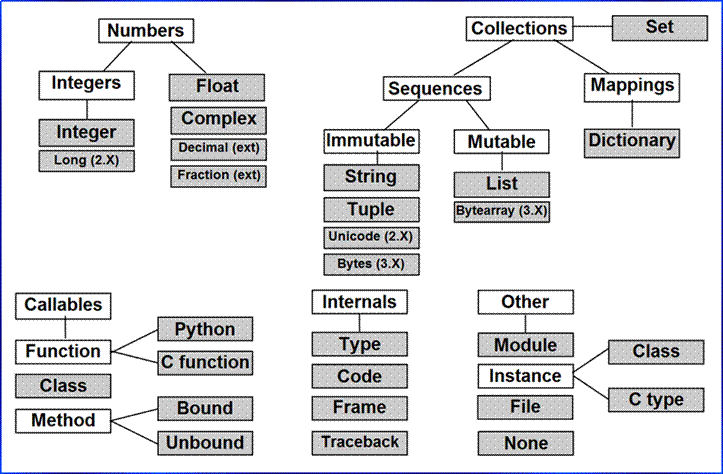
Preview: built-in objects
|
Object type |
Example constants/usage |
|
Numbers |
3.14, 1234, 999L, 3+4j,
decimal |
|
Strings |
'spam',
"spam's" |
|
Lists |
[1, [2, 'three'], 4] |
|
Dictionaries |
{'food':'spam',
'taste':'yum'} |
|
Tuples |
(1,'spam', 4, 'U') |
|
Files |
text = open('eggs',
'r').read() |
|
Others |
sets, types, None, bool |
Demo: Built-in Types, a first pass
■
Most examples
listed ahead
■
See also Extras\Other\PriorClasses logs for
similar code
■
Key terms:
“sequence”, “immutable”, “mapping”
■
Key ideas: no
fixed types, no fixed sizes, arbitrary nesting
■
Full story:
dir(object), help(object.method), manuals
The ‘big
picture’
Python program structure
♦ Programs are composed of modules
♦ Modules contain statements
♦ Statements contain expressions
♦ Expressions create and process objects
Why use built-in types?
♦ Python provides objects and supports extensions
♦ Built-in objects make simple programs easy to write
♦ Built-in objects are components of extensions
♦ Often more efficient than custom data structures
Numbers
Standard types and operators
♦ Integer, floating-point, hex/octal constants
♦ ‘long’ integer type with unlimited precision
♦ Built-in mathematical functions: ‘pow’, ‘abs’
♦ Utility modules: ‘random’, ‘math’
♦ Complex numbers, ‘**’ power operator
Numeric Python (NumPy)
♦ An optional extension, beyond core language
♦ For advanced numeric programming in Python
♦ Matrix object, interfaces to numeric libraries, etc.
♦ Plus SciPy, matplotlib, pypar, IPython shell, others
♦ Python + NumPy = open source MATLAB alternative
►For interested audiences: Numerical overview page
Numeric literals
|
Constant |
Interpretation |
|
1234,
-24 |
integers
(C longs, 3.X: unlimited size) |
|
99999999L |
2.X
long integers (unlimited size) |
|
1.23,
3.14e-10 |
floating-point
(C doubles) |
|
0o177,0x9f,0b101 |
octal,
hex, binary integer literals |
|
3+4j,
3.0+4.0j |
complex
number literals |
|
Decimal('0.11') |
fixed-precision
decimal (2.4+) |
|
Fraction(2,
3) |
rational
type (2.6+, 3.0+) |
Python expressions
♦ Usual algebraic operators: ‘+’ , ‘-’, ‘*’, ‘/’, . . .
♦ C’s bitwise operators: “<<”, “&”, . . .
