This section lists solutions to some of the earlier lab's exercises, taken from the book Learning Python. Feel free to consult these answers if you get stuck, and also for pointers on alternative solutions.
Also see the solution file
directories for answers to additional lab sessions.
Lab 1: Using the
Interpreter
1.
Interaction.
Assuming your Python is configured properly, you should participate in an
interaction that looks something like the following. You can run this any way
you like: in IDLE, from a shell prompt, and so on.
Note: lines that start with a “%” denote shell-prompt command lines;
don’t run these lines at Python’s “>>>”
prompt, and don’t type either the “%”
or “>>>” characters yourself—enter
just the code after the these prompts.
Run “%” shell-prompt commands
in a Command Prompt window on Windows, and run “>>>” commands in Python (IDLE’s shell window, etc.). You don’t need to run the first command that
follows if you’re working only in IDLE, and you may need to use a full
“C:\Python35\python” instead of just “python” if Python isn’t on your system’s
PATH setting:
% python # "%" means your shell prompt (e.g., "C:\code>")
...copyright information lines...
>>> "Hello World!" # ">>>" is Python’s prompt: Python code goes here
'Hello World!'
>>> # Ctrl-D, Ctrl-Z, or window close to exit
2.
Programs. Here’s what your code (i.e., module) file and shell
interactions should look like; again, feel free to run this other ways—by
clicking its icon, by IDLE’s Edit/RunScript menu option, and so on:
Note: in this section a “File: xxx.py” in italics gives the name
of the file in which code following it is to be stored, and be sure to always
use the parenthesized call form “print(xxx)”
if you’re using Python 3.X (see the statements unit
for more details).
# File: module1.py #
enter this code in a new file
print 'Hello module world!' # 3.X: use the form print('…')
% python module1.py # run this command line at a system prompt
Hello module world!
3.
Modules. The
following interaction listing illustrates running a module file by importing
it. Remember that you need to reload it to run again without stopping and
restarting the interpreter. The bit about moving the file to a different
directory and importing it again is a trick question: if Python generates a module1.pyc file in the
original directory, it uses that when you import the module, even if the
source code file (.py) has been moved to a directory not on Python’s search
path. The .pyc file is written automatically if Python has access
to the source file’s directory and contains the compiled bytecode version of a
module. We look at how this works again in the modules unit.
% python
>>> import module1
Hello module world!
>>>
4.
Scripts.
Assuming your platform supports the #! trick, your solution will look like the following
(though your #! line may need to list another path on your machine):
File: module1.py
#!/usr/local/bin/python (or #!/usr/bin/env python)
print 'Hello module world!'
% chmod +x module1.py
% module1.py
Hello module world!
5.
Errors. The
interaction below demonstrates the sort of error messages you get if you complete
this exercise. Really, you’re triggering Python exceptions; the default exception
handling behavior terminates the running Python program and prints an error
message and stack trace on the screen. The stack trace shows where you were at
in a program when the exception occurred (it’s not very interesting here, since
the exceptions occur at the top level of the interactive prompt; no function
calls were in progress). In the exceptions unit, you will see that you can
catch exceptions using “try” statements and process them arbitrarily; you’ll
also see that Python includes a full-blown source-code debugger for special
error detection requirements. For now, notice that Python gives meaningful
messages when programming errors occur (instead of crashing silently):
% python
>>> 1 / 0
Traceback (innermost last):
File "<stdin>", line 1, in ?
ZeroDivisionError: integer division or modulo
>>>
>>> x
Traceback (innermost last):
File "<stdin>", line 1, in ?
NameError: x
6.
Breaks. When
you type this code:
L = [1, 2]
L.append(L)
you
create a cyclic data-structure in Python. In Python releases before Version
1.5.1, the Python printer wasn’t smart enough to detect cycles in objects, and
it would print an unending stream of [1, 2, [1, 2, [1,
2, [1, 2, and so on, until you hit the
break key combination on your machine (which, technically, raises a
keyboard-interrupt exception that prints a default message at the top level
unless you intercept it in a program). Beginning with Python Version 1.5.1, the
printer is clever enough to detect cycles and prints [[...]] instead to let you
know.
The
reason for the cycle is subtle and requires information you’ll gain in the next
unit. But in short, assignment in Python always generates references to objects
(which you can think of as implicitly followed pointers). When you run the
first assignment above, the name L becomes a named reference to a two-item list object.
Now, Python lists are really arrays of object references, with an append method that changes
the array in-place by tacking on another object reference. Here, the append call adds a
reference to the front of L at the end of L, which leads to the cycle illustrated in the figure
below. Believe it or not, cyclic data structures can sometimes be useful (but
maybe not when printed!). Today, Python can also reclaim (garbage collect) such
objects cyclic automatically.
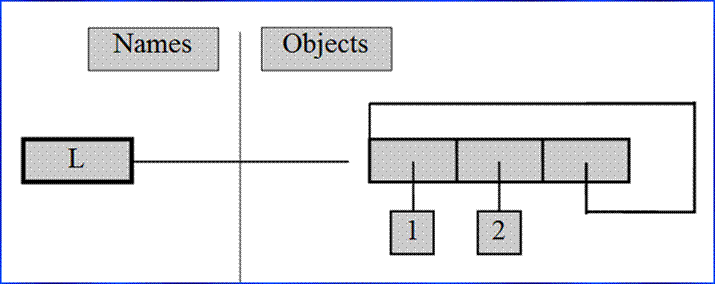
A cyclic list
Lab 2: Types and
Operators
1.
