempted. In other words, Mergeall is currently a
comparison-only tool on Android; it cannot be used to update archives
on SD cards or USB drives for changes.
The Android Showstopper
The update failures stem from Android's convoluted and wildly proprietary
permissions model, which does not directly support the paradigm of general
command-line scripts. In short, apps—including those that execute
text-file scripts—run a sandbox, which by design restricts access
to writeable media in ways that vary per Android version, and may involve
dedicated folders, app manifests, Java-oriented code to trigger permission
dialogs, and unique APIs and filesystem requirements for USB drives.
Some Android file explorer apps use these measures to support updates to SD and
USB media. For a cross-platform file-processing program like Mergeall, though,
such constraints are crippling, if not lethal. Android may be based on Linux
(really, SELinux),
but it's been gutted of much of the Linux development experience, and most
of its open-access philosophy.
The Android Workaround
Because the permissions and access code required by Android is too custom to
integrate into Mergeall without substantial changes, users of both systems
today are encouraged to employ an Android device with a removable SD card.
When it's time to synchronize either to or from your phone's content copy,
simply pop the card out and merge on a real computer; any Mac OS,
Windows, or true Linux device will do.
It's not impossible that a future Mergeall could support use on Android
directly. The program already has some unique code for each desktop
platform,
though none impose third-party dependencies as Android would (a port
would minimally require a Python-to-Java interface for permissions, and
may necessitate a complete and custom Android app). As it stands,
however, the only conceived use case does not justify the effort.
It's worth noting that this post pertains to devices as they are shipped.
"Rooting" (a.k.a. "jailbreaking") yours may open up additional
Mergeall prospects. This option was not tested, because rooting is
not possible for every user and device, and is strongly and even
actively discouraged by most hardware and software vendors—which
brings us to this post's conclusion.
Mergeall issues aside, it's difficult to recommend mobile platforms for
content storage in general. The net effect of Android's proprietary permissions
model both limits device scope and locks down user options—outcomes surely
much more in line with the goals of multiple revenue-seeking parties, than those
of device owners. This is hardly a basis for trust in a data-storage relationship.
Nor is Android the only rustler in the mobile corral. iOS is even more
closed, with no general-purpose filesystem or removable media to be found,
and a complete lockout of software outside the company
store.
This is about as proprietary as a computer system can be (and would almost
certainly have raised government eyebrows in decades past).
As a result of both of these systems' practices and dominance, mobile
users are compelled to choose between one platform seemingly designed to
reap advertising data and boost cloud subscriptions, and another ostensibly
crafted to trap users' media and coerce brand dependency. These may not be
the best places to keep your cherished photos and personal documents.
But it doesn't have to be this way. Today's mobile options are far too
pervasive and powerful to justify user-experience constraints.
In a world where computing-device companies truly have their customers' best
interests at heart, interoperability would take a back seat only to privacy.
Let's hope that world shows up soon.
Updates
This note's original content above reflects an initial encounter
with mobile operating systems in general, and Android in particular
(iOS is too closed to qualify for PC-level roles). It's being amended
here as smartphones evolve and new information dribbles in. Here's
the ongoing story, from oldest postscript to newest:
Per January 2019's
next section, an approach for running
Mergeall on Android using Termux command lines (or a Pydroid 3 tkinter GUI)
was eventually discovered—though removable-drive content must be nested oddly
and may be deleted automatically; an Android timestamps bug means that
syncs don't work at all until Oreo; a Samsung Android exFAT timestamps bug means
that Mergeall removable content should be stored on FAT32 drives
until Android 10;
and the solution comes with so many requirements that you may still
prefer to yank out your SD card. While they last...
In March 2019, it
looks like Android Q (a.k.a. 10), its next version, may further lock down the
platform by restricting access to internal (unremovable) storage.
This version is still in beta and its final policies are unknown.
Given the track record of mobile operating systems, though,
expecting the worst qualifies as common sense. For more details,
see the
overview.
See also the Jan-2021 update ahead; this was later deferred to Android 11,
which both imposed its "scoped storage" rules on internal storage,
and extended the new constraints to removable drives in general.
In late 2019, iOS 13 added support for content on
USB drives,
and a filesystem of sorts accessible from the stock Files app only (though
apps can make use of the Files framework).
This isn't nearly the same as the general-purpose storage available
on PCs, though, and the store-only lockdown for apps remains in place.
Android's storage has historically been more flexible
too, but it's also been historically prone to
change, and now seems headed towards a restrictive model in Android 11
which is strikingly
similar.
The iOS App-store collar is getting tighter.
You've probably already heard about Apple removing Epic's popular
Fortnite game from the App store in 2020 for not abiding by all its
commission rules, but it merits a link
here.
Hey Apple—your greed is showing!
As of January 2021, Android 11 (f.k.a. R) is now known to have revoked
general USB-drive access for POSIX programs, radically throttled down programs
that process files in shared storage, introduced new program glitches, and
hobbled content-processing apps with constricted permissions. It's about as bad
as expected; read the summary
ahead,
and the full chronicles on the
Android 11 updates page.
As of early 2022, Android 12 has silently added a "phantom" process killer,
which starts terminating child processes at arbitrary points once 32
such processes exist across all apps. This is a nightmare scenario for
many developers. It basically shuts down nontrivial software, and may
signal the end of Python and other POSIX tools on this platform.
There is a work-around today, but it's not in scope for normal users,
and doesn't reverse the damage.
For the full story, tap
here
and
here.
Android 13 also tried to lock down app-specific storage this year,
but largely failed.
As of May 2023, the new all-Python
PC-Phone USB Sync app
manages to both workaround USB and shared-storage lockdowns on
Android
11+, and run portably on all
PCs.
On Android, it uses the All-Files-Access
permission available in standalone apps. This enables it to process content
with POSIX file-path code that works across platforms, instead of Android's
proprietary APIs that work nowhere else.
The net effect combines Mergeall portability with a new GUI
that supports the Android app.
More info
here and in the Note
here.
This app works well today, but is constrained by Android 11+ storage-speed
regressions,
must placate Google Play-store
restrictions,
and is naturally
dependent on the whims of a cloud-focused company which has historically
denigrated removable storage and is prone to change the rules every year.
Time will tell what the next update here may bring. But happy endings seem
a longshot in a domain dominated by two enormously wealthy companies focused
on media lockdown, advertising, and exploitation of naive masses.
Improve, please.
Per later research, it turns out that
permissions were not the real showstopper on Android. Until 2017's Oreo
(version 8), Android had a bug that made it impossible to copy file modification
timestamps on non-rooted phones: file content copied correctly, but all files would
be stamped with the time that the copy was made. This rendered content-sync programs
like Mergeallcompletely unusable on Androids 7 (Nougat) and earlier. That is,
Mergeall could not be used for much of Android's tenure, permissions or not,
and it remains unusable for many Android users with older phones today.
The upside is that this bug has finally been fixed as of Oreo (in brief, by
replacing a FUSE-based scheme with Samsung's
SDCardFS). This fix,
together with a permissions-granting
tool added to the
Termux command-line app, means that Mergeall can now be used on Android
to synchronize on-phone content with a USB drive — if you are willing and able to:
Run Android 8 or later
Format removable drives as FAT32 for best interoperability (till Samsung Android 10)
Use command lines in the Termux app or fledgling tkinter support in Pydroid 3's IDE
Grant Termux or Pydroid 3 extra updates permission
Nest your content in app-specific folders on removable (a.k.a. external)
drives to which you plan to sync changes on your phone, and beware automatic
deletions on app uninstalls. This content nesting may also
be required for internal storage as of
Android Q
(which was later renamed 10, around the time the change was deferred to 11).
See the new how-to guide
for full details, as well as a set of precoded helper-scripts that simplify
Mergeall command lines for smartphone use, and a brief look at the tkinter
GUI runner-up alternative. Neither command lines nor the GUI come without
drawbacks, but they do work without rooting your device or pulling your SD card.
It's not impossible that a standalone Mergeall app may someday make command
lines, IDEs, and content nesting unnecessary, but the Android Oreo+ requirement
would still be firm, and FAT32 would remain recommended for removable-drive content
until Samsung's exFAT fix in Android 10.
The Mergeall-on-Android thread of the last two notes has grown
radically in scope: there is now a provisional guide for using the
tkinter GUIs of Mergeall, Frigcal, PyEdit, PyGadgets, and PP4E book
examples on Android devices, by running them in the Pydroid 3 app's IDE.
View the guide
online here.
This guide is marked as provisional because debugging on
Android tkinter is ongoing, required code changes have not yet been
merged into base source-code packages, and development of standalone
apps for some of these programs is a long-range possibility. Still,
you can use these programs on your Android smartphone today with just
a few steps outlined in the guide (and tolerance of a few
glitches
and freemium
advertising
in the hosting app).
Due to the initial unpacking required by PyInstaller single-file executables,
app startups can be relatively slow on Windows, especially if
your system disk is a hard drive. PyInstaller is also used to build
Linux executables, but that platform's fast file access generally
makes it immune to this issue (though a given device's speed may
naturally vary).
This known issue is described in
full in the apps' READMEs.
It doesn't impact source-code package; isn't a factor for Mac OS apps,
because they are bundled as source code plus a Python; and is a minor concern
for most apps because startups are one-time events. It can be a substantial
negative for PyEdit, though, and more so if you've
associated text files to open it on clicks; 5-10 second waits have been seen
on older machines, and that's too long by today's standards.
For best results on Windows, either:
Run frozen apps on systems using faster SSDs to minimize the startup delay
Fetch and run the source-code versions of impacted apps, after installing
a Python if needed
As an example, PyEdit opens can be as fast as 2 seconds on one 2020 PC with SSD
under Windows 10, though your speed may vary, and you may still find this slow.
Start-up speed on the same device is the same for executable and source code
under Linux.
If you opt to instead go with source code on Windows, you can still open PyEdit
by clicking it, and may still be able to associate PyEdit to open text files
clicked with the provided pyedit.bat; for more details, see the
PyEdit user guide
here and
here.
Of course, you can also open PyEdit just once, and open each file with its
Open
menu/toolbar/shortcut command (in a new
Popup window if desired);
but that may seem less direct than text-file clicks to users accustomed to some
platforms' GUI paradigms.
Update:
Per testing in late 2020, it now appears that Linux frozen executables open just
as fast as their source-code versions, especially when loaded from an SSD on recently
released computers. This is also true when opening programs by file clicks on Linux,
using the new usage tips available
here.
Hence, this note applies mostly just to Windows today,
and has been updated accordingly; program READMEs may still count Linux
in the slow-start category.
On Mac OS, programs which use the Tk toolkit—like the apps at this
site—sometimes
produce a very small (and very weird) vertical line in the upper-left corner of the display,
like this. Though
formerly assumed to be a screen artifact, this now appears to be related to a default
and automatic Tk console window: "console" sometimes shows up in App Exposé displays,
and clicking on the line opens a half-operational
window in which typing an
exit command (when possible) closes both the window and the odd line.
These findings are still preliminary, but this console seems broken, and its appearance
seems to be a bug. The line appears sporadically; clicking it produces a window that is
incomplete and
inoperative
until it's minimized and restored; neither the line nor the
window was requested by code; and this is the sort of glitch that tends to be
Tk-version specific on Mac OS. So far, this has been observed only for the Tk 8.5
frozen into this site's apps, though its full scope is unclear.