♦ Mixed types: converted up just as in C
♦ Parenthesis group sub-expressions
Numbers in action
♦ Variables created when assigned
♦ Variables replaced with their value when used
♦ Variables must be assigned before used
♦ Expression results echoed back
♦ Mixed integer/float: casts up to float
♦ Integer division truncates (until 3.X: use // to force)
% python
>>> a = 3 # name created
>>> b = 4
>>> b / 2 + a # same as ((4 / 2) + 3)
5
>>> b / (2.0 + a) # same as (4 / (2.0 + 3))
0.8
>>> 1 / 2, 1 // 2 # 3.X: / keeps remainder, // does not
(0.5, 0)
Hint: use print if you don’t want all the precision (in some versions):
>>> 4 / 5.0
0.80000000000000004
>>> print 4 / 5.0 # 3.X: print(4 / 5.0)
0.8
The dynamic typing
interlude
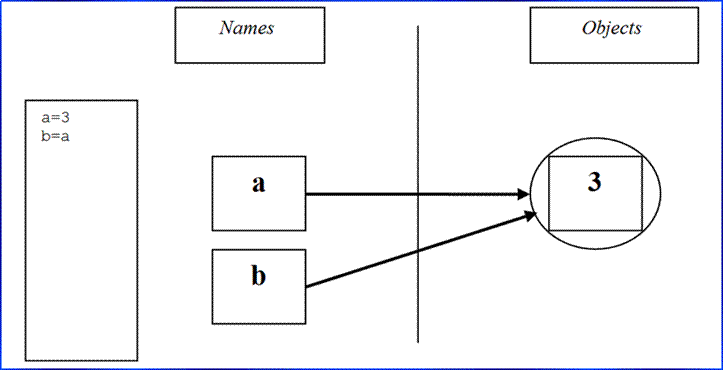
>>> a = 3 # Where are the missing declarations?
● Names
versus objects
● Names are always “references” (pointers) to objects
● Names are created when first assigned (or so)
● Objects have types, names do not
● Each value is a distinct object (normally)
● Objects are pieces of memory with value + operations
● Shared references to mutables are open to side
effects (on purpose)
Back to numbers: bitwise operations
>>> x = 1
>>> x << 2 # shift left 2 bits
4
>>> x | 2 # bitwise OR
3
>>> x & 1 # bitwise AND
1
Long integers
♦ 2.X only—subsumed by arbitrary precision int in 3.X
♦ Via ‘L’ suffix
♦ Some performance penalty
♦ As of 2.2, integers auto-converted to long if too big (“L” optional)
>>> 9999999999999999999999999999L + 1
10000000000000000000000000000L
>>> 9999999999999999999999999999 + 1
10000000000000000000000000000L
before 2.2:
>>> 9999999999999999999999999999 + 1
OverflowError: integer literal too large
Decimal and Fraction extension types
>>> 0.1 + 0.1 + 0.1 - 0.3
5.5511151231257827e-017
>>> print 0.1 + 0.1 + 0.1 - 0.3
5.55111512313e-017
>>> 0.1 + 0.1 + 0.1 - 0.3
# as of 3.4
5.551115123125783e-17
>>> from decimal import Decimal
>>> Decimal('0.1') + Decimal('0.1') + Decimal('0.1') -
Decimal('0.3')
Decimal("0.0")
>>> Decimal('0.1') + Decimal('0.10') + Decimal('0.10') -
Decimal('0.30')
Decimal("0.00")
>>> from
fractions import Fraction
>>>
Fraction(1, 3) + Fraction(2, 8)
Fraction(7, 12)
>>>
Fraction(1, 10) + Fraction(1, 10) + Fraction(1, 10) - Fraction(3, 10)
Fraction(0, 1)
Python operators and precedence
■ Operators lower in table bind tighter (parens force order)
■ Preview: all Python operators may be overloaded by Python classes and C extension types
■ Added
in Python 2.0: +=. *=, &=, …
augmented assignment statements, not operators
■
Python 3.X: `X` →
repr(X), X / Y → true div, X <> Y → X != Y
■ Recent
operator/expression additions:
|
x if y else z |
Ternary
if, same as 4-line if/else statement |
|
yield [from] x |
Generator
function’s iteration result (return can send one too) |
|
await x |
For
3.5+ async def coroutines |
|
x @ y |
Matrix
multiply in 3.5+ (but not used by core Python itself!) |
|
[x, *iter] |
Unpacks
(flattens) objects in literals in 3.5+ |
|
Operators |
Description |
|
x or
y, lambda
args: expr |
Logical
‘or’ (y is only evaluated if x is false), anonymous function |
|
x and
y |
Logical
‘and’ (y is only evaluated if x is true) |
|
not
x |
Logical
negation |
|
<,
<=, >, >=, ==, <>, !=, is,
is not, in, not in |
Comparison
operators, sequence
membership |
|
x |
y |
Bitwise
‘or’ |
|
x ^
y |
Bitwise
‘exclusive or’ |
|
x
& y |
Bitwise
‘and’ |
|
x
<< y, x >> y |
Shift
x left or right by y bits |
|
x +
y, x – y |
Addition/concatenation,
subtraction |
|
x *
y, x / y, x % y, x // y |
Multiply/repetition,
divide, remainder/format, floor divide |
|
x **
y, -x, +x, ~x |
Power,
unary negation, identity, bitwise compliment |
|
x[i],
x[i:j], x.y, x(...) |
Indexing,
slicing, qualification, function calls |
|
(...),
[...], {...}, `...` |
Tuple,
list, dictionary, conversion to string |
Strings
♦ Ordered collections of characters
♦ No ‘char’ in Python, just 1-character strings
♦ Constants, operators, utility modules (‘string’, ‘re’)
♦ Strings are ‘immutable sequences’
♦ See ‘re’ module for pattern-based text processing
About
Unicode support: this section covers basic, ASCII text
strings. See the Advanced
Topics section for coverage of Unicode and byte strings and files. This varies per Python line. In 3.X, strings are always Unicode and
support encoding to bytes, and bytes strings represent truly binary 8-bit data
and support decoding to strings. In 2.X,
strings are essentially the same as 3.X bytes strings (containing just 8-bit
characters), and Unicode is a special type similar to 3.X strings.