The basics.
Here are the sort of results you should get, along with a few comments about
their meaning. As noted in the exercises, “;” is used in a few of these to squeeze more than one
stamement on a single line (as we’ll learn in the next unit, the semicolon is a statement separator),
and comma-separated values display inside parenthesis, because they are really
a tuple.
Numbers
>>> 2 ** 16 # 2 raised to the power 16
65536
>>> 2 / 5, 2 / 5.0 # integer / truncates, float / doesn't
(0, 0.40000000000000002)
Strings
>>> "spam" + "eggs" # concatenation
'spameggs'
>>> S = "ham"
>>> "eggs " + S
'eggs ham'
>>> S * 5 #
repetition
'hamhamhamhamham'
>>> S[:0] # an empty slice at the
front--[0:0]
''
>>> "green %s and %s" % ("eggs", S) # formatting
'green eggs and ham'
Tuples
>>> ('x',)[0] # indexing a
single-item tuple
'x'
>>> ('x', 'y')[1] # indexing a 2-item tuple
'y'
Lists
>>> L = [1,2,3] + [4,5,6] # list operations
>>> L, L[:], L[:0], L[-2], L[-2:]
([1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 6], [], 5, [5, 6])
>>> ([1,2,3]+[4,5,6])[2:4]
[3, 4]
>>> [L[2], L[3]] # fetch from offsets,
store in a list
[3, 4]
>>> L.reverse();
L # method: reverse list in-place
[6, 5, 4, 3, 2, 1]
>>> L.sort(); L # method: sort list in-place
[1, 2, 3, 4, 5, 6]
>>> L.index(4) # method: offset of first 4 (search)
3
Dictionaries
>>> {'a':1, 'b':2}['b'] # index a dictionary by key
2
>>> D = {'x':1, 'y':2, 'z':3}
>>> D['w'] =
0 # create a new
entry
>>> D['x'] +
D['w']
1
>>> D[(1,2,3)] = 4 # a tuple used as a key (immutable)
>>> D
{'w': 0, 'z': 3, 'y': 2, (1, 2, 3): 4, 'x': 1}
>>> D.keys(), D.values(), D.has_key((1,2,3)) # methods (3.X:
has_key=>in)
(['w', 'z', 'y', (1, 2, 3), 'x'], [0, 3, 2, 4, 1], 1)
Empties
>>> [[]], ["",[],(),{},None] # lots of nothings: empty objects
([[]], ['', [], (), {}, None])
2.
Indexing and slicing.
Indexing out-of-bounds (e.g., L[4]) raises an error; Python always checks to make sure that all offsets are within the bounds of a sequence (unlike C, where out-of-bound indexes will happily crash your system).
On the other hand, slicing out of bounds (e.g., L[-1000:100]) works, because Python scales out-of-bounds slices so that they always fit (they’re set to zero and the sequence length, if required).
Extracting a sequence in reverse—with the lower bound > the higher bound (e.g., L[3:1])—doesn’t really work. You get back an empty slice ([]), because Python scales the slice limits to make sure that the lower bound is always less than or equal to the upper bound (e.g., L[3:1] is scaled to L[3:3], the empty insertion point at offset 3). Python slices are always extracted from left to right, even if you use negative indexes (they are first converted to positive indexes by adding the length).
>>> L = [1, 2, 3, 4]
>>> L[4]
Traceback (innermost last):
File "<stdin>", line 1, in ?
IndexError: list index out of range
>>> L[-1000:100]
[1, 2, 3, 4]
>>> L[3:1]
[]
>>> L
[1, 2, 3, 4]
>>> L[3:1] = ['?']
>>> L
[1, 2, 3, '?', 4]
3.
Indexing, slicing, and
>>> L = [1,2,3,4]
>>> L[2] = []
>>> L
[1, 2, [], 4]
>>> L[2:3] = []
>>> L
[1, 2, 4]
>>>
>>> L
[2, 4]
>>>
>>> L
[2]
>>> L[1:2] = 1
Traceback (innermost last):
File "<stdin>", line 1, in ?
TypeError: illegal argument type for built-in operation
4.
Tuple assignment. The values of X and Y
are swapped. When tuples appear on the left and right of an assignment symbol (=), Python assigns objects on
the right to targets on the left, according to their positions. This is
probably easiest to understand by noting that targets on the left aren’t a real
tuple, even though they look like one; they are simply a set of independent
assignment targets. The items on the right are a tuple, which get unpacked
during the assignment (the tuple provides the temporary assignment needed to
achieve the swap effect).
>>> X = 'spam'
>>> Y = 'eggs'
>>> X, Y = Y, X
>>> X
'eggs'
>>> Y
'spam'
5.
Dictionary keys. Any immutable object can be used as a dictionary key—integers, tuples,
strings, and so on. This really is a dictionary, even though some of its keys
look like integer offsets. Mixed type keys work fine too.
>>> D = {}
>>> D[1] = 'a'
>>> D[2] = 'b'
>>> D[(1, 2, 3)] = 'c'
>>> D
{1: 'a', 2: 'b', (1, 2, 3): 'c'}
6.