If the odd little line is also too distracting to ignore: click, minimize/restore, and
exit to kill the "artifact" if and when it appears, until this can
be explored more fully and resolved in the context of app rereleases.
Short story: first-run warnings are just as intimidating as ever on Mac OS,
but you can still freely run trusted independent apps like those at this
site after
an initial right-click Open (and new permissions steps covered in the
next note).
Details
This note is an update to 2017's coverage,
with expanded details for Mac OS app users.
As of early 2020, you can still run this site's "unblessed" apps on Mac OS
Catalina, despite both the misinformation about this going away,
and the stupidly scary messages that now pop up on some first
opens.
With a modest one-time effort—and a healthy distrust of authority—independent
apps available outside the Apple store, including those at this site,
are still fully usable on Mac OS today.
This story has grown more convoluted with recent notarization requirements,
which are not important to cover here.
For more details, and proposed work-arounds,
click the warning's ?button,
read Apple's own
docs,
or wander the results of web searches like
this.
Among the advice: a sudo spctl --master-disable in Terminal may loosen
Gatekeeper's shackles in
full,
but it's potentially dangerous, and probably overkill in this context.
The easiest way to launch apps that trigger first-run warnings is still this:
Use a two-finger (or right or control) click of the app's icon in Finder to
open a menu
In this menu, click Open to produce a marginally friendlier
message
In this message, click Open to clear the app to always immediately
run
You only have to do this once per app, and only for apps that trigger the nasty warnings
when first run; once approved this way, an app opens normally on every later run.
As a slightly more involved alternative, the Security & Privacy preferences
screen
still gives you an option to open a denied app for "about an hour" (that's apparently
how long you're allowed to agonize over how to use your own computer).
Curiously, you may also have to clear other apps fetched outside the Apple Mac App Store
today—even those of other tech
Goliaths.
A trend to be sure, but its intent is unknown. Mac OS could, of course, eventually
move to a full store-only approach like Windows 10 S—and Apple's own
iOS—but
that would drive far too many developers and users away from this open Unix platform
to ever happen.
Right?
Update:
this plot has regrettably thickened—see also the following notes about
app-quarantine states in Sierra;
root-folder lockout in Catalina;
and other opinion-based changes in Mac OS that break independent apps
(and strain developer loyalty). The bad news: after opening an
app, you may still need to ensure that it has permission to use its own
folder. The good news: two techniques outlined in the next note
(alternative zips and quarantine removals) may also avoid first-run warnings.
The related news: Google's just as
bad.
Update:
and more hits from the same genre—the
disturbing scene
on Mac OS Catalina, when trying to print with an HP driver that
has been used without issue for years. There's no "may" or "might"
here; just a misleading and stark warning that a trusted driver
"will damage your computer." Honestly, Apple, this stuff is
out of control; what's your problem?
Please stop keeping us safe from developers who do not pay
you a commission.
Short story: in Mac OS Sierra (10.12) and later, you may need to
explicitly grant apps downloaded from the general Internet permission to write
to their own folders. Else, some apps—including the PyMailGUI, Frigcal, and PyEdit apps
available at this site—may
either be unable to provide some utility, or fail to
launch altogether. You can grant own-folder permission by simply
unzipping and moving apps to another folder with Finder; unzipping apps with
a different zip tool; or running a "nuclear-option" xattr command
in Terminal to clear the stigma of quarantine for trusted independent apps.
The Damage
This preceding
note covered the requirement to give unsigned apps like
those at this site permission to open on Macs.
As it turns out, the proprietary-lockdown story in Mac OS (recently rebranded yet again,
as macOS) is broader than formerly told: beginning with Sierra, Mac OS also runs apps
downloaded outside Apple's Mac App Store in a read-only working directory, with a
randomized path name—like
this one. This creates a
kind of app purgatory, which limits apps' utility; combined with intimidating
first-run
warnings,
Mac OS is now clearly discriminating against non-store apps.
This change is generally known as Gatekeeper path randomization, though the
terser "translocation" seems to have risen to the fore too. This page doesn't
have space to cover it in full, but you can read more about it on the web
here,
and try searches
here and
here.
In brief, the change's rationale was a
security issue that seems wildly obscure, but its fruit is widespread
breakages
for non-store apps, which can both deprive users of helpful programs, and appear to
developers as an ominous and coercive move towards iOS's pay-and-conform-or-else
model.
In truth, Apple's store-only mandate in iOS would be disastrous for an open Unix desktop
platform like Mac OS; if you cannot run your own apps on your own computer,
what sort of device is it?
We'll put aside the conspiracy theories for
now,
but this change does have tangible consequences today: it can ensnare
and cripple any non-store app that needs to record program state information, including
those that auto-update themselves in place, or don't quite meet the tightening
requirements (even recent Pythons weren't
immune). At this site specifically, three of the
five Mac OS apps available are
substantially broken by the Sierra change:
PyMailGUI
by design uses its own folder to host a self-cleaning
temp folder for saved email parts (e.g., attachments), which must be user accessible
when manual opens are required. Without access to this folder, email part requests
fail with an error-message
popup.
Frigcal
by design uses its own folder to both save a cross-process
sentinel file, and make an initial default calendar on first run (unless configured
otherwise). Without access to this folder, its open fails with
an error-message
popup, and the app cannot run.
PyEdit
by design uses its own folder as the default location for
auto saves (unless configured otherwise). Without access to
this folder, auto saves will not
occur,
and unsaved edits may be lost when PyEdit is closed.
Without user intervention, such apps' own-folder file writes will fail on
permission errors in Sierra and later only, yielding either reduced functionality or
complete unusability.
This site's
Mergeall and PyGadgets
are spared from the carnage, but only because they have no need to write state
information to their own folder (and you'll still get a scary warning when you
first try to run them).
The Fixes
Luckily, the lockdown is still reversible, and the fixes are easy—though oddly
convoluted and weakly documented. To keep this simple, we'll focus only on apps
shipped as zipfiles, like those at this site. For such packages fetched off the web
and outside the Apple store, there are three simple ways to give back own-folder
permissions to unzipped apps, presented here by increasing complexity:
Move the app anywhere
If you've unzipped a downloaded app by Finder click
(which technically runs the Archive Utility
handler),
simply moving the already-unzipped app (e.g., PyMailGUI.app)
to the usual /Applications folder with
Finder is enough to restore its permissions. In fact, using Finder to move the app
anywhere suffices to break the translocation spell and reinstate permissions;
unless apps are run from their unzip location (e.g., Downloads),
this issue may be a moot point. Unfortunately, though, casual browsers may be
naturally inclined to test-drive an app in Downloads and run into problems,
and unzipping in /Applications won't help.
Don't unzip with Finder
You can also avoid translocations altogether by
simply unzipping apps with a tool that doesn't brand the result as suspect.
The
ziptools program at this site, for example, includes an
extract script that does at least as well as Finder clicks. When unzipped with this
script instead of Finder, apps run without permission restrictions anywhere. As a
substantial bonus, they are also not subject to the first-run warnings of the prior
note.
Though not app-specific, ziptools may do better on metadata propagation and time
changes too; see its page.
Delete quarantine attributes
If you're willing to run a command line, you can also restore app permissions with
a simple xattr command to remove the app's quarantine attribute stamped
onto downloads. Like alternative unzips, this also avoids first-run warnings.
Finder, and the tools it spawns, apparently implement their constraints by this
attribute's content, not its presence; it may still be attached to apps that have
been approved and cleared by moves. Forcibly removing the attribute, however,
defeats the new security constraints altogether (and is arguably safer than
globally disabling Gatekeeper).
If you opt to use the last option above, open Terminal, and run the following commands
to remove the quarantine attribute that paralyzes the apps you've downloaded from this site:
Replace the foldername part with the folder in which you've
downloaded and unzipped the apps—for instance, ~/Downloads or
~/Desktop (it can also be /Applications, but these commands
aren't required if you move apps there with Finder after unzipping). If these
commands raise errors, add a sudo at their front and enter your login
password when prompted (or ignore, if apps work okay afterwards anyhow). This
command form can be used to remove the quarantine scourge from other apps too,
by using a different name at the end; try a
man xattr in Terminal for more details.
You can also verify the presence of the attribute before going to the bother of
removing it, with either of the following in Terminal; per the last list
item above, though, a com.apple.quarantine reply doesn't necessarily
mean that the app is still in Mac OS purgatory:
% xattr foldername/PyMailGUI
% ls -l@ foldername/PyMailGUI
After you use one of the three methods above to grant an app permission to write
in its own folder, the app will run forevermore in its true
folder;
without additional
errors;
regardless of where it is located; and just like it did before
Sierra—which brings us to this note's conclusion.
This change went unnoticed because apps on this site were developed and tested
on El Capitan to maximize their forward compatibility, and later usage skirted
it by either post-unzip moves or direct copies from external drives (both of
which skip the drama in full). It also
went unreported by users in some 3 years, so its severity is unclear.
Although some Mac OS Sierra+ users may have gotten lucky with moves, others sadly
may have given up on the apps in silence. Sadder still, some users may have
simply grown accustomed to the added inconveniences of their platform.
This change also probably merits a longer diatribe than this page can
accommodate. For here, it will have to suffice to note that own-folder
lockouts,
along with first-run
warnings,
are clearly antagonistic towards independent developers
most. Indeed, there seems a trend among tech companies in recent years to be
increasingly dismissive of the very people developing
programs and content that support the company's
products.
This is certainly one way to do business, but it's also one way
that products can wane.
In fairness, you should also read Apple's own twisted tale of some of the new
Mac OS security constraints here,
and draw your own conclusions. To independent developers, though, it's impossible
not to view this as something akin to extortion.
If you don't pay Apple's developer fees and conform to its rules, your app will be
disabled, labeled malicious, and almost certainly get fewer users as a result.
What else could that sound like?
Update:
By 2025's macOS Sequoia, translocation grew more aggressive and now may be immune
to the solutions above. Instead, work around it by configuring program resources to
be stored anywhere else than the program's run folder. PyEdit auto saves, for example,
can be restored by a one-line config-file edit covered
here, and Frigcal's calendar files can be
similarly relocated with a simple config
edit.
Short story: in Mac OS Catalina (10.15) and later, you cannot store any user
content in the top-level root folder of your system drive—as
many of the examples for this site's apps do. Store content in your per-user home folder or
elsewhere instead, and update any references to former root-level paths.
Details
Mac OS seems to be growing more locked down with each release: in addition to the
first-run
warnings and own-folder
lockouts
discussed earlier,
starting with Catalina you also can no longer
store your own files or folders at the top-level root (a.k.a. /) of your main
system drive. That is now reserved for Mac OS's own files and is read-only for you; user
content is instead relegated to a special-cased volume.
You can read more about this change and its rationales both in the
Apple overview, and via the usual
searches.
The simple upshot is that your computer's root folder is no longer yours to use;
you'll generally have to store content in your /Users/you
(a.k.a. ~ in shell-speak) folder instead, and deal with the resulting
longer pathnames on every access.
The inconvenience of this naturally depends on your use cases.
Desktop shortcuts and Finder favorites can help, but they don't always apply.
For example, you may also have to change absolute paths from former root-level
folders in symlinks, environment
variables, program configurations, and utility scripts—any one of which may prove
to be a substantial task. Apple seems unlikely to reimburse you for the time, but
scripts like this can help.