Common string operations
|
Operation |
Interpretation |
|
s1 =
'' |
single
quotes (empty) |
|
s2 =
"spam's" |
double
quotes (same) |
|
block
= """...""" |
triple-quoted
blocks, can
span multiple lines |
|
r'C:\new\text\file.txt' |
raw
strings (\ kept) |
|
s1 +
s2, s2 * 3 |
concatenate,
repeat |
|
s2[i],
s2[i:j], s[i:j:k], len(s2) |
index,
slice, length |
|
'a
%s parrot' % 'dead' 'a
{} parrot'.format('dead') |
string
formatting: original,
2.6+ option |
|
u'A\xC4B',
'A\xC4B' |
Unicode:
2.X, 3.X |
|
b'\x00spam\x01' |
bytes:
3.X (and 2.X) |
|
f'we
get {spam} a lot' |
formats:
3.6? |
|
for
x in s2, 'm' in s2 |
iteration/membership |
Newer extensions
● String methods:
X.split('+')
same as older string.split(X, '+')
string
module requires import, methods do not
methods
now faster, preferred to string module
● Unicode strings:
Multi-byte characters, for
internationalization (I18N)
U'xxxx'
constants, Unicode modules, auto conversions
Can mix
with normal strings, or convert: str(U), unicode(S)
Varies
in 3.X: see note box above for more details
● Template formatting: string module, see ahead
● String .format() method: largely redundant with “%”
Strings in action
% python
>>> 'abc' + 'def' # concatenation: a new string
'abcdef'
>>> 'Ni!' * 4 # like "Ni!" + "Ni!" + ...
'Ni!Ni!Ni!Ni!'
Indexing and slicing
>>> S = 'spam'
>>> S[0], S[-2] # indexing from from or end
('s', 'a')
>>> S[1:3], S[1:], S[:-1] # slicing: extract section
('pa', 'pam', 'spa')
Changing and formatting
>>> S = S + 'Spam!' # to change a string, make a new one
>>> S
'spamSpam!'
>>> 'That is %d %s bird!' % (1, 'dead') # like C sprintf
That is 1 dead bird!
Advanced formatting examples
>>> res = "integers: ...%d...%-6d...%06d" % (x, x, x)
>>> res
'integers: ...1234...1234 ...001234'
>>> x = 1.23456789
>>> x
1.2345678899999999
>>> '%e | %f | %g' % (x, x, x)
'1.234568e+000 | 1.234568 | 1.23457'
>>> '%-6.2f | %05.2f | %+06.1f' % (x, x, x)
'1.23 | 01.23 | +001.2'
>>> int(x)
1
>>> round(x, 2)
1.23
>>> x = 1.236
>>> round(x, 2)
1.24
>>> "%o %x %X" % (64, 64, 255)
'100 40 FF'
>>> hex(255), int('0xff', 16), eval('0xFF')
('0xff', 255, 255)
>>> ord('s'), chr(115)
(115, 's')
Formatting with dictionaries
>>> D = {'xx': 1, 'yy': 2}
>>> "%(xx)d => %(yy)s" % D
'1 => 2'
>>> aa = 3
>>> bb = 4
>>> "%(aa)d => %(bb)s" % vars()
'3 => 4'
>>> reply = """
Greetings...