Dictionary indexing. Indexing a nonexistent key (D['d']) raises an error; assigning to a nonexistent key (D['d']='spam') creates a
new dictionary entry. On the other hand, out-of-bounds indexing for lists
raises an error too, but so do out-of-bounds assignments. Variable names work
like dictionary keys: they must have already been assigned when referenced, but
are created when first assigned. In fact, variable names can be processed as
dictionary keys if you wish (they’re made visible in module namespace or
stack-frame dictionaries).
>>> D = {'a':1, 'b':2, 'c':3}
>>> D['a']
1
>>> D['d']
Traceback (innermost last):
File "<stdin>", line 1, in ?
KeyError: d
>>> D['d'] = 4
>>> D
{'b': 2, 'd': 4, 'a': 1, 'c': 3}
>>>
>>> L = [0,1]
>>> L[2]
Traceback (innermost last):
File "<stdin>", line 1, in ?
IndexError: list index out of range
>>> L[2] = 3
Traceback (innermost last):
File "<stdin>", line 1, in ?
IndexError: list assignment index out of range
7.
Generic operations.
Question answers: The + operator doesn’t work on different/mixed types (e.g., string + list, list + tuple).
+ doesn’t work for dictionaries, because they aren’t sequences.
The append method works only for lists, not strings, and keys works only on dictionaries. append assumes its target is mutable, since it’s an in-place extension; strings are immutable.
Slicing and concatenation always return a new object of the same type as the objects processed.
>>> "x" + 1
Traceback (innermost last):
File "<stdin>", line 1, in ?
TypeError: illegal argument type for built-in operation
>>>
>>> {} + {}
Traceback (innermost last):
File "<stdin>", line 1, in ?
TypeError: bad operand type(s) for +
>>>
>>> [].append(9)
>>> "".append('s')
Traceback (innermost last):
File "<stdin>", line 1, in ?
AttributeError: attribute-less object
>>>
>>> {}.keys()
[]
>>> [].keys()
Traceback (innermost last):
File "<stdin>", line 1, in ?
AttributeError: keys
>>>
>>> [][:]
[]
>>> ""[:]
''
8.
String indexing. Since strings are collections of one-character strings, every time you
index a string, you get back a string, which can be indexed again. S[0][0][0][0][0] just keeps
indexing the first character over and over. This generally doesn’t work for
lists (lists can hold arbitrary objects), unless the list contains strings.
>>> S = "spam"
>>> S[0][0][0][0][0]
's'
>>> L = ['s', 'p']
>>> L[0][0][0]
's'
9.
Immutable types. Either of the solutions below work. Index assignment doesn’t, because strings
are immutable.
>>> S = "spam"
>>> S = S[0] + 'l' + S[2:]
>>> S
'slam'
>>> S = S[0] + 'l' + S[2] + S[3]
>>> S
'slam'
10.
Nesting.
Your mileage will vary.
>>> me = {'name':('mark', 'e', 'lutz'), 'age':'?', 'job':'engineer'}
>>> me['job']
'engineer'
>>> me['name'][2]
'lutz'
11.
Files.
Here’s one way to create and read back a text file in Python (ls is a Unix command; use dir on Windows):
File: maker.py
file = open('myfile.txt', 'w')
file.write('Hello file world!\n') # or: open().write()
file.close() # close not always needed
File: reader.py
file = open('myfile.txt', 'r')
print file.read() # or: print open().read()
% python maker.py
% python reader.py
Hello file world!
% ls -l myfile.txt
-rwxrwxrwa 1 0
0 19
12.
The dir function: Here’s what you get for lists; dictionaries do the same (but with
different method names). Note that the dir result expanded
in Python 2.2—you’ll see a large set of additional underscore names that
implement expression operators, and support the subclassing we’ll meet in the
classes unit. The __methods__ attribute disappeared in 2.2 as well, because it
wasn’t consistently implemented—use dir to to fetch
attribute lists today instead:
>>> [].__methods__
['append', 'count', 'index', 'insert', 'remove', 'reverse', 'sort',…]
>>> dir([])
['append', 'count', 'index', 'insert', 'remove', 'reverse', 'sort',…]
Lab 3: Basic
Statements
1. Coding basic loops. If you work through this exercise, you'll wind up with code that looks something like the following:
>>> S = 'spam'
>>> for c in S:
... print ord(c)
...
115
112
97
109
>>> x = 0
>>> for c in S: x = x + ord(c) # or: x += ord(c)
...
>>> x
433
>>> x = []
>>> for c in S: x.append(ord(c))
...
>>> x
[115, 112, 97, 109]
>>> map(ord, S)
[115, 112, 97, 109]
2. Backslash characters. The example prints the bell character (\a) 50 times; assuming your machine can handle it, you'll get a series of beeps (or one long tone, if your machine is fast enough). Hey—I warned you.
3. Sorting dictionaries. Here's one way to work through this exercise; see lecture 3 if this doesn't make sense. Remember, you really do have to split the keys and sort calls up like this, because sort returns None.
>>> D = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5, 'f':6, 'g':7}
>>> D
{'f': 6, 'c': 3, 'a': 1, 'g': 7, 'e': 5, 'd': 4, 'b': 2}
>>>
>>> keys = D.keys()
>>> keys.sort()
>>> for key in keys:
... print key, '=>', D[key]
...
a => 1
b => 2
c => 3
d => 4
e => 5
f => 6
g => 7
4. Program logic alternatives. Here's how we coded the solutions; your results may vary a bit. This exercise is mostly just designed to get you playing with code alternaives, so anything reasonable gets full credit:
a) First, rewrite this code with a while loop else, to eliminate the found flag and final if statement.