It may also be possible to unlock the root with system-level heroics (e.g., try this
forum),
but this is easily complex and perilous enough to qualify as
impractical and preclusive for most users.
In terms of this site, examples provided with its apps broadly use and recommend
the root folder for storage, because it was a useful and sanctioned technique which made
paths shorter and quicker to use in most contexts. Until these apps can be updated and
rereleased, you'll have to pardon and ignore root paths used in such examples; alas,
like many recent Mac OS changes, the new rules create extra work for developers that
is growing increasingly difficult to justify.
Though irrelevant to apps here, Mac OS Catalina also:
Changes the default Terminal shell to
zsh,
breaking an untold amount of code and practice in the
process
(#! bash scripts still work, but other shell dependencies
may not); you can restore bash, but it's extra
effort,
and you still get a nag unless it's explicitly
silenced
Now issues a weirdly forceful uppercase
warning that the Python 2.7 it includes
is not recommended —despite the fact that 2.X still sees regular action,
and no immediately usable Python 3.X replacement is provided
Drops support for 32-bit apps and maroons their users, per the abundant coverage on the
web;
this may not have been a surprise, but it doesn't bode well for other apps' futures
Along with root-folder lockout, such changes may appease the personal preferences
of a regime du jour, but they can have arbitrarily negative impacts on the programs,
tools, and practice of others. In the absence of clear user benefit,
this qualifies as rude.
Perspective
So, for those of you playing along at home... we've now seen first-run warnings,
own-folder lockouts, root-folder shutdowns, and a constrained platform that's becoming
a lot less pleasant to use for all but the naive and imaginary audience to which Mac OS
seems to be pandering. Time will tell if customers savvy enough to appreciate this
platform's advantages will also be forgiving enough to suffer its increasingly
opinion-based
breakages.
Update:
The carnage generated by Mac OS's thrashing is about to get thicker.
In 2020, Apple
announced plans
to abandon Intel chips in favor of its
own, thereby deprecating every program previously compiled for Mac OS.
A translation (really, emulation) tool may keep some existing
programs running for a few more years, albeit slowly. Given the company's
track record in this department, however, all programs built for the Mac OS
platform in recent years (including apps at this site)
are now officially on life support, and those that cannot be rebuilt are
already on death row. Windows doesn't generally cull developers' work
this way; it also dominates the PC
market.
Short story: much as on Mac OS, you have to approve the frozen
Windows executables here the first time they run, because they are not
officially registered with Microsoft. And never shall be.
Details
This note applies to all Windows frozen executables (a.k.a. apps) available
on this site. Much like the Mac OS first-run warnings described earlier on
this page,
Windows 10 will pop up a intentionally scary warning the first time you try to
launch independent programs like those at this site. The authorization
process is simple, though the steps can vary across machines:
If Windows
SmartScreen
is still enabled on your computer, you'll get an initial
screen that looks like this;
whose More info link displays a Run anyway button
like this;
which enables the app to start normally
thereafter.
If you've already turned SmartScreen off (and you probably have, if you
run programs from trusted independent sources), first launches produce a more
useful screen like this;
whose Run button enables normal starts when clicked.
Naturally, these warnings won't appear when running apps' source-code
versions with an installed Python which passes Windows' trustability test.
Also naturally, the same concerns about platform lockdown on Mac OS apply
to Windows 10 too, though the latter's track record of backwards-compatible
support is tangibly better.
That said, Windows has already blatantly flirted with a store-apps-only
paradigm in 10 S,
and the next two notes chronicle glaring
exceptions to Windows backward compatibility—and further call out
a field which seems much more bent on thrashing and control
than legacy support.
Short story: Due to library skew, the 64-bit PyMailGUI executable
may silently crash for secure email accounts on some Windows 10 systems.
Use PyMailGUI's 32-bit executable or its source-code version instead.
Details
Attention PyMailGUI users on Windows 10:
due to an open issue regarding SSL
library skew on your platform, the 64-bit PyMailGUI executable app may
crash without any error message when first connecting to SSL
(secure) email servers. The remedy is to run either the 32-bit
PyMailGUI executable, or run the source-code version of PyMailGUI
with an installed Python. Both of these fixes avoid this issue in
full on systems tested, though the 32-bit app may have simply gotten
lucky after other program installs; use the source if all apps fail.
You can hunt for more details on this glitch in searches like
this.
Though the exact cause remains TBD, the leading theory is that it involves
library support that differs across Windows or Python versions.
Per evidence so far, the crash:
Does not occur for non-SSL email accounts (TLS transfers work fine)
Doesn't happen on earlier Windows versions (Windows 7 and 8 work fine)
Only happens on some Windows 10 systems (it's been seen on a
Windows 10 machine that also installed Python 3.8 only, but not on another
that did not)
Crops up in Python's _ssl.pyd module with
this event log
(this may make libcrypto and libssl libraries of interest)
Watch for more details here if and when they arise.
Whatever the cause, though, the crashes were clearly triggered by a change external
to PyMailGUI. The now-crash-prone PyMailGUI 64-bit app was built on
Windows 7 with Python 3.5, and has been used extensively for many years on
many devices. In theory, it should both run on later versions of Windows,
and be immune to later Python installs. In reality, "should" has a way
of morphing into "doesn't" in both Windows and software in general.
Short story: on Windows 10 (and 11), you'll probably need to deblur Tk/tkinter
GUIs by checking a high-DPI scaling option in executables' Properties dialogs.
For most displays, this is required for all Windows apps (a.k.a. frozen executables)
at this site, as well as Python itself when it is used to run such GUIs in
source-code form.
The Issue
This note applies to all tkinter GUIs on this site when run on Windows 10.
Windows 10 has had issues with blurry GUIs since its inception, and
has still not resolved them in full. This impacts all the Windows
frozen-executable apps at this site,
as well as their source-code versions. For both app and source, GUIs
based on the tkinter library (and its Tk scaffolding) initially display
horribly blurry—almost to the point of unusability.
While not exactly a great first impression, the blurring is an unavoidable
consequence of Windows' choices regarding high-resolution displays that
are out of scope here; in short, an arguably misguided touch-screen dogma
rendered most text and GUIs unreadable. Many programs have worked around
the blurring by now (e.g., most web browsers are sharp today), but some of
Windows' own system dialogs are still munged, and the Tk library undergirding
Python's tkinter is still blurry in the latest Python 3.8/TK 8.6 install.
The Fix
Luckily, a simple though manual fix is now provided by Windows 10
itself. To sharpen tkinter GUIs, you just have to toggle a switch
that controls rendering on high-DPI displays, as follows:
In File Explorer, find and rightclick the executable whose GUI is blurry
In the resulting menu, select Properties
In the resulting dialog, click the
Change high DPI settings button in the Compatibility tab
In the resulting dialog, click (enable) the
Override high DPI scaling behavior checkbox
Retain the Application selection in the Scaling performed by list
For reference, here's what the DPI dialog at step 4
looks like.
After running all the steps above, the result is deblurred and radically
sharper GUI displays—of the sort that were normal before Windows 10's
fuzzy adventure. The fix's before and after for some apps at this site is captured
in screenshots
here,
here, and
here
(which, hopefully, render legibly on your Windows 10 box).
You need to apply this fix just once per program, but you'll want
do this for both:
The main executable of each blurry app (only)
If an app has both a main launcher GUI executable and other
executable GUIs opened by the launcher, you usually need to apply
this to only the launcher, not its launchees. At this site,
for example, PyMailGUI,
Frigcal, and PyGadgets
all come with launcher executables that should be defuzzed; their launchees don't
need the fix unless they are also run directly.
The Python executables for source-code runs
If you opt to install a Python and run the source-code versions of
this site's apps (or any other tkinter GUI, for that matter), you'll
need to apply the fix to the python.exe executable for
typical scripts, as well as its pythonw.exe cousin for
.pyw non-console scripts; both of these executables are
located in the Python install folder. This will have the effect of
deblurring all tkinter GUIs run by the fixed Python as source code.
There are other ways to fix the blurring, some of which predate the
Windows 10 option above, but we'll omit them here for space.
To dig deeper, see the searches
here and
here,
as well as the coverage
in PyEdit's User Guide
here;
to date, a fix was apparently applied to the Python's IDLE GUI around 3.6,
but not to Python itself, which leaves all users' GUIs fuzzed.
Also note that
some systems with lower-resolution displays may be spared from all
this muck. Users of older versions of Windows are also immune, just
because your system hails from a more gilded age which predates what
can only be characterized as a horrendous defect that still eludes
Microsoft's full attention years after its inception (and if we
had a nickel for every time... ah,
never mind).
Update:
As of 2024, some of this site's tkinter programs have started automatically
deblurring themselves on Windows, using Windows-specific tools that apply to both
frozen-executable and source-code launches:
from ctypes import windll, c_int64
windll.user32.SetProcessDpiAwarenessContext(c_int64(-4)) # per monitor aware v2
For more info, see the latest releases of
Frigcal and
PyEdit and the usual web
searches. The manual fix above is still needed for other tkinter GUIs on Windows, even
with the latest Tk library.
Short story:
On recent Windows 10 systems, python.org's installers for Python 3.6 and
later include an option to automatically remove the Windows platform's former path-length
limit. Mergeall and ziptools instead use a manual but more-inclusive technique to lift
the limit for users of all Pythons and all Windows. Though useful, the Python 3.6+
enhancement doesn't apply to users of Windows 7 and 8, Pythons 2.X through 3.5,
or frozen executables.
Details
As of Python 3.6 and on recent Windows 10 versions, if you install Python
using the standard python.org
installers,
the last screen will offer to remove the draconian path-length limit
formerly imposed by Windows, like this.
This option won't appear if you've manually enabled the override with
registry settings or otherwise; where available, though, this is a useful
and convenient way to break the former 260-character constraint for
scripts run by the installed Python.
By contrast, this site's
Mergeall and ziptools
programs instead lift the path-length limits by using manual coding techniques described
here and
here,
which work for all Pythons and all Windows.
While the new Python 3.6+ option is a welcome addition, it's important
to remember that it doesn't apply to and won't help users:
Of any older version of Python—including Pythons 3.1
through 3.5, and all Python 2.X
Of any older version of Windows—including Windows 7 and 8
Of Python 3.6+ who don't notice or choose the weakly publicized
and easy-to-miss install option
Of Windows 10 systems that have managed to evade auto-updates since
the path-expanding release
Of frozen executables that mute the install option
by embedding their own Python—including Mergeall
The first two bullets in this list in particular describe substantial
audiences, which wouldn't be served by requiring programs
to be used only on the latest Python and Windows 10.
Despite the PR, a few years doesn't imply obsolescence
for most users, and software that mandates the latest and greatest
when it doesn't have to can be fairly accused of being exclusionary.
Hence, while the manual fix adopted by Mergeall and ziptools may seem
redundant to the subset of users running source-code programs with
Python 3.6+ on up-to-date Windows 10 installs, it still applies to the very large
audience of everyone else, and will remain in place... at least until
the software world stumbles onto a way to fully erase a pesky past which
prevents it from wholly ignoring and negating decades of prior art.
Happily, that day seems more distant with each new set of glitches added
by mandatory updates on machines near you.
File modification times (modtimes for short) are required for fast change
detection in the Mergeall content backup/propagation
system. On Linux, the modtimes on external USB drives that
you use as your Mergeall FROM or TO may pose problems, depending on both
the filesystems your drives use, and the way your Linux is configured.