Hello %(name)s!
Your age squared is %(age)s
"""
>>> values = {'name': 'Bob', 'age': 40}
>>> print reply % values
Greetings...
Hello Bob!
Your age squared is 40
Formatting method
alternative (2.6+, 3.0+)
>>> '{} {}'.format(42, 'spam')
'42 spam'
>>> '{0:.2f}'.format(1.234)
'1.23'
>>> '{0:,.2f}'.format(1234567.234)
'1,234,567.23'
Template formatting (2.4+)
>>> ('%(page)i: %(title)s' %
{'page':2, 'title': 'The Best of Times'})
'2: The Best of Times'
>>> import string
>>> t = string.Template('$page: $title')
>>> t.substitute({'page':2, 'title': 'The
Best of Times'})
'2: The Best of Times'
>>> s = string.Template('$who likes
$what')
>>> s.substitute(who='bob', what=3.14)
'bob likes 3.14'
>>> s.substitute(dict(who='bob',
what=’pie’))
'bob likes pie'
Common string tools
>>> S = "spammify"
>>> S.upper() # convert to uppercase
'SPAMMIFY'
>>> S.find("mm") # return index of substring
3
>>> int("42"), str(42) # convert from/to string
(42, '42')
>>> S.split('mm') # splitting and joining
['spa', 'ify']
>>> 'XX'.join(S.split("mm"), "XX")
'spaXXify'
Example: replacing text
# replace method
>>> S = 'spammy'
>>> S = S.replace('mm', 'xx')
>>> S
'spaxxy'
>>> S = 'xxxxSPAMxxxxSPAMxxxx'
>>> S.replace('SPAM', 'EGG') # replace all
'xxxxEGGxxxxEGGxxxx'
# finding and slicing
>>> S = 'xxxxSPAMxxxxSPAMxxxx'
>>> where = S.find('SPAM') # search for position
>>> where # occurs at offset 4
4
>>> S = S[:where] + 'EGGS' + S[(where+4):]
>>> S
'xxxxEGGSxxxxSPAMxxxx'
# exploding to/from list
>>> S = 'spammy'
>>> L = list(S) # explode to list
>>> L
['s', 'p', 'a', 'm', 'm', 'y']
>>> L[3] = 'x' # multiple in-place changes
>>> L[4] = 'x' # cant do this for strings
>>> L
['s', 'p', 'a', 'x', 'x', 'y']
>>> S = ''.join(L) # implode back to string
>>> S
'spaxxy'
Example: parsing with slices
>>> line = 'aaa bbb ccc'
>>> col1 = line[0:3] # columns at fixed offsets
>>> col3 = line[8:]
>>> col1
'aaa'
>>> col3
'ccc'
Example: parsing with splits
>>> line = 'aaa bbb ccc' # split around whitespace
>>> cols = line.split()
>>> cols
['aaa', 'bbb', 'ccc']
>>> line = 'bob,hacker,40' # split around commas
>>> line.split(',')
['bob', 'hacker', '40']
Generic type concepts
■ Types share operation sets by categories
■ Numbers support addition, multiplication, . . .
■ Sequences support indexing, slicing, concatenation, . . .
■ Mappings support indexing by key, . . .