L = [1, 2, 4, 8, 16, 32, 64]
X = 5
i = 0
while i < len(L):
if 2 ** X == L[i]:
print 'at index', i
break
i = i+1
else:
print X, 'not found'
b) Next, rewrite the example to use a for loop with an else, to eliminate the explicit list indexing logic. Hint: to get the index of an item, use the list index method (list.index(X) returns the offset of the first X).
L = [1, 2, 4, 8, 16, 32, 64]
X = 5
for p in L:
if (2 ** X) == p:
print (2 ** X), 'was found at', L.index(p)
break
else:
print X, 'not found'
c) Now, remove the loop completely by rewriting the examples with a simple in operator membership expression (see lecture 2 for more details, or type this: 2 in [1,2,3]).
L = [1, 2, 4, 8, 16, 32, 64]
X = 5
if (2 ** X) in L:
print (2 ** X), 'was found at', L.index(2 ** X)
else:
print X, 'not found'
d) Finally, use a for loop and the list append method to generate the powers-of-2 list (L), instead of hard-coding a list constant.
X = 5
L = []
for i in range(7): L.append(2 ** i)
print L
if (2 ** X) in L:
print (2 ** X), 'was found at', L.index(2 ** X)
else:
print X, 'not found'
e) Deeper thoughts: (2) As we saw in exercise 1, Python also provides a map(function, list) built-in tool which could be used to generate the powers-of-2 list too. Consider this a preview of the next lecture.
X = 5
L = map(lambda x: 2**x, range(7))
print L
if (2 ** X) in L:
print (2 ** X), 'was found at', L.index(2 ** X)
else:
print X, 'not found'
Lab 4: Functions
1.
Basics. There’s
not much to this one, but notice that your using the big “P” word—print (and hence your
function) is technically a polymorphic
operation, which does the right thing for each type of object:
% python
>>> def func(x): print x
...
>>> func("spam")
spam
>>> func(42)
42
>>> func([1, 2, 3])
[1, 2, 3]
>>> func({'food': 'spam'})
{'food': 'spam'}
2.
Arguments.
Here’s what one solution looks like. Remember that you have to use print to see results in the
test calls, because a file isn’t the same as code typed interactively; Python
doesn’t normally echo the results of expression statements in files.
File: mod.py
def adder(x, y):
return x + y
print adder(2, 3)
print adder('spam', 'eggs')
print adder(['a', 'b'], ['c', 'd'])
% python mod.py
5
spameggs
['a', 'b', 'c', 'd']
3.
Varargs. Two
alternative adder functions are shown in the following code. The hard part here
is figuring out how to initialize an accumulator to an empty value of whatever
type is passed in. In the first solution, we use manual type testing to look
for an integer and an empty slice of the first argument (assumed to be a
sequence) otherwise. In the second solution, we just use the first argument to
initialize and scan items 2 and beyond, much like one of the max function coded in
class.
The second solution is better (and frankly, comes from
students in a Python course I taught, who were frustrated with trying to
understand the first solution). Both of these assume all arguments are the same
type and neither works on dictionaries; as we saw a priore unit, + doesn’t work on mixed
types or dictionaries. We could add a type test and special code to add
dictionaries too, but that’s extra credit.
File adders.py
def adder1(*args):
print 'adder1',
if type(args[0]) == type(0): # integer?
sum = 0 # init to zero
else: # else sequence:
sum = args[0][:0] # use empty slice of arg1
for arg in args:
sum = sum + arg
return sum
def adder2(*args):
print 'adder2',
sum = args[0] # init to arg1
for next in args[1:]:
sum = sum + next # add items 2..N
return sum
for func in (adder1, adder2):
print func(2, 3, 4)
print func('spam', 'eggs', 'toast')
print func(['a', 'b'], ['c', 'd'], ['e', 'f'])
% python adders.py
adder1 9
adder1 spameggstoast
adder1 ['a', 'b', 'c', 'd', 'e', 'f']
adder2 9
adder2 spameggstoast
adder2 ['a', 'b', 'c', 'd', 'e', 'f']
4.
Keywords.
Here is our solution to the first part of this one. To iterate over keyword
arguments, use a **args form in the function header and use a loop like: for x in args.keys(): use args[x].
File: mod.py
def adder(good=1, bad=2, ugly=3):
return good + bad + ugly
print adder()
print adder(5)
print adder(5, 6)
print adder(5, 6, 7)
print adder(ugly=7, good=6, bad=5)
% python mod.py
6
10
14
18
18
5.
and 6. Here are
our solutions to Exercises 5 and 6. These are just coding exercises, though, because
Python has already made them superfluous—Python 1.5 added new dictionary
methods, to do things like copying and adding (merging) dictionaries: D.copy(), and D1.update(D2). See Python’s library manual or the Python Pocket
Reference for more details. X[:] doesn’t work for dictionaries, since they’re not
sequences. Also remember that if we assign (e = d) rather than copy, we generate a reference to a shared dictionary object; changing d changes e too.