In short, as of late 2020:
Modtimes on the exFAT filesystem still have major issues on Linux that make them largely
unusable for Mergeall
Modtimes on the FAT32 filesystem work correctly on Linux, but may need some obscure help
to overcome Linux breakages
These limitations are unique to Linux, and do not exist on Mac OS, Windows, or most
Androids.
Moreover, these two filesystems are generally your only free options for drives that
will be used interoperably across a device mix that may include arbitrary PCs
and smartphones. Sans third-party extensions, Mac OS doesn't write Windows' NTFS,
and other filesystems like Linux's Ext4 and Mac OS's HFS+ and APFS are not
supported universally.
This note presents the highlights of the exFAT and FAT32 stories on Linux today.
Its findings reflect testing on Ubuntu 20.04 LTS in December 2020, and are
prone (and even likely) to change in the future. For current Linux Mergeall users,
though, the present status of interoperable filesystems matters.
exFAT on Linux: Broken Both Ways
Update: per the links ahead, the one-month-off exFAT bug was fixed in later
Linux kernels (and Ubuntu releases by proxy). Verify on your system, and
upgrade your Linux as needed to use exFAT; it's a much nicer
drive-interoperability solution than FAT32, and its kernel support
should be showing up in some Androids too.
As of this writing, the exFAT filesystem has been open sourced, and added
to Linux proper.
Because Ubuntu 20 incorporates the Linux kernel in which the exFAT support
was added, there are two different ways to drive exFAT on this platform:
with the new support in the
kernel
(version 5.4),
or the older third-party package
exfat-fuse
(version 1.3.0-1).
To test both, you can switch between the two in Terminal like this:
$ sudo apt remove exfat-fuse # fall back on kernel support
$ sudo apt install exfat-fuse # reinstate third-party support
Unfortunately, neither option gets exFAT modtimes right today.
When mounting an exFAT USB drive in the PST time zone (which is
-8 hours from UTC) on a dual-boot Linux install:
The third-party exfat-fuse always gives modtimes
16 hours ahead of their correct times elsewhere
The new kernel support always gives modtimes
1 month plus 8 hours ahead of their correct times elsewhere
No, really. These stunningly bad results were verified on a second exFAT drive;
both the Nautilus (a.k.a. Files) GUI and Terminal ls commands give
the same times; drives were ejected and the system restarted between readings;
and the commands used to help FAT32 in the next section had no effect.
Something is clearly amiss with exFAT on Linux.
While both exFAT driver options botch modtimes consistently, exfat-fuse
is less wrong, and the way it's wrong is curiously similar to
an earlier exFAT bug on Samsung Android, which was reported and
eventually fixed per the
chronicle here.
For its part, the kernel alternative may additionally harbor a
nasty bug that can incorrectly and silently increment months
by one;
in fact, this is so bad that it may damage your data, and probably shouldn't
be used until repaired.
In sum, unless you manage to find and install a better exFAT implementation,
or change either internal- or external-drive modtimes to agree with their
counterpart, exFAT is unusable for Mergeall on Linux today.
This undoubtedly reflects Linux's historical and long-standing aversion to exFAT's
former intellectual-property constraints, and may naturally improve in the future;
to check in on the current status of exFAT on Linux, watch
the web.
One manual but usable work-around worth noting here: even if there is no time-adjustment mount
option for your exFAT driver, you can still use an exFAT drive for Mergeall on Linux today if you're
willing to temporarily adjust modtimes of all the files on either your internal or exFAT drive
to match. Where acceptable, simple command lines like the following run fast and will
generally do the job, though your paths may vary:
# See how many numhours you need to -add or -sub (it's 16 for my drives)
$ ls -l /media/me/drivename/MY-STUFF/.../unchangedfile /home/me/MY-STUFF/.../unchangedfile# Adjust internal times to match exFAT drive, for syncing to/from the drive
$ python3 .../mergeall/fix-fat-dst-modtimes.py /home/me/MY-STUFF -add numhours# Run Mergeall's GUI or command lines anywhere on this device to sync
$ python3 ..../mergeall/launch-mergeall-GUI.pyw & # for example
# Restore internal times to their original and real values
$ python3 .../mergeall/fix-fat-dst-modtimes.py /home/me/MY-STUFF -sub numhours# Or: run the fixer script on the exFAT drive at /media.me/drivename, and -sub then -add
This scheme uses a script provided for FAT32 DST adjustment by Mergeall, and available
in its package.
As used here, the script changes modtimes (only) on one of the drives before and after a sync,
so they are temporarily comparable with the other drive. As usual, be sure to allow for +/-
one hour on FAT32 if DST has rolled over (and do so as soon as possible to minimize
stragglers changed in the new phase).
FAT32 on Linux: Correct with Help
Since correct modtimes are essential for Mergeall, exFAT's defects outlined in the
prior section likely leave FAT32 as your current best option for drives used in a
platform mix that includes Linux on PCs. You'll have to live with FAT32's 4G
file-size
limit,
and address its DST-rollover
issue (e.g., by running
a simple script like this
twice a year to keep modtimes in sync with other filesystems),
but your content will be usable on nearly every device with a USB port.
That being said, this comes with a fairly large caveat: while FAT32 external drives
can register modtimes correctly on Linux, they may need some help to do so. If your
FAT32 modtimes are initially askew, it may help to turn off Linux's automatic RTC
time adjustment for UTC, with a Terminal command sequence like this:
$ timedatectl set-local-rtc 1 # adopt local times while using FAT32 drive
# Run Mergeall's GUI or command lines anywhere on this device to sync
$ timedatectl set-local-rtc 0 # turn UTC time adjustment back on (maybe)
In testing, such commands did suffice to put a FAT32 drive in sync with the internal
drive on a Linux system.
Specifically, on a stock Ubuntu 20 dual-boot install; again in the PST
(UTC -8) time zone; taking modtime readings in both Nautilus (i.e., Files)
and Terminal; and remounting before each reading, modtimes on a FAT32 USB
drive were:
Initially incorrect by -8 hours compared to all other platforms
Correct after the first timedatectl command above
Still correct after the second timedatectl command above—oddly
In the same tests, files on an exFAT drive were consistently incorrect as described
earlier at all readings. Only FAT32 modtimes were cured on the test machine.
Although this fix works for FAT32, however, it seems at best indirect (if not wholly
coincidental), and may have unintended consequences. The timedatectl
commands are meant only to change the interpretation of the hardware clock shared
with Windows, and the real problem here is the FAT32 driver's invalid interpretation
of modtimes as UTC instead of local.
In fact, FAT32 timestamps appear to have been broken by other Linux changes,
which puts the fix on generally shaky ground (systemd is implicated
here
and elsewhere, though the web abhors definitive statements).
More information on the fix will be posted on this page if it emerges, but Linux FAT32 support
is a bizarrely convoluted story which has morphed in recent years (as Linux stories tend to be),
and full coverage is out of scope here.
In short, though, on some systems today, you may (or may not) also need to add an
--adjust-system-clock argument to timedatectl;
may (or may not) need to mount/attach your drive after this command's invocations;
and may (or may not) aggravate or trigger the problem by using a dual-boot install.
A more direct fix may involve manually mounting or remounting FAT32
(i.e., vfat) drives with custom options to avoid or correct
timestamp mapping—for example, by turning option tz=UTC off,
turning time_offset=minutes on, adjusting the offset whenever
DST changes, and wrestling with conflicting auto-mounts as needed.
But this is ridiculous extra work to ask of users of programs like Mergeall;
is not necessary on any other platform but Linux; and is also largely out of scope here.
To be blunt, this page's mission is neither to document issues that the Linux community
largely has not, nor provide complex work-arounds to defects that seem much more up to
Linux to fix than users to accommodate. In the end, FAT32 USB drives on Linux
should just work—especially when they do everywhere else.
Their modtime behavior on Linux is fairly classified as a bug, despite the rationales.
To hunt for more details and tips on your own,
see the user guide's brief
mention;
read the man pages for the timedatectl and mount commands on
your PC or
here and
here;
check out the dual-boot time overview in
this article;
grok the time details in
this page;
and search the web either
here or
here.
As recommendations, Linux users' best Mergeall interoperability options today may be to:
Wait to adopt exFAT as soon as the Linux kernel does correctly
Punt on dual-boot Linux installs to skirt some time issues
Or pretend to be a system administrator and tweak FAT32 mount options
Unfortunately, none of these qualify as user friendly or universally applicable.
Also unfortunately, this seems typical of much of today's Linux experience.
And Android Does Both Better
It's worth noting that this story generally differs today on Android, despite
its Linux heritage. On Android, exFAT is mostly supported by vendor extensions.
For instance, exFAT drives work correctly on recent Samsung smartphones, though their
modtimes are reliable only as of Samsung's 2020 flavor of
Android 10.
Unlike desktop Linux, however, Android has long supported FAT32 correctly without the drama.
The Linux community really should care.
There's a new usage tip for setting Linux file associations to open
the PyEdit editor/launcher
automatically when files are clicked in the Nautilus file explorer. The tip
also provides simple patches that improve PyEdit's GUI cosmetics and usability
on this platform in general, and its .desktop-file install
instructions suffice to add PyEdit and others to the Linux applications launcher,
from which it can also be added to the Favorites in the Dock toolbar.
In the end, this tip was too large to embed in this already-full page:
please visit its
separate page.
This note's tip is briefly mentioned on the separate page referenced
by the preceding PyEdit note, but it applies to all the complete
applications at this site:
PyEdit, Frigcal, Mergeall, PyMailGUI, and PyGadgets.
The current 2017 Linux frozen executables available for
these applications are no longer recommended as of late 2020. They still
basically function, and open just as fast as source code when SSDs are used.
However, Linux morph over the last three years has:
Rendered their fonts largely unusable—executables now print errors
on startup and appear to fall back on Times
Fully broken their URL popups—executables' Help views now all fail
with obscure linker errors related to Firefox
Likely created more issues undiscovered, because
isolating Linux-induced failures is low priority (and tedious)
This shouldn't happen. These are self-contained programs that
were built just three years ago, embed their own Python and Tk,
and have equivalents that still work well on both Mac OS and Windows.
Only Linux has managed to cripple them so quickly—and through no
fault of their own. Clearly, backward compatibility for existing
programs is not what it should be in the Linux world today.
Future Linux rebuilds of this site's executables may improve this story,
but for now:
please use the source-code versions of all these programs on Linux,
instead of their executables.
The source-code versions sidestep externally introduced breakages by using
the latest installed versions of everything, even if that means acquiring
unexpected functionality changes as part of the bargain.
Exception: the 2017 executables may still work as designed on older versions
of Linux today, though the trend towards frequent and automatic updates may
make this moot for most users. If you're unsure about recent updates applied
on your Linux, or your executable's fonts look just plain busted, try fetching
and running the source-code version instead.
And be sure to file this away as yet another lesson on the perils of morph
in the software world. Programs break over time, but especially on Linux,
where rapid change coupled with a rude disregard for existing software
seems to have become a cultural norm. Linux is fun to use, but it's
difficult to justify developing for a platform where three years passes
as program shelf life (though, to be fair, Mac OS's upcoming chip swap
will undoubtedly cull many an
app too).
Update:
The Mergeall Linux executable was rebuilt in February 2022, and this new build
fixes both the font and Help breakages for this program. Hence, Mergeall is currently
exempt from the above, but it's prone to break again if (really, when) Linux morphs again,
and other programs have not yet been rebuilt. Source code remains a fallback option.