■ Mutable types can be changed in place
■ Strings are ‘immutable sequences’
Concatenation and repetition
■ ‘X + Y’ makes a new sequence object with the contents of both operands
■ ‘X * N’ makes a new sequence object with N copies of the sequence operand
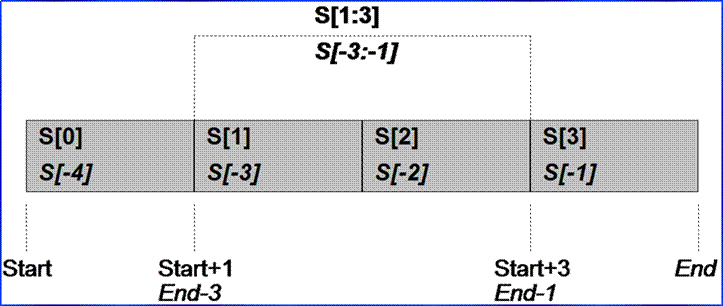
Indexing and slicing
■ Indexing
● Fetches components via offsets: zero-based
● Negative indexes: adds length to offset
● S[0] is the first item
● S[-2] is the second from the end (4 - 2)
● Also works on mappings, but index is a key
■ Slicing
● Extracts contiguous sections of a sequence
● Slices default to 0 and the sequence length if omitted
● S[1:3] fetches from offsets 1 upto but not including 3
● S[1:] fetches from offsets 1 through the end (length)
● S[:-1] fetches from offsets 0 upto but not including last
● S[I:J:K] newer, I to J by K, K is a stride/step (S[::2])
Lists
♦ Arrays of object references
♦ Access by offset
♦ Variable length, heterogeneous, arbitrarily nestable
♦ Category: ‘mutable sequence’
♦ Ordered collections of arbitrary objects
Common list operations
|
Operation |
Interpretation |
|
L1 =
[] |
an
empty list |
|
L2 =
[0, 1, 2, 3] |
4-items:
indexes 0..3 |
|
['abc',
['def', 'ghi']] |
nested
sublists |
|
L2[i],
L2[i:j], len(L2) |
index,
slice, length |
|
L1 +
L2, L2 * 3 |
concatenate,
repeat |
|
L1.sort(),
L2.append(4) |
methods:
sort, grow |
|
del
L2[k], L2[i:j] = [] |
shrinking |
|
L2[i:j]
= [1,2,3] |
slice
assignment |
|
range(4),
xrange(0, 4) |
make
integer lists |
|
for
x in L2, 3 in L2 |
iteration/membership |
Lists in action
% python
>>> [1, 2, 3] + [4, 5, 6] # concatenation
[1, 2, 3, 4, 5, 6]
>>> ['Ni!'] * 4 # repetition
['Ni!', 'Ni!', 'Ni!', 'Ni!']
Indexing and slicing
>>> L = ['spam', 'Spam', 'SPAM!']
>>> L[2]
'SPAM!'
>>> L[1:]
['Spam', 'SPAM!']
Changing lists in-place
>>> L[1] = 'eggs' # index assignment
>>> L
['spam', 'eggs', 'SPAM!']
>>> L[0:2] = ['eat', 'more'] # slice assignment
>>> L # replace items 0,1
['eat', 'more', 'SPAM!']
>>> L.append('please') # append method call
>>> L
['eat', 'more', 'SPAM!', 'please']
● Only works for ‘mutable’ objects: not strings
● Index assignment replaces an object reference
● Slice assignment deletes a slice and inserts new items
● Append method inserts a new item on the end (‘realloc’)
Preview: iteration/membership
>>> for x in L: print x,
...
eat more SPAM! please
Example: 2-dimensional array
>>> matrix = [[1, 2, 3],
... [4, 5, 6],
... [7, 8, 9]]
...
>>> matrix[1]
[4, 5, 6]
>>> matrix[1][1]
5
>>> matrix[2][0]
7
Dictionaries
♦ Tables of object references
♦ Access by key, not offset (hash-tables)
♦ Variable length, heterogeneous, arbitrarily nestable
♦ Category: ‘mutable mappings’ (not a sequence)
♦ Unordered collections of arbitrary objects
Common dictionary operations
|
Operation |
Interpretation |
|
d1 =
{} |
empty
dictionary |
|
d2 =
{'spam': 2, 'eggs': 3} |
2
items |
|
d3 =
{'food': {'ham': 1, 'egg': 2}} |
nesting |
|
d2['eggs'],
d3['food']['ham'] |
indexing
by key |
|
d2.has_key('eggs'),
d2.keys() |
methods |
|
d2.get('eggs',
default) |
default
values |
|
len(d1) |
length
(entries) |
|
d2[key]
= new, del d2[key] |
adding/changing
|
Dictionaries in action
% python
>>> d2 = {'spam': 2, 'ham': 1, 'eggs': 3}
>>> d2['spam']
2
>>> len(d2) # number entries
3
>>> d2.keys() # list of keys
['eggs', 'spam', 'ham']
Changing dictionaries
>>> d2['ham'] = ['grill', 'bake', 'fry']
>>> d2
{'eggs': 3, 'spam': 2, 'ham': ['grill', 'bake', 'fry']}
>>> del d2['eggs']
>>> d2
{'spam': 2, 'ham': ['grill', 'bake', 'fry']}
Making dictionaries
# literals
>>> D = {'name': 'Bob', 'age': 42, 'job': 'dev'}
>>> D
{'job': 'dev', 'age': 42, 'name': 'Bob'}
# keywords
>>> D = dict(name='Bob', age=42, job='dev')
>>> D
{'job': 'dev', 'age': 42, 'name': 'Bob'}
# field by field
>>> D = {}
>>> D['name'] = 'Bob'
>>> D['age'] = 42
>>> D['job'] = 'dev'
>>> D
{'job': 'dev', 'age': 42, 'name': 'Bob'}
# zipped keys/values
>>> pairs = zip(['name', 'age', 'job'], ('Bob', 42, 'dev'))
>>> pairs
[('name', 'Bob'), ('age', 42), ('job', 'dev')]
>>> D = dict(pairs)
>>> D
{'job': 'dev', 'age': 42, 'name': 'Bob'}
# key lists
>>> D = dict.fromkeys(['name', 'age', 'job'], '?')