File: dicts.py
def copyDict(old):
new = {}
for key in old.keys():
new[key] = old[key]
return new
def addDict(d1, d2):
new = {}
for key in d1.keys():
new[key] = d1[key]
for key in d2.keys():
new[key] = d2[key]
return new
% python
>>> from dicts import *
>>> d = {1:1, 2:2}
>>> e = copyDict(d)
>>> d[2] = '?'
>>> d
{1: 1, 2: '?'}
>>> e
{1: 1, 2: 2}
>>> x = {1:1}
>>> y = {2:2}
>>> z = addDict(x, y)
>>> z
{1: 1, 2: 2}
7.
Argument matching. Here is the sort of interaction you should get, along with comments that
explain the matching that goes on:
def f1(a, b): print a, b # normal args
def f2(a, *b): print a, b # positional varargs
def f3(a, **b): print a, b # keyword varargs
def f4(a, *b, **c): print a, b, c # mixed modes
def f5(a, b=2, c=3): print a, b, c # defaults
def f6(a, b=2, *c): print a, b, c # defaults + positional varargs
% python
>>> f1(1, 2) # matched by position (order matters)
1 2
>>> f1(b=2, a=1) # matched by name (order doesn't matter)
1 2
>>> f2(1, 2, 3) # extra positionals collected in a tuple
1 (2, 3)
>>> f3(1, x=2, y=3) # extra keywords collected in a dictionary
1 {'x': 2, 'y': 3}
>>> f4(1, 2, 3, x=2, y=3) # extra of both kinds
1 (2, 3) {'x': 2, 'y': 3}
>>> f5(1) # both defaults kick in
1 2 3
>>> f5(1, 4) # only one default used
1 4 3
>>> f6(1) # one argument: matches "a"
1 2 ()
>>> f6(1, 3, 4) # extra positional collected
1 3 (4,)
8. List comprehensions. Here is the sort of code you should write; we may have a preference, but we’re not telling.
>>> values = [2, 4, 9, 16, 25]
>>> import math
>>>
>>> res = []
>>> for x in values: res.append(math.sqrt(x))
...
>>> res
[1.4142135623730951, 2.0, 3.0, 4.0, 5.0]
>>>
>>> map(math.sqrt, values)
[1.4142135623730951, 2.0, 3.0, 4.0, 5.0]
>>>
>>> [math.sqrt(x) for x in values]
[1.4142135623730951, 2.0, 3.0, 4.0, 5.0]
Lab 5: Modules
1.
Basics, import. This one is simpler than you may think. When you’re done, your file and
interaction should look close to the following code; remember that Python can
read a whole file into a string or lines list, and the len built-in returns the length of strings and lists:
File: mymod.py
def countLines(name):
file = open(name, 'r')
return len(file.readlines())
def countChars(name):
return len(open(name, 'r').read())
def test(name): # or pass file object
return countLines(name), countChars(name) # or return a dictionary
% python
>>> import mymod
>>> mymod.test('mymod.py')
(10, 291)
On
Unix, you can verify your output with a wc command; on Windows, right-click on your
file to views its properties. (But note that your script may report fewer
characters than Windows does—for portability, Python converts Windows “\r\n”
line-end markers to “\n”, thereby dropping one byte (character) per line. To
match byte counts with Windows exactly, you have to open in binary mode—"rb", or add back the number of lines.)
Incidentally,
to do the “ambitious” part (passing in a file object, so you only open the file
once), you’ll probably need to use the seek method of the built-in file object. We didn’t cover
it in the text, but it works just like C’s fseek call (and
calls it behind the scenes): seek resets the current position in the file to an offset
passed in. After a seek, future input/output operations are relative to the
new position. To rewind to the start of a file without closing and reopening,
call file.seek(0); the file read methods all pick up at
the current position in the file, so you need to rewind to reread. Here’s what
this tweak would look like:
File: mymod2.py
def countLines(file):
file.seek(0) # rewind to start of file
return len(file.readlines())
def countChars(file):
file.seek(0) # ditto (rewind if needed)
return len(file.read())
def test(name):
file = open(name, 'r') # pass file object
return countLines(file), countChars(file) # only open file once
>>> import mymod2
>>> mymod2.test("mymod2.py")
(11, 392)
2.
from/from*.
Here’s the from* bit; replace * with countChars to do the rest:
% python
>>> from mymod import *
>>> countChars("mymod.py")
291
3.
__main__. If you code it properly, it works in either mode
(program run or module import):
File: mymod.py
def countLines(name):
file = open(name, 'r')
return len(file.readlines())
def countChars(name):
return len(open(name, 'r').read())
def test(name): # or pass file object
return countLines(name), countChars(name) # or return a dictionary
if __name__ == '__main__':
print test('mymod.py')
% python mymod.py
(13, 346)
4.
Nested imports. Our solution for this appears below:
File: myclient.py
from mymod import countLines, countChars
print countLines('mymod.py'), countChars('mymod.py')
% python myclient.py
13 346
As
for the rest of this one: mymod’s
functions are accessible (that is, importable) from the top level of myclient, since from simply assigns to names in the importer (it works almost as though mymod’s defs appeared in myclient). For
example, another file can say this:
import myclient
myclient.countLines(…)
from myclient import countChars
countChars(…)
If myclient used import instead of from, you’d need to use a path to get to the functions in mymod through myclient:
import myclient
myclient.mymod.countLines(…)
from myclient import mymod
mymod.countChars(…)
In
general, you can define collector
modules that import all the names from other modules, so they’re available in a
single convenience module. Using the following code, you wind up with three
different copies of name somename: mod1.somename, collector.somename, and __main__.somename; all three
share the same integer object initially, and only the name somename exists at the interative prompt as is:
File: mod1.py
somename = 42
File: collector.py
from mod1 import * # collect lots of names here
from mod2 import * # from assigns to my names
from mod3 import *
>>> from collector import somename
5.