This note is primarily of interest to users of Mergeall on Mac OS, who may also
use network-drive servers elsewhere.
While testing a Mergeall sync between Mac OS and a
WebDAV server
running on an Android smartphone, it was discovered that Mac OS silently replaces filename
characters normally illegal on
FAT32 and
exFAT
drives with odd Unicode private-range characters. For example,
a | is mapped to and from \uf027 on these drives on writes and reads, respectively.
Unfortunately, this magic mapping may cause name-matching problems if such files are served
outside the Mac's exclusive realm.
The Munge in Action
It's easy to prove the munge using Python 3.X on Mac OS.
On an exFAT USB drive, for example, filename characters
are automatically mapped on writes and reads:
>>> import os
>>> os.chdir('/Volumes/SSDT3')
>>> os.mkdir('test')
>>> os.chdir('test')
>>> open('file\uf027name\uf020here', 'w').write('hmm') # write munged chars
3
>>> os.listdir('.') # receive illegals
['file|name"here']
>>>
>>> open('file|name"here', 'r').read() # either name works
'hmm'
>>> open('file\uf027name\uf020here', 'r').read() # but only on mac os
'hmm'
>>>
>>> open('file|name"here', 'w').write('hmm more') # write different name
8
>>> open('file|name"here', 'r').read() # two names for same file
'hmm more'
>>> open('file\uf027name\uf020here', 'r').read() # one update changes both
'hmm more'
>>> os.listdir() # this is not cool...
['file|name"here']
And the same character-mapping happens for a USB drive using the FAT32
filesystem (which, like exFAT, owes its existence to Microsoft, and
some of its limitations to PC history):
But internal APFS drives don't map; illegal characters are allowed
on a Unix-oriented filesystem like this, but this means core data
storage behavior differs per drive type on Macs:
>>> os.chdir('/Users/me/Documents')
>>> os.mkdir('test')
>>> os.chdir('test')
>>> open('file\uf027name\uf020here', 'w').write('hmm')
3
>>> os.listdir('.')
['file\uf027name\uf020here'] # what some servers return
>>>
>>> open('file\uf027name\uf020here', 'r').read()
'hmm'
>>> open('file|name"here', 'r').read() # behavior diff: surprise!
Traceback (most recent call last):
File "", line 1, in
FileNotFoundError: [Errno 2] No such file or directory: 'file|name"here'
Nor is this just Python 3.X: Python 2.X yields the same results on Mac OS,
and filenames written by the shell are munged too, but be sure to use
u'...' Unicode literals in Python 2.X (else \uxxxx
escapes are not recognized, but taken literally):
This mapping follows a model used in
Cygwin.
It works well if the drives are used on Mac OS only (the mapping hides the munge),
and usually works if propagated to other platforms (the Unicode replacement characters
are stored literally elsewhere, but match themselves on the drives). However, if such
filenames are propagated to another platform, and provided to Mac OS by a network-drive
server running on that other platform, the replacement characters propagated from Mac OS
may not match the originals back on Mac OS.
The result is spurious Mergeall differences, which trigger either erroneous updates
or failures.
This is an atypical use case to be sure, and surfaced only after 7 years of Mergeall use,
while searching in vain for an alternative to the USB-drive access dropped by
Android 11.
Moreover, some network servers (e.g., Samba/SMB, as detailed
here and
here)
may undo Mac OS's mappings when providing
files, thereby negating the issue (and possibly triggering others).
But you may need to care if you intend to use WebDAV
servers, and possibly others, to sync between content copies stored on Mac OS, and others
propagated elsewhere by Mac OS on FAT32 or exFAT drives.
The only known work-around for this issue is file renaming, of the sort automated and
provided by a new Mergeall utility script, currently available only online here:
This script further documents the issue, and can be run to automatically
replace nonportable characters in all the file and folder names in a tree
with a single _ (underscore) to make them interoperable. This is slightly risky:
it's unlikely but possible that the renames will collide with unrelated names in other content
copies, and the script may change names that intentionally use characters valid
on Unix only. Hence, this manual approach is the best policy today, because it
gives you a chance to preview the changes.
Really, though, Mac OS should report illegal characters as errors instead of silently
munging them, so users have a chance to address the issue explicitly. Hiding problems
is not the same as fixing them, and, as usual, magic causes damage eventually—in
this case, just as soon as content has the gall to leave the Mac OS "ecosystem."
You'd think this field would have learned such lessons by now, but engineering
born of opinion and arrogance still has a way of winning the day (and wrecking
the program).
As for Mergeall on Android: the next note gives a general review, but
on-phone-server sync experiments were abandoned,
because Mac OS's built-in WebDAV client
support
produced obvious data corruption; Linux's WebDAV
support was better
but still difficult to
configure
and use; and Samba
servers
ran too slowly to be practical (and were
nearly unusable on Windows due to hard-coded port numbers on Windows
and port-number restrictions on Android). Your mileage may vary, but pulling out
microSD cards—where available—seems the best alternative to the USB
access sadly and rudely ripped away in Android 11. At least, until microSD cards
become an ex-feature too...
Update:
The Mac OS munge of nonportable-character filenames was later seen to also
impact both MTP and FTP access on Mac OS, with the same
sync mismatches and update consequences as for WebDAV: when served by any of these protocols,
filenames munged by macOS won't match originals on macOS, and will trigger bogus updates.
Yet more reasons to run the helper script to flag nonportable filenames which Mac OS silently
allows to leak out in disguise to other platforms (and harm users who dare stray off the Apple range).
Update:
Though less impactful, symlinks are similarly munged in transit
from Mac OS on Windows filesystems: because they're stored by Mac OS as a simple stub
file recognized by Mac OS only, they won't register as symlinks on other platforms.
This is generally harmless when symlinks are only transported on drives: they'll always
be simple files elsewhere, but won't be changed there. When served elsewhere
by WebDAV, MTP, FTP, or similar, however, symlinks' files register as mixed-mode
differences with the true symlinks on Mac OS, and thus won't survive a round trip
to/from other platforms.
The upside is that symlinks are so notoriously
nonportable
that interoperability expectations should already be appropriately low.
Update:
It's worth adding that Linux prefers nonfunction over magic:
it reports errors and refuses to copy nonportable filenames to Windows-filesystem
drives (e.g., exFAT) in both file explorers and command lines, and similarly
disallows symlinks instead of trying to forge them on these drives. This is an
arguably safer policy than covert changes that cause later problems, but the
fixer script is also required when transferring content from Linux to Windows.
It's also worth adding that some Androids' shared storage imposes the same
filesystem rules as Windows; see the ziptools
guide
for more details.
As expected, Android 11's privacy-obsessed agendas broke Mergeall
and similar content-processing tools on multiple fronts. Most grievously, general access
to USB drives was revoked, and shared-storage was throttled down to run up to 100X
slower than app-private/specific storage. These are lethal for programs that
manage large content collections on phones, and likely an endgame for running
Mergeall on Android.
Though breakage was expected, the forms it took were not. It was known that
Android 11 intended to lock down internal storage via app
sandboxes, but this
hasn't yet happened for apps still in an opt-out state, like those used to run
Mergeall. Android 11's immediate changes, however, were more than ample to
break programs:
Revoking USB-drive access makes on-phone content management nearly impossible,
with no usable work-arounds. Other connections schemes are too slow or flawed,
and programs must be rewritten to use Java-based frameworks to gain USB permissions.
Throttling shared-storage speed is just as toxic, as it effectively makes
on-phone content both impermanent and inaccessible. You can store content in faster
app storage, but it will be deleted if you uninstall the app, and it cannot be used
in most cross-app roles.
For the full story on Android 11 breakages, please see the separate
updates page.
Other programs at this site work on Android 11,
and the Mergeall content-processing program can still be used on Mac OS, Windows, and Linux;
Android, however, seems to no longer care about supporting programs based on computing
paradigms developed over the last half century. Smartphone users are the unfortunate
victims of the arrogance.
For users of the Mojave (10.14) release of Mac OS (macOS) only:
if this site's apps or source-code GUIs
open blank screens or crash on start-up, it's probably because your platform's
newly launched dark mode causes problems in the Tk library underlying tkinter,
which were repaired by Catalina. This note provides a quick fix and additional
context for the issue.
Fixing App GUIs
This issue has not been seen to occur on Mac OS either before or after
Mojave, but it's easy to fix for apps on Mojave: simply run a command
line of the following sort once in Terminal, and restart the app:
This command fixes Mergeall by disabling
dark mode for the app (there's more on why this works ahead).
To do the same for other apps here,
just replace the command's Mergeall text with another app's name,
and run the modified command again. For example, substitute
Frigcal, PyEdit,
PyMailGUI, or PyGadgets, like this:
The preceding commands fix this site's frozen apps. Though this remains to
be verified, you may need to apply the same Mojave fix to the installed Python
app too, for any tkinter GUIs run in source-code form. This
isn't required for this site's apps (which bundle and run their own Python),
but may be needed for running the main scripts of this site's source-code packages,
as well as the source-code scripts of any other tkinter GUIs. Where necessary,
run the following in Terminal to fix source GUIs run by Python explicitly:
In addition, the following Terminal commands may be required for running
tkinter source-code GUIs with the installed Python app's launcher or IDLE
(clarifications to be posted here if/when these can be tested):
In the interest of full disclosure, you can also remove these settings later
if desired by the first of the following forms, and force dark mode on with
the second (though neither is generally required for programs at this site):
defaults delete appnamesetting
defaults write appname NSRequiresAquaSystemAppearance -bool no
It's also worth noting that edits in the app's Contents/Info.plist
file can likely have the same effect as defaults commands, but are
arguably more complex and error prone. They could, however, be applied in
future app releases, and might look like this snippet (which is plausible
but completely untested; more here too post verifications) :
<key>NSRequiresAquaSystemAppearance</key>
<true/>
More about the Bug
These commands avoid GUI breakages by disabling dark mode for
specific apps only (and are macOS's equivalent of Windows registry edits).
Dark mode was new in Mojave, and apparently
triggered blank screens and start-up crashes in the underlying Tk
library. This also impacted other programs and GUIs, including
some coded with the PyQt alternative; for related threads,
try searches like
this and
this.
The signature of the breakage may be an error message of this form,
along with CGContext messages concerning an invalid context 0x0:
Python[1936:146864] It does not make sense to draw an image when [NSGraphicsContext currentContext] is nil. This is a programming error. Break on void _NSWarnForDrawingImageWithNoCurrentContext(void) to debug. This will be logged only once. This may break in the future.
Though full details are difficult to reconstruct, this issue was
later addressed in either Apple or Tk code. On all Mac OS Catalina
devices tested: the fix commands are not required, and have no effect
if used; this site's apps as shipped work without these issues;
and the apps' source-code versions work well using the latest python.org
Mac OS Python install, and its bundled Tk. The older Tk bundled with
the apps works on Catalina too, so Apple's code was the likelier scene
of the fix.
Hence, this seems a one-version Mac OS issue, for which the Terminal
commands are a regrettable but reasonable work-around. The Mergeall
team didn't catch the bug earlier, because the procurement department
skipped Mojave and moved straight on to
Catalina
(alas, skipping a year's release is perilous business today).
Thanks are due to a Mergeall user for both bringing this problem
to light, and verifying its fix.