>>> D
{'job': '?', 'age': '?', 'name': '?'}
A language table
>>> table = {'Perl': 'Larry Wall',
... 'Tcl': 'John Ousterhout',
... 'Python': 'Guido van Rossum' }
...
>>> language = 'Python'
>>> creator = table[language]
>>> creator
'Guido van Rossum'
>>> for lang in table.keys(): print lang,
...
Tcl Python Perl
Dictionary usage notes
● Sequence operations don’t work!
● Assigning to new indexes adds entries
● Keys need not always be strings
Example: simulating auto-grown lists
>>> L = [] # L=[0]*100 would help
>>> L[99] = 'spam'
IndexError: list assignment index out of range
>>> D = {}
>>> D[99] = 'spam'
>>> D[99]
'spam'
>>> D
{99: 'spam'}
Example: dictionary-based “records”
>>> rec = {}
>>> rec['name'] = 'mel'
>>> rec['age'] = 40
>>> rec['job'] = 'trainer/writer'
>>>
>>> print rec['name']
mel
>>> mel = {'name': 'Mark',
... 'jobs': ['trainer', 'writer'],
... 'web': 'www.rmi.net/~lutz',
... 'home': {'state': 'CO', 'zip':80503}}
>>> mel['jobs']
['trainer', 'writer']
>>> mel['jobs'][1]
'writer'
>>> mel['home']['zip']
80503
Example: more object nesting
>>> rec = {'name': {'first': 'Bob', 'last': 'Smith'},
'job': ['dev', 'mgr'],
'age': 40.5}
>>>
>>> rec['name']
{'last': 'Smith', 'first': 'Bob'}
>>> rec['name']['last']
'Smith'
>>> rec['job'][-1]
'mgr'
>>> rec['job'].append('janitor')
>>> rec
{'age': 40.5, 'job': ['dev', 'mgr', 'janitor'], 'name': {'last': 'Smith', 'first': 'Bob'}}
>>> db = {}
>>> db['bob'] = rec # collecting records into a db
>>> db['sue'] = …
Preview: Bob could be a record
in a real database, using shelve or pickle persistence modules: watch
for more details on the class and database units. This nested dictionary/list structure is also
the genesis of JSON: see Python’s json standard library module
for a trivial translation utility, and the Database unit
for a simple example.
Example: dictionary-based sparse matrix
>>> Matrix = {}
>>> Matrix[(2,3,4)] = 88 # tuple key is coordinates
>>> Matrix[(7,8,9)] = 99
>>> X = 2; Y = 3; Z = 4 # ; separates statements
>>> Matrix[(X,Y,Z)]
88
>>> Matrix
{(2, 3, 4): 88, (7, 8, 9): 99}
>>> Matrix.get((0, 1, 2), 'Missing')
'Missing'
Tuples
♦ Arrays of object references
♦ Access by offset
♦ Fixed length, heterogeneous, arbitrarily nestable
♦ Category: ‘immutable sequences’ (can’t be changed)
♦ Ordered collections of arbitrary objects
Common tuple operations
|
Operation |
Interpretation |
|
() |
an
empty tuple |
|
T1 =
(0,) |
a
one-item tuple |
|
T2 =
(0, 1, 2, 3) |
a
4-item tuple |
|
T2 =
0, 1, 2, 3 |
another
4-item tuple |
|
T3 =
('abc', ('def', 'ghi')) |
nested
tuples |
|
T1[i],
t1[i:j], len(t1) |
index,
slice, length |
|
T1 +
t2, t2 * 3 |
concatenate,
repeat |
|
for
x in t2, 3 in t2 |
iteration/membership |
Tuples in action
>>> T1 = (1, 'spam')
>>> T2 = (2, 'ni')
>>> T1 + T2
(1, 'spam', 2, 'ni')
>>> T1 * 4
(1, 'spam', 1, 'spam', 1, 'spam', 1, 'spam')
>>> T2[1]
'ni'
>>> T2[1:]
('ni',)
Why lists and tuples?