Package imports. For this, we put the mymod.py solution file listed for exercise 3 into a directory
package. The following is what we did to set up the directory and its required __init__.py file in a
Windows console interface; you’ll need to interpolate for other platforms
(e.g., use mv
and vi instead
of move and edit). This works in any
directory (we just happened to run our commands in Python’s install directory),
and you can do some of this from a file explorer GUI too.
When we were done, we had a mypkg subdirectory,
which contained files __init__.py and mymod.py. You need an __init__.py in the mypkg directory, but not in its parent; mypkg is located in the home directory component of the module search path.
Notice how a print statement we coded in the directory’s initialization file only fires the
first time it is imported, not the second:
C:\python22> mkdir mypkg
C:\Python22> move mymod.py mypkg\mymod.py
C:\Python22> edit mypkg\__init__.py
…coded a print statement…
C:\Python22> python
>> import mypkg.mymod
initializing mypkg
>>> mypkg.mymod.countLines('mypkg\mymod.py')
13
>>> from mypkg.mymod import countChars
>>> countChars('mypkg\mymod.py')
346
6.
Reload. This
exercise just asks you to experiment with changing the changer.py example in the book,
so there’s not much for us to show here. If you had some fun with it, give
yourself extra points.
7.
Circular imports. The short story is that importing recur2 first works, because the recursive import then
happens at the import in recur1, not at a from in recur2.
The long
story goes like this: importing recur2 first works, because the recursive import from recur1 to recur2 fetches recur2 as a whole, instead
of getting specific names. recur2 is incomplete when imported from recur1, but because it uses
import instead
of from,
you’re safe: Python finds and returns the already created recur2 module object and
continues to run the rest of recur1 without a glitch. When the recur2 import resumes, the
second from
finds name Y
in recur1
(it’s been run completely), so no error is reported. Running a file as a script
is not the same as importing it as a module; these cases are the same as
running the first import or from in the script interactively. For instance, running recur1 as a script is the
same as importing recur2 interactively, since recur2 is the first module imported in recur1. (E-I-E-I-O!)
Lab 6: Classes
1.
Inheritance.
Here’s the solution we coded up for this exercise, along with some interactive
tests. The __add__ overload has to appear only once, in the superclass, since it invokes
type-specific add methods in subclasses.
File: adder.py
class Adder:
def add(self, x, y):
print 'not implemented!'
def __init__(self, start=[]):
self.data = start
def __add__(self, other): # or in subclasses?
return self.add(self.data, other) # or return type?
class ListAdder(Adder):
def add(self, x, y):
return x + y
class DictAdder(Adder):
def add(self, x, y):
new = {}
for k in x.keys(): new[k] = x[k]
for k in y.keys(): new[k] = y[k]
return new
% python
>>> from adder import *
>>> x = Adder()
>>> x.add(1, 2)
not implemented!
>>> x = ListAdder()
>>> x.add([1], [2])
[1, 2]
>>> x = DictAdder()
>>> x.add({1:1},
{2:2})
{1: 1, 2: 2}
>>> x = Adder([1])
>>> x + [2]
not implemented!
>>>
>>> x = ListAdder([1])
>>> x + [2]
[1, 2]
>>> [2] + x
Traceback (innermost last):
File "<stdin>", line 1, in ?
TypeError: __add__ nor __radd__ defined for these operands
Notice in the last test that you get an error for
expressions where a class instance appears on the right of a +; if you want to fix this,
use __radd__ methods as described in this unit’s operator
overloading section.
As we suggested, if you are saving a value in the
instance anyhow, you might as well rewrite the add method to take just one arguments, in the spirit of
other examples in this unit:
class Adder:
def __init__(self, start=[]):
self.data = start
def __add__(self, other): # pass a single argument
return self.add(other) # the left side is in self
def add(self, y):
print 'not implemented!'
class ListAdder(Adder):
def add(self, y):
return self.data + y
class DictAdder(Adder):
def add(self, y):
pass # change me to use self.data instead of x
x = ListAdder([1,2,3])
y = x + [4,5,6]
print y # prints [1, 2, 3, 4, 5, 6]
Because values are attached to objects rather than passed around, this version is arguably more object-oriented. And once you’ve gotten to this point, you’ll probably see that you could get rid of add altogether, and simply define type-specific __add__ methods in the two subclasses. They’re called exercises for a reason!
2.
Operator overloading. Here’s what we came up with for this one. It uses a few operator
overload methods we didn’t say much about, but they should be straightforward
to understand. Copying the initial value in the constructor is important,
because it may be mutable; you don’t want to change or have a reference to an
object that’s possibly shared somewhere outside the class. The __getattr__ method routes calls to the wrapped list. For hints on
an easier way to code this as of Python 2.2, see this unit’s section on
extending built-in types with subclasses.