All that said, you'll have to do the math for yourself on why a computer
vendor would release a half-baked dark mode, almost certainly knowing full
well that it would break many programs. This site's programs
have now been burned so many times by such rude nonsense that this
page has run out of words to rant about it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
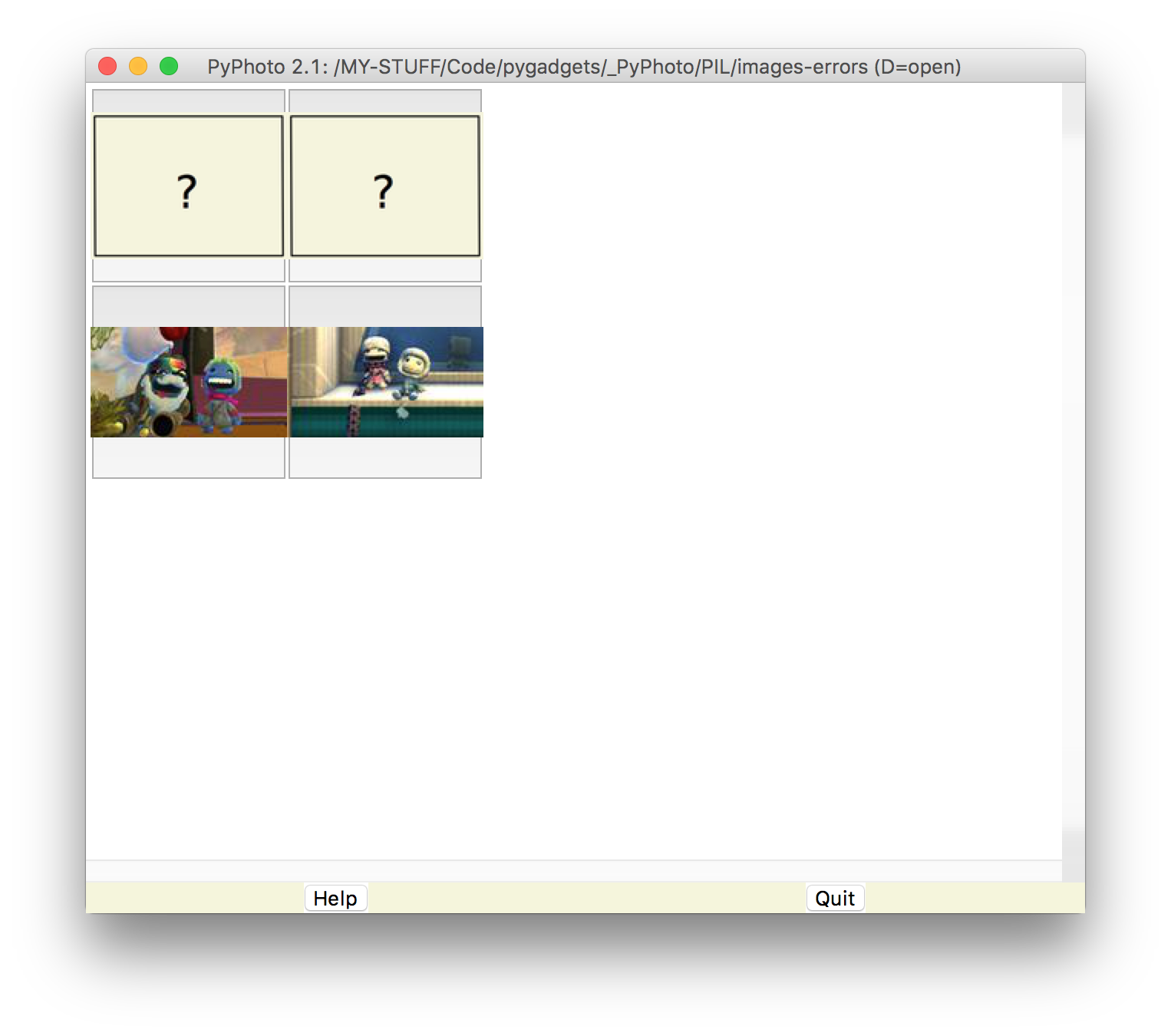{kind=link}
{kind=link}
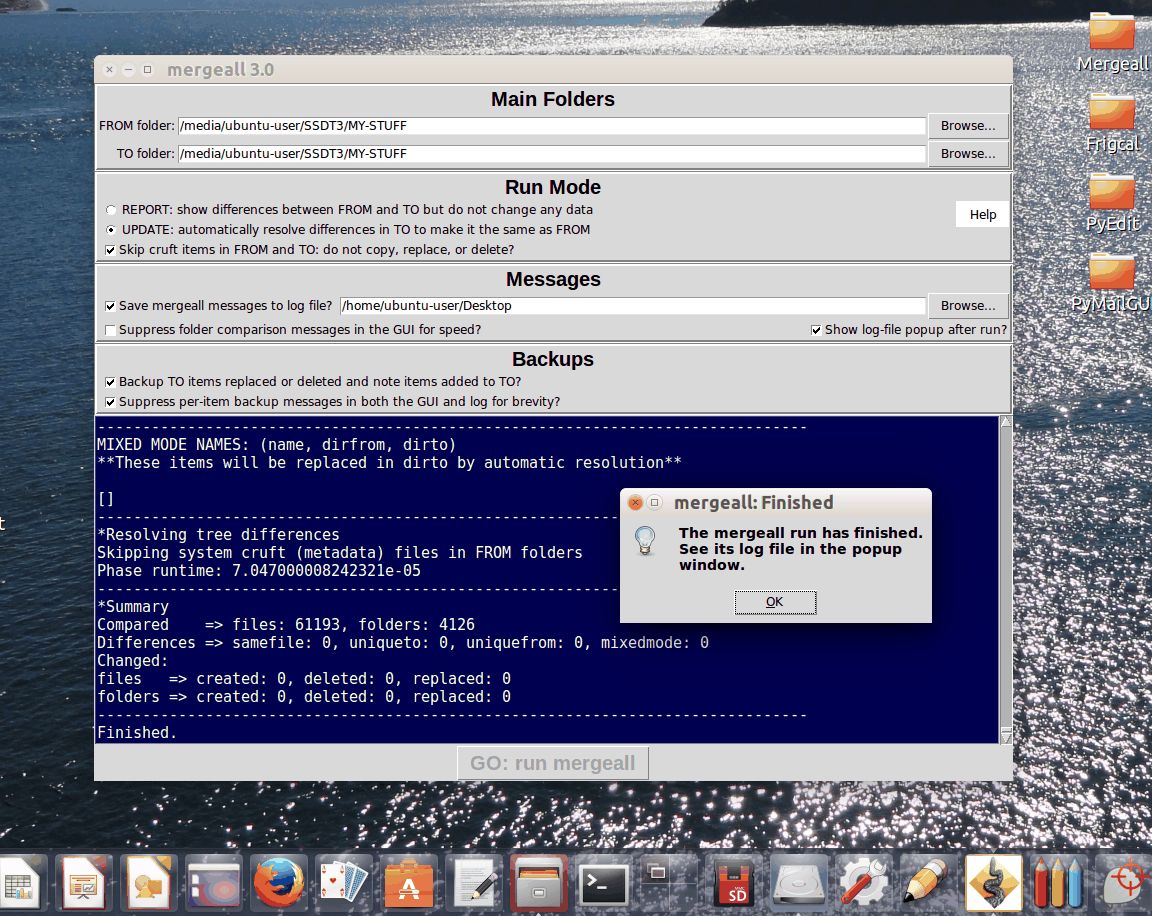{kind=link}
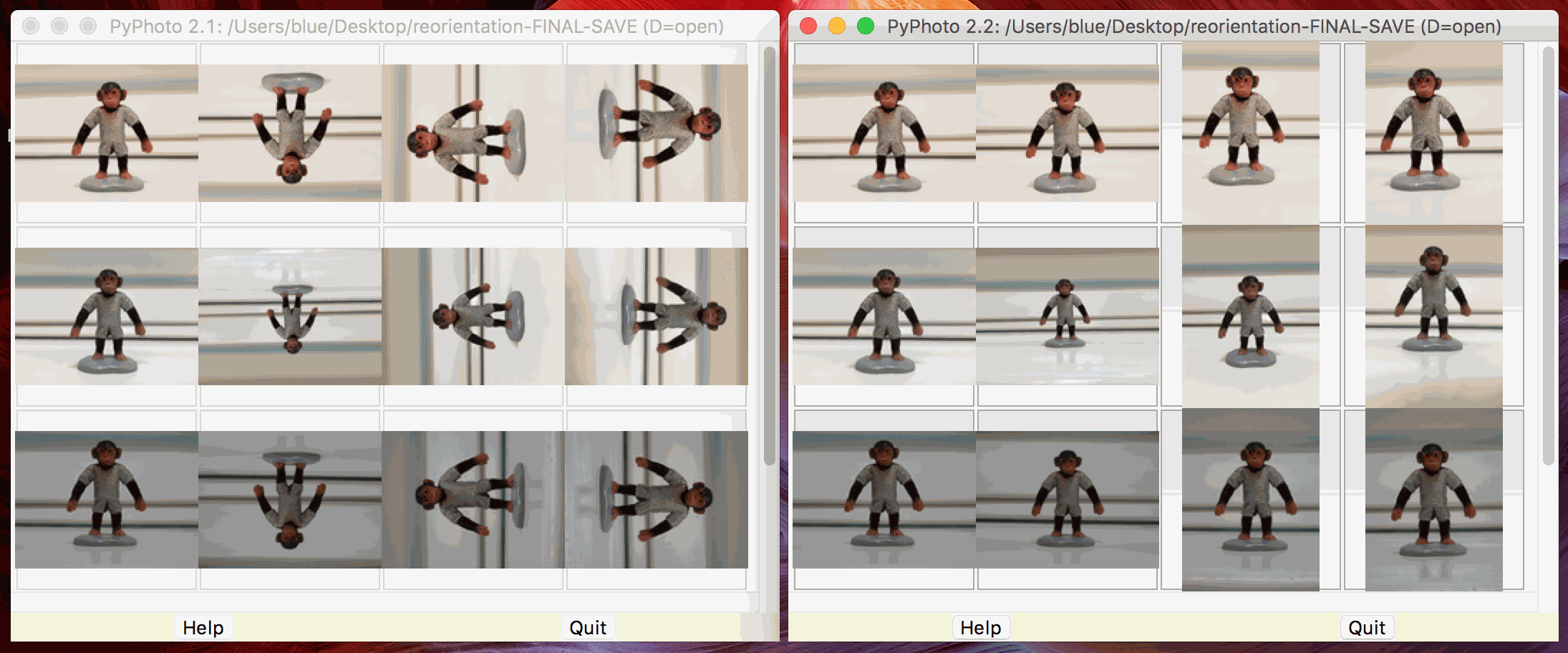{kind=link}
{kind=link}
{kind=link}
{kind=link}
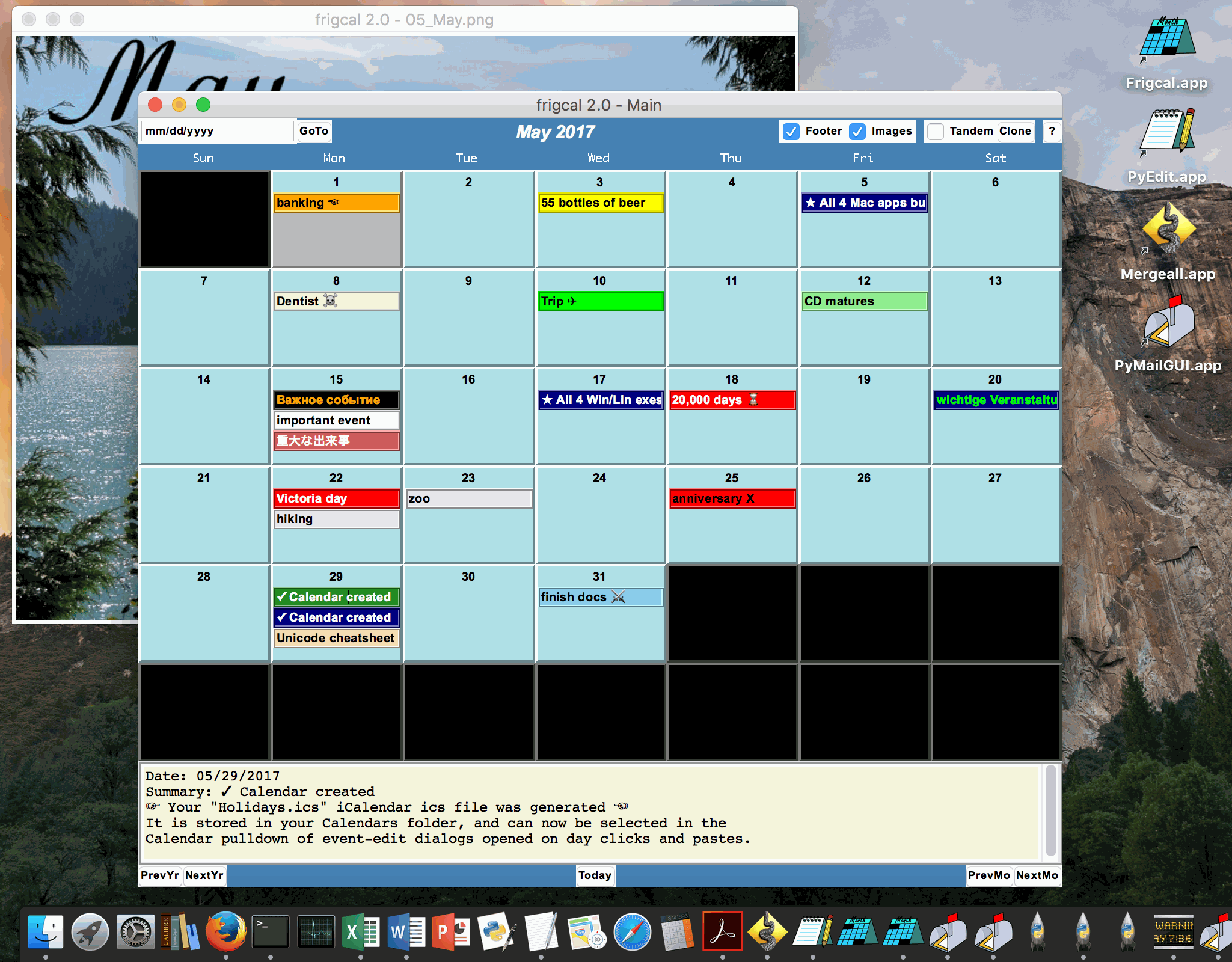{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
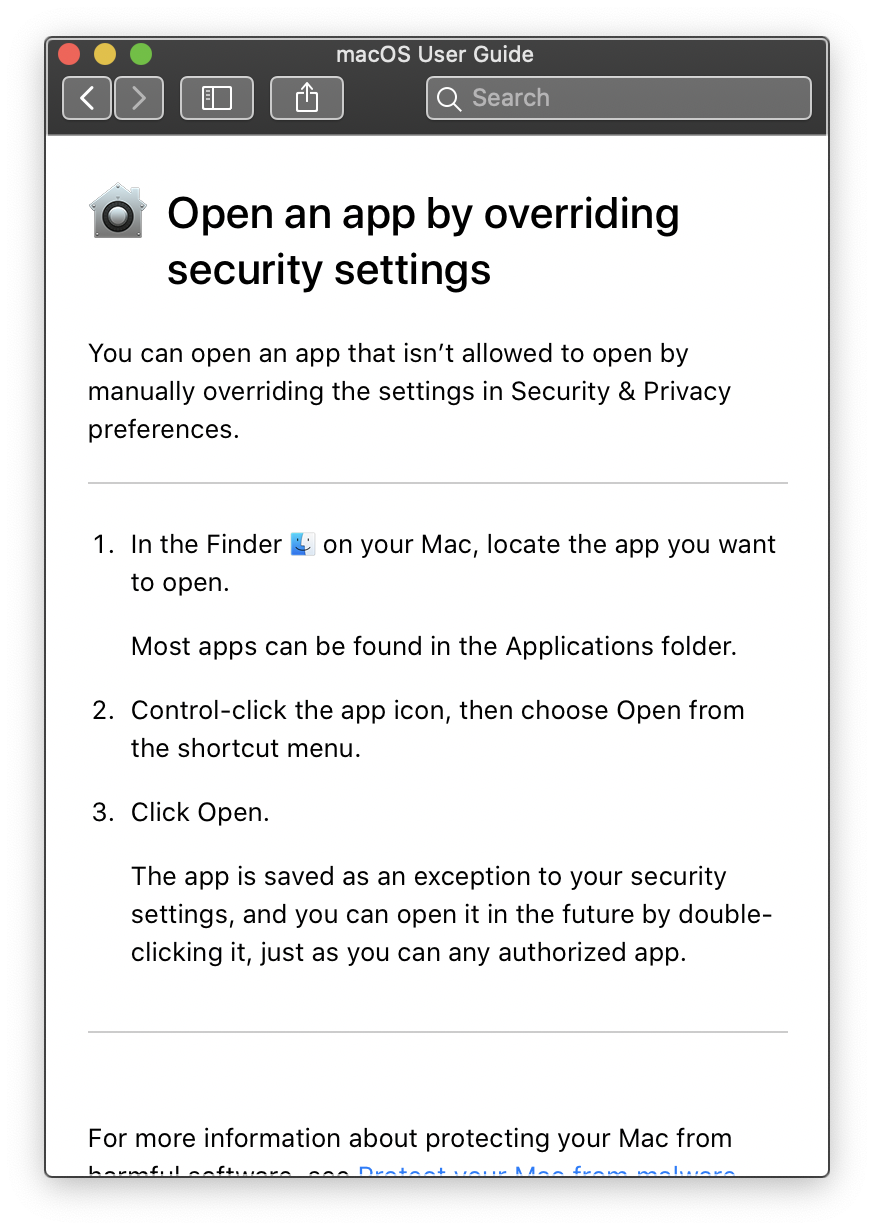{kind=link}
{kind=link}
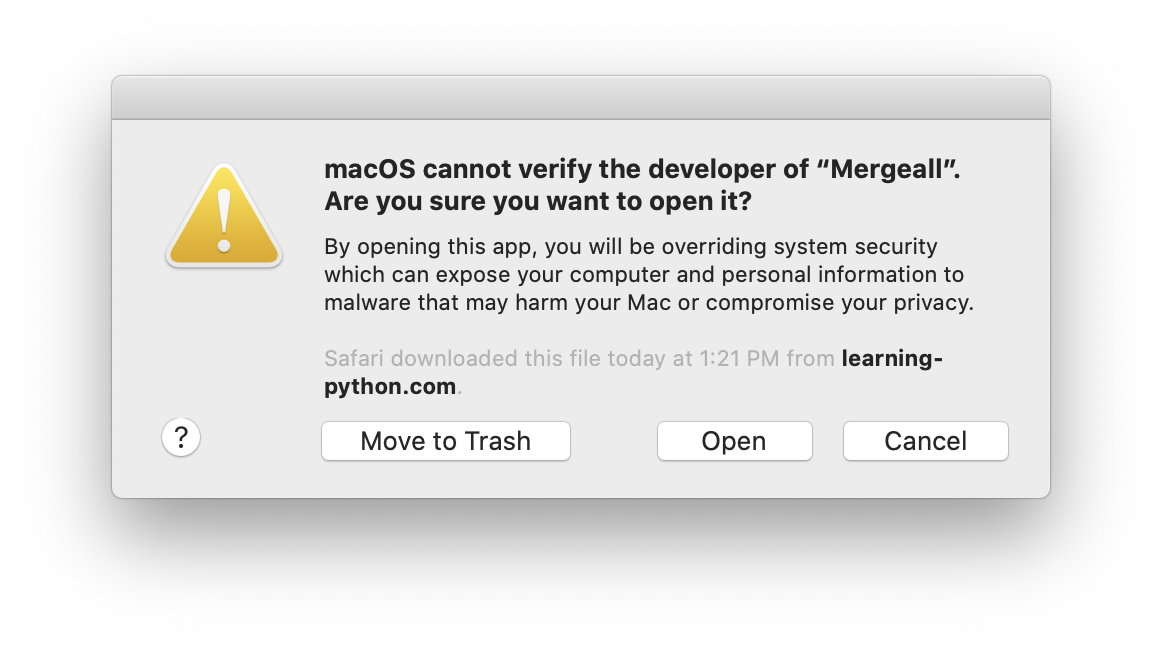{kind=link}
{kind=link}