● Immutability provides integrity
● Some built-in operations require tuples (argument lists)
● Guido was a mathematician: sets versus data structures
Files
♦ A wrapper around C’s “stdio” file system (io module in 3.X)
♦ The builtin ‘open’ function returns a file object
♦ File objects export methods for file operations
♦ Files are not sequences or mappings (methods only)
♦ Files are a built-in C extension type
About
3.X files: this section covers basic file
interfaces. See the Advanced
Topics section for coverage of 3.X distinction between text files—whose content is normal strings, may be passed a Unicode
encoding type, and perform automatic Unicode encoding/decoding on input/output;
and binary files—whose content is
bytes strings and do not perform Unicode encoding/decoding or line-end
translations. In 2.X, normal files are
the same as 3.X binary files (8-bit byte data), and the codecs module supports
Unicode file encodings like 3.X text files.
Common file operations
|
Operation |
Interpretation |
|
O =
open('/tmp/spam', 'w') |
create
output file |
|
I =
open('data', 'r') |
create
input file |
|
I.read(),
I.read(1) |
read
file, byte |
|
I.readline(),
I.readlines() |
read
line, lines list |
|
O.write(S),
O.writelines(L) |
write
string, lines |
|
O.close() |
manual
close (or on free) |
Files in action
# more at the end of the next section
>>> newfile = open('test.txt', 'w')
>>> newfile.write(('spam' * 5) + '\n')
>>> newfile.close()
>>> myfile = open('test.txt')
>>> text = myfile.read()
>>> text
'spamspamspamspamspam\n'
Related Python tools (day 2 or 3)
● Descriptor based files: os module
● DBM keyed files
● Persistent object shelves
●
Pipes, fifos, sockets
General
object properties
Type categories revisited
♦ Objects share operations according to their category
♦ Only mutable objects may be changed in-place
|
Object type |
Category |
Mutable? |
|
Numbers |
Numeric |
No |
|
Strings |
Sequence |
No |
|
Lists |
Sequence |
Yes |
|
Dictionaries |
Mapping |
Yes |
|
Tuples |
Sequence |
No |
|
Files |
Extension |
n/a |
Generality
♦ Lists, dictionaries, and tuples can hold any kind of object
♦ Lists, dictionaries, and tuples can be arbitrarily nested
♦ Lists and dictionaries can dynamically grow and shrink
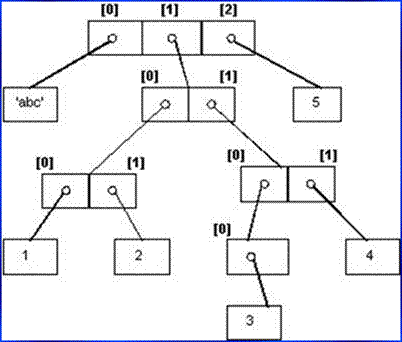
Nesting example
>>> L = ['abc', [(1, 2), ([3], 4)], 5]
>>> L[1][1]
([3], 4)
>>> L[1][1][0]
[3]
>>> L[1][1][0][0]
3
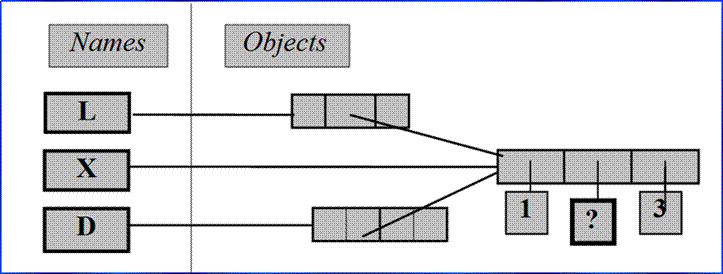
Shared references
♦ Assignments always create references to objects
♦ Can generate shared references to the same object
♦ Changing a mutable object impacts all references
♦ To avoid effect: make copies with X[:], list(X), etc.
♦ Tip: distinguish between names and objects!