File: mylist.py
class MyList:
def __init__(self, start):
#self.wrapped = start[:] # copy start: no side effects
self.wrapped = [] # make sure it's a list here
for x in start: self.wrapped.append(x)
def __add__(self, other):
return MyList(self.wrapped + other)
def __mul__(self, time):
return MyList(self.wrapped * time)
def __getitem__(self, offset):
return self.wrapped[offset]
def __len__(self):
return len(self.wrapped)
def __getslice__(self, low, high):
return MyList(self.wrapped[low:high])
def append(self, node):
self.wrapped.append(node)
def __getattr__(self, name): # other members: sort/reverse/etc.
return getattr(self.wrapped, name)
def __repr__(self):
return `self.wrapped` # 3.X: use repr(self.wrapped)
if __name__ == '__main__':
x = MyList('spam')
print x
print x[2]
print x[1:]
print x + ['eggs']
print x * 3
x.append('a')
x.sort()
for c in x: print c,
% python mylist.py
['s', 'p', 'a', 'm']
a
['p', 'a', 'm']
['s', 'p', 'a', 'm', 'eggs']
['s', 'p', 'a', 'm', 's', 'p', 'a', 'm', 's', 'p', 'a', 'm']
a a m p s
3.
Subclassing.
Our solution appears below. Your solution should appear similar.
File: mysub.py
from mylist import MyList
class MyListSub(MyList):
calls = 0 # shared by instances
def __init__(self, start):
self.adds = 0 # varies in each instance
MyList.__init__(self, start)
def __add__(self, other):
MyListSub.calls = MyListSub.calls + 1 # class-wide counter
self.adds = self.adds + 1 # per instance counts
return MyList.__add__(self, other)
def stats(self):
return self.calls, self.adds # all adds, my adds
if __name__ == '__main__':
x = MyListSub('spam')
y = MyListSub('foo')
print x[2]
print x[1:]
print x + ['eggs']
print x + ['toast']
print y + ['bar']
print x.stats()
% python mysub.py
a
['p', 'a', 'm']
['s', 'p', 'a', 'm', 'eggs']
['s', 'p', 'a', 'm', 'toast']
['f', 'o', 'o', 'bar']
(3, 2)
4.
Metaclass methods. We worked through this exercise as follows. Notice that operators try to
fetch attributes through __getattr__ too; you need to return a value to make them work.
>>> class
... def __getattr__(self, name):
... print 'get',
name
... def __setattr__(self, name, value):
... print 'set',
name, value
...
>>> x =
>>> x.append
get append
>>> x.spam = "pork"
set spam pork
>>>
>>> x + 2
get __coerce__
Traceback (innermost last):
File "<stdin>", line 1, in ?
TypeError: call of non-function
>>>
>>> x[1]
get __getitem__
Traceback (innermost last):
File "<stdin>", line 1, in ?
TypeError: call of non-function
>>> x[1:5]
get __len__
Traceback (innermost last):
File "<stdin>", line 1, in ?
TypeError: call of non-function
5.
Set objects.
Here’s the sort of interaction you should get; comments explain which methods
are called.
% python
>>> from setwrapper import Set
>>> x = Set([1,2,3,4]) # runs __init__
>>> y = Set([3,4,5])
>>> x & y
# __and__, intersect, then __repr__
Set:[3, 4]
>>> x | y # __or__, union, then __repr__
Set:[1, 2, 3, 4, 5]
>>> z = Set("hello") # __init__ removes duplicates
>>> z[0], z[-1] # __getitem__
('h', 'o')
>>> for c in z: print c, # __getitem__
...
h e l o
>>> len(z),
z # __len__, __repr__
(4, Set:['h', 'e', 'l', 'o'])
>>> z & "mello", z | "mello"
(Set:['e', 'l', 'o'], Set:['h', 'e', 'l', 'o', 'm'])
Our solution
to the multiple-operand extension subclass looks like the class below. It needs
only to replace two methods in the original set. The class’s documentation
string explains how it works:
File: multiset.py
from setwrapper import Set
class MultiSet(Set):
"""
inherits all Set names, but extends intersect
and union to support multiple operands; note
that "self" is still the first argument (stored
in the *args argument now); also note that the
inherited & and | operators call the new methods
here with 2 arguments, but processing more than
2 requires a method call, not an expression:
"""
def intersect(self, *others):
res = []
for x in self: # scan first sequence
for other in others: # for all other args
if x not in other: break # item in each one?
else: # no: break out of loop
res.append(x) # yes: add item to end
return Set(res)
def union(*args): # self is args[0]
res = []
for seq in args: # for all args
for x in seq: # for all nodes
if not x in res:
res.append(x) # add new items to result
return Set(res)
Your
interaction with the extension will be something along the following lines.
Note that you can intersect by using & or calling intersect, but must call intersect for three or more operands; & is a binary
(two-sided) operator. Also note that we could have called MutiSet simply Set to make this change more transparent. if we used setwrapper.Set to refer to the original within multiset:
>>> from multiset import *
>>> x = MultiSet([1,2,3,4])
>>> y = MultiSet([3,4,5])
>>> z = MultiSet([0,1,2])
>>> x & y, x | y # 2 operands
(Set:[3, 4], Set:[1, 2, 3, 4, 5])
>>> x.intersect(y, z) # 3 operands
Set:[]
>>> x.union(y,
z)
Set:[1, 2, 3, 4, 5, 0]
>>> x.intersect([1,2,3], [2,3,4], [1,2,3]) # 4 operands
Set:[2, 3]
>>> x.union(range(10)) # non-MultiSets work too
Set:[1, 2, 3, 4, 0, 5, 6, 7, 8, 9]
6.