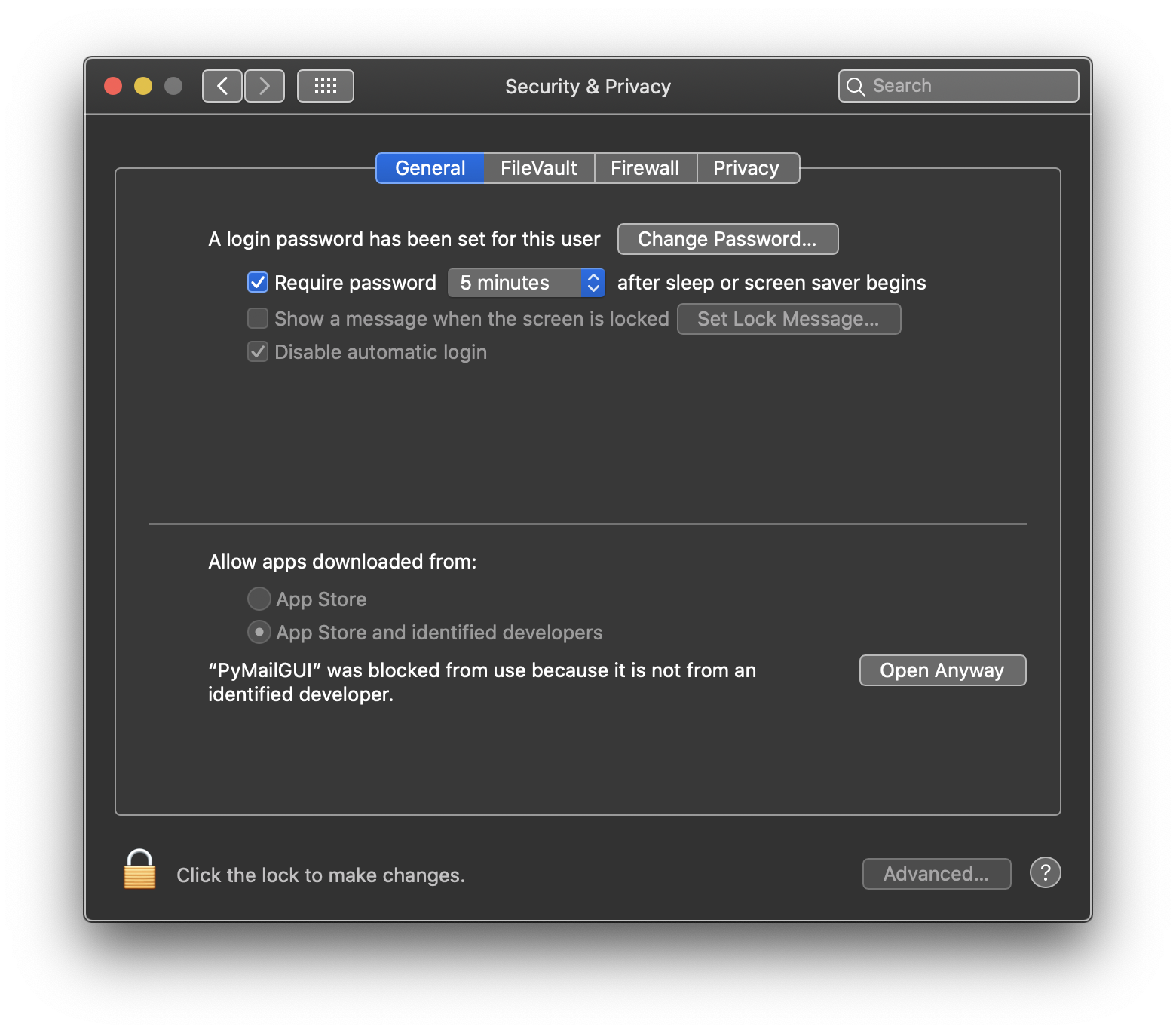{kind=link}
{kind=link}
{kind=link}
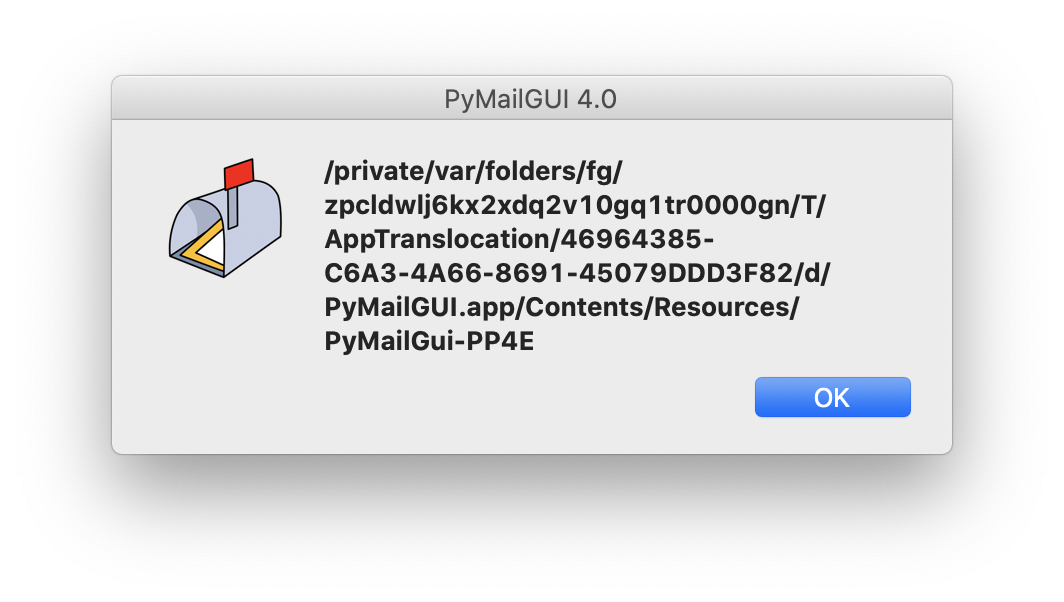{kind=link}
{kind=link}
{kind=link}
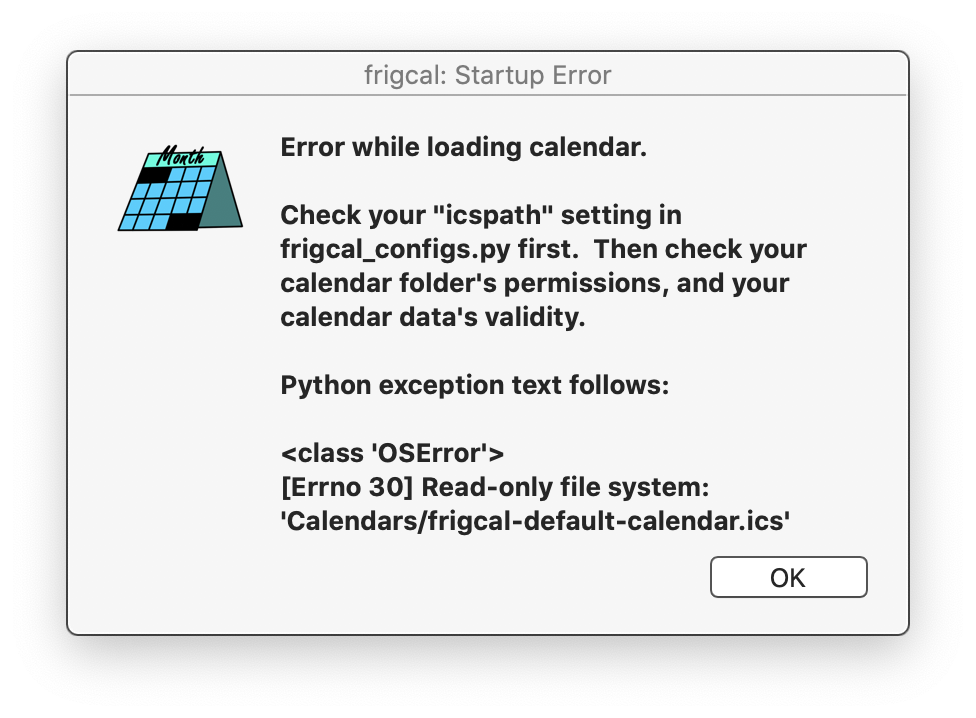{kind=link}
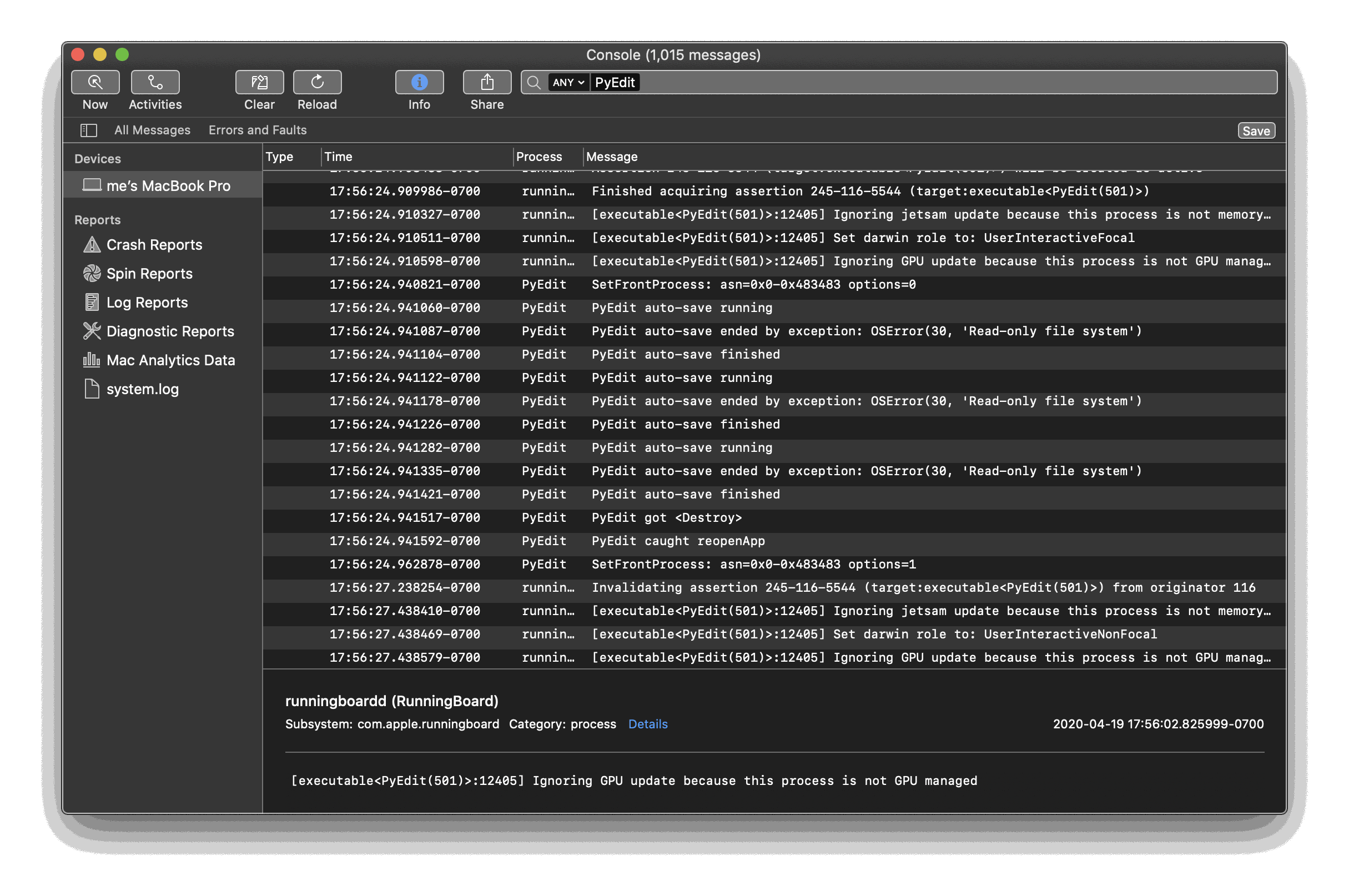{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
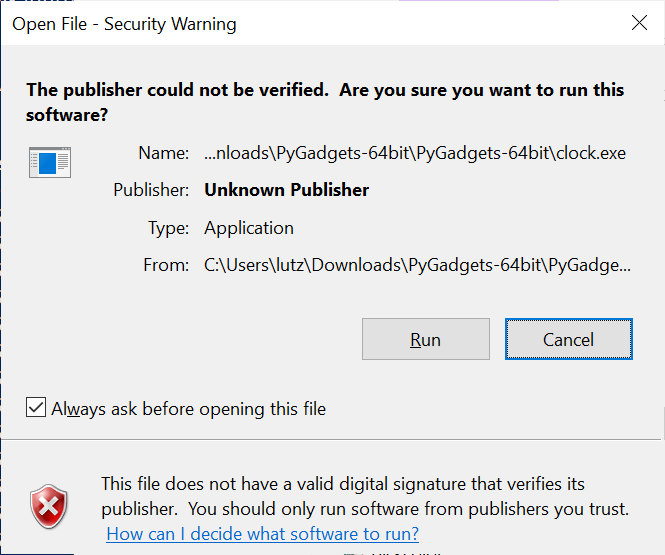{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}