► Names have no "type", but objects do
>>> X = [1, 2, 3]
>>> L = ['a', X, 'b']
>>> D = {'x':X, 'y':2}
>>> X[1] = 'surprise' # changes all 3 references!
>>> L
['a', [1, 'surprise', 3], 'b']
>>> D
{'x': [1, 'surprise', 3], 'y': 2}
Equality and truth
♦ Applied recursively for nested data structures
♦ ‘is’ tests identity (object address)
♦ True: non-zero number or non-empty data structure
♦ “None” is a special empty/false object
>>> L1 = [1, ('a', 3)] # same value, unique objects
>>> L3 = [1, ('a', 3)]
>>> L1 == L3, L1 is L3 # equivalent?, same object?
(True, False) # (True==1, False==0)
Other comparisons
♦ Applied recursively for nested data structures
♦ Strings compared lexicographically
♦ Lists and tuples compared depth-first, left-to-right
♦ Dictionaries compared by sorted (key, value) lists
♦ Disctionaries don’t compare in 3.X, but their .items() do
>>> L1 = [1, ('a', 3)]
>>> L2 = [1, ('a', 2)]
>>> L1 < L2, L1 == L2, L1 > L2
(False, False, True)
Summary:
Python’s type hierarchies
♦ Everything is an ‘object’ type in Python: “first class”
♦ Types are objects too: “type(X)” returns type object of X
♦ Preview: C extension modules and types use same mechanisms as Python types
How to break your code’s flexibility…
>>> L
= [1, 2, 3]
>>> if
type(L) == type([]):
print 'yes'
yes
>>> if
type(L) == list:
print 'yes'
yes
>>> if
isinstance(L, list):
print 'yes'
yes
Newer types
● Decimal, fraction (modules): see above
● Boolean (bool, True, False): see next section
● Sets: 2.4 (module in 2.3), 3.X/2.7 literal/comprehension
● Other extension types: namedtuple, collection (std lib)
>>> True + 2 # bool: True/False like 1/0 (next section)
3
Sets
>>> x = set('abcde') # set constructor
>>> y = set('bdxyz')
>>> x
set(['a', 'c', 'b', 'e', 'd'])
>>> 'e' in x # membership
True
>>> x – y # difference
set(['a', 'c', 'e'])
>>> x | y # union
set(['a', 'c', 'b', 'e', 'd', 'y', 'x', 'z'])
>>> x & y # intersection
set(['b', 'd'])
In Python 2.7 and 3.X
C:\class> py -3
>>> x = {'a', 'b', 'c', 'd'} # 3.X set literal
>>> {'b', 'd'} < x # subset test
True
>>> {ord(c) for c in 'spam'} # 3.X set comprehension (ahead)
{112, 97, 115, 109}
>>> {c: ord(c) for c in 'spam'} # 3.X dict comprehension (ahead)
{'m': 109, 'p': 112, 'a': 97, 's': 115}
Built-in
type gotchas
■ Assignment creates references, not copies
>>> L = [1, 2, 3]
>>> M = ['X', L, 'Y']
>>> M
['X', [1, 2, 3], 'Y']
>>> L[1] = 0
>>> M
['X', [1, 0, 3], 'Y']
■ Repetition adds 1-level deep
>>> L = [4, 5, 6]
>>> X = L * 4 # like [4, 5, 6] + [4, 5, 6] + ...
>>> Y = [L] * 4 # [L] + [L] + ... = [L, L,...]
>>> X
[4, 5, 6, 4, 5, 6, 4, 5, 6, 4, 5, 6]
>>> Y
[[4, 5, 6], [4, 5, 6], [4, 5, 6], [4, 5, 6]]
>>> L[1] = 0
>>> X
[4, 5, 6, 4, 5, 6, 4, 5, 6, 4, 5, 6]
>>> Y
[[4, 0, 6], [4, 0, 6], [4, 0, 6], [4, 0, 6]]
■ Cyclic structures print oddly (loop in 1.5)
>>> L = ['hi.']; L.append(L) # append reference to self
>>> L # dots=cycle today (no loop)
■ Immutable types can’t be changed in-place
T = (1, 2, 3)
T[2] = 4 # error!
T = T[:2] + (4,) # okay: (1, 2, 4)
Lab Session 2
Click here to go to
lab exercises
Click here to go to
exercise solutions
Click here to go to
solution source files
Click here to go to
lecture example files