Composition.
Our solution is below, with comments from the description mixed in with the
code. This is one case where it’s probably easier to express a problem in
Python than it is in English:
File: lunch.py
class Lunch:
def __init__(self): # make/embed Customer and Employee
self.cust = Customer()
self.empl = Employee()
def order(self, foodName): # start a Customer order simulation
self.cust.placeOrder(foodName, self.empl)
def result(self): # ask the Customer about its Food
self.cust.printFood()
class Customer:
def __init__(self): # initialize my food to None
self.food = None
def placeOrder(self, foodName, employee): # place order with Employee
self.food = employee.takeOrder(foodName)
def printFood(self): # print the name of my food
print self.food.name
class Employee:
def takeOrder(self, foodName): # return a Food, with requested name
return Food(foodName)
class Food:
def __init__(self, name): # store food name
self.name = name
if __name__ == '__main__':
x = Lunch() # self-test code
x.order('burritos') # if run, not imported
x.result()
x.order('pizza')
x.result()
% python lunch.py
burritos
pizza
7. Zoo Animal Hierarchy. Here is the way we coded the taxonomy on Python; it’s artificial, but the general coding pattern applies to many real structures—form GUIs to employee databases. Notice that the self.speak reference in Animal triggers an independent inheritance search, which finds speak in a subclass. Test this interactively per the exercise description. For more fun, try extending this hierarchy with new classes, and making instances of various classes in the tree:
File: zoo.py
class Animal:
def reply(self): self.speak() # back to subclass
def speak(self): print 'spam' # custom message
class Mammal(Animal):
def speak(self): print 'huh?'
class Cat(Mammal):
def speak(self): print 'meow'
class Dog(Mammal):
def speak(self): print 'bark'
class Primate(Mammal):
def speak(self): print 'Hello world!'
class Hacker(Primate): pass # inherit from Primate
8. The Dead Parrot Skit. Here’s how we implemented this one. Notice how the line method in the Actor superclass works: be accessing self attributes twice, it sends Python back to the instance twice, and hence invokes two inheritance searches—self.name and self.says() find information in the specific subclasses. We’ll leave rounding this out to include the complete text of the Monty Python skit as a suggested exercise:
File: parrot.py
class Actor:
def line(self): print self.name + ':', repr(self.says())
class Customer(Actor):
name = 'customer'
def says(self): return "that's one ex-bird!"
class Clerk(Actor):
name = 'clerk'
def says(self): return "no it isn't..."
class Parrot(Actor):
name = 'parrot'
def says(self): return None
class Scene:
def __init__(self):
self.clerk = Clerk() # embed some instances
self.customer = Customer() # Scene is a composite
self.subject = Parrot()
def action(self):
self.customer.line() # delegate to embedded
self.clerk.line()
self.subject.line()
Lab 7: Exceptions and
built-in tools
1.
try/except.
Our version of the oops function follows. As for the noncoding questions,
changing oops
to raise KeyError instead of IndexError means
that the exception won’t be caught by our try handler (it “percolates” to the top level and
triggers Python’s default error message). The names KeyError and IndexError come from the outermost built-in names scope. If you
don’t believe us, import __builtin__ and pass it as an argument to the dir function to see for yourself.
File: oops.py
def oops():
raise IndexError
def doomed():
try:
oops()
except IndexError:
print 'caught an index error!'
else:
print 'no error caught...'
if __name__ == '__main__': doomed()
% python oops.py
caught an index error!
2.
Exception objects and lists. Here’s the way we extended this module for an
exception of our own (here a string, at first):
File: oops.py
MyError = 'hello'
def oops():
raise MyError, 'world'
def doomed():
try:
oops()
except IndexError:
print 'caught an index error!'
except MyError, data:
print 'caught error:', MyError, data
else:
print 'no error caught...'
if __name__ == '__main__':
doomed()
% python oops.py
caught error: hello world
To identify the exception with a class, we just changed the first part of the file to this:
File: oop_oops.py
class MyError: pass
def oops():
raise MyError()
…rest unchanged…
Like all class exceptions, the instance comes back as the extra data; our error message now shows both the class, and its instance (<…>).
% python oop_oops.py
caught error: __main__.MyError <__main__.MyError instance at 0x00867550>
Remember, to make this look nicer, you can define a __repr__ method in your class to return a custom print string; see the unit for details.
3.
Error handling. Finally, here’s one way to solve this one; we decided to do our tests in
a file, rather than interactively, but the results are about the same.
File: safe2.py
import sys, traceback
def safe(entry, *args):
try:
entry(*args) # was “apply(entry, args)” -- catch everything else
except:
traceback.print_exc()
print 'Got', sys.exc_info()[0], sys.exc_info()[1] # type, value
import oops
safe(oops.oops)
% python safe2.py
Traceback (innermost last):
File "safe2.py", line 5, in safe
apply(entry, args) # catch everything else
File "oops.py", line 4, in oops
raise MyError, 'world'
hello: world
Got hello world
Also see the solution file
directories for answers to additional lab sessions.