The lab exercises below ask students to write original programs, as well as modify pre-coded examples. Later exercises demonstrate more advanced concepts and tools: simple [tT]kinter GUIs, C integration, etc. The final lab also points users to online Python resources (the web page, etc.), provided the lab machines have Internet access. Lecture examples source-code, as well as answers to lab exercises, are provided on this CD; click on the links in this paragraph to go to these resources, or ask the instructor for assistance.
Note: don’t expect to finish all the questions in each lab. Some of these exercises are more involved than others, and most of the labs have more exercises than you’ll probably be able to finish in a half or full hour. Students are encouraged to skip around if they find they need more or less time for some questions. Feel free to return to prior labs at any time, regardless of where we are at in the lecture schedule.
Lab 1: Using the interpreter
1.
Interaction.
Using a system command-line, IDLE, or other, start the Python interactive
command line (>>> prompt), and type the expression: "Hello World!" (including
the quotes). The string should be echoed back to you. The purpose of this
exercise is to get your environment configured to run Python. In some
scenarios, you may need to first run a cd shell
command, type the full path to the python
executable, or add its path to your
2.
Programs.
With the text editor of your choice, write a simple module file—a file containing
the single statement: print 'Hello module world!'. Store this statement in a file named module1.py. Now, run this
file by using any launch option you like: running it in IDLE, clicking on its
file icon, passing it to the Python interpreter program on the system shell’s
command line, and so on. In fact, experiment by running your file with as many
of the launch techniques we’ve seen in this unit as you can. Which technique
seems easiest (there is no right answer to this one, of course)?
3.
Modules.
Next, start the Python interactive command line (>>> prompt) and
import the module you wrote in the prior exercise. Does your PYTHONPATH setting need to
include the directory where the file is stored? Try moving the file to a
different directory and importing it again from its original directory; what
happens? (Hint: is there still a file named module1.pyc in the original directory?)
4.
Scripts. If
your platform supports it, add the #! line to the top of your module1.py module, give the file executable privileges, and run
it directly as an executable. What does the first line need to contain? Skip
that if you are working on a Windows machine (#! usually only has meaning on Unix and Linux); instead
try running your file by listing just its name in a DOS console window (this
works on recent flavors of Windows), or the “Start/Run…” dialog box.
5.
Errors.
Experiment with typing mathematical expressions and assignments at the Python
interactive command line. First type the expression: 1 / 0; what happens? Next,
type a variable name you haven’t assigned a value to yet; what happens this
time?
You may not know it yet, but you’re doing exception
processing, a topic we’ll explore in depth in a later unit. As we’ll learn
then, you are technically triggering what’s known as the default exception handler—logic that prints a standard error
message.
For
full-blown source-code debugging
chores, IDLE includes a GUI debugging interface (select Debug before running
your script), and a Python standard library module named pdb provides a command-line debugging interface (more on pdb later). When first starting out, though, Python’s default error messages
will probably be as much error handling as you need—they give the cause of the
error, as well as the lines in your code were active when the error occurred.
6.
Breaks. At
the Python command line, type:
L = [1, 2]
L.append(L)
L
What happens? If you’re using a Python newer than
release 1.5, you’ll probably see a strange output. If you’re using a Python
version older than 1.5.1 (now ancient history!), a Ctrl-C key combination will
probably help on most platforms. Why do you think this occurs? What does Python
report when you type the Ctrl-C key combination? Warning: if you do have a
Python older than release 1.5.1, make sure your machine can stop a program with
a break-key combination of some sort before running this test, or you may be
waiting a long time.
7.
Documentation. Spend at least 6 minutes browsing the Python library and language
manuals before moving on, to get a feel for the available tools in the standard
library, and the structure of the documentation set. It takes at least this
long to become familiar with the location of major topics in the manual set;
once you do, though, it’s easy to find what you need. You can find this manual
in the Python “Start” button entry on Windows, in the “Help” pulldown menu in
IDLE, or online at www.python.org. We’ll
also have a few more words to say about the manuals, and other documentation
sources available (including PyDoc and the help function), in the statements unit. If you still have time
to kill, go explore the Python website (www.python.org),
and the Vaults of Parnassus site.
Especially check out the python.org documentation and search pages; they
can be crucial resources in practice.
Lab 2: Types and operators
If you have limited time, start with
exercise 11 (the most practical), and then work from first to last as time
allows. This is all fundamental material, though, so try to do as many of these
as you can.
1.
The basics.
Experiment interactively with the common type operations found in this unit’s
tables. To get you started, bring up the Python interactive interpreter, type
the expressions below, and try to explain what’s happening in each case. As we’ll see in the next unit, “;” is a
statement separator, used here to cram multiple statements onto one line (e.g.,
to change and then print). Also, as
described in this unit, multiple values separated by “,” are displayed inside
“(…)” because they really form a tuple—even if you omit the parentheses
yourself.
2 ** 16
2 / 5, 2 / 5.0
"spam" + "eggs"
S = "ham"
"eggs " + S
S * 5
S[:0]
"green %s and %s" % ("eggs", S)
('x',)[0]
('x', 'y')[1]
L = [1,2,3] + [4,5,6]
L, L[:], L[:0], L[-2], L[-2:]
([1,2,3] + [4,5,6])[2:4]
[L[2], L[3]]
L.reverse(); L
L.sort(); L
L.index(4)
{'a':1, 'b':2}['b']
D = {'x':1, 'y':2, 'z':3}
D['w'] = 0
D['x'] + D['w']
D[(1,2,3)] = 4
D.keys(), D.values(), D.has_key((1,2,3)) # 3.X: has_key => (1,2,3) in D
[[]], ["",[],(),{},None]
2.
Indexing and slicing. At the interactive prompt, define a list named L that contains four
strings or numbers (e.g., L=[0,1,2,3]). Now, let’s experiment with some boundary cases.
a) What happens when you try to index out of bounds (e.g., L[4])?
b) What about slicing out of bounds (e.g., L[-1000:100])?
c) Finally, how does Python handle it if you try to extract a sequence in reverse—with the lower bound greater than the higher bound (e.g., L[3:1])? Hint: try assigning to this slice (L[3:1]=['?']) and see where the value is put. Do you think this may be the same phenomenon you saw when slicing out of bounds?
3.
Indexing, slicing, and del. Define another list L with four items again, and assign an empty list to one of its offsets (e.g., L[2]=[]): what happens?
Then try assigning an empty list to a slice (L[2:3]=[]): what happens now? Recall that slice assignment
deletes the slice and inserts the new value where it used to be. The
4.
Tuple assignment. What do you think is happening to X and Y when you type this sequence? We’ll return to this
construct in the next unit, but it has something to do with the tuples we’ve
seen here.
>>> X = 'spam'
# run this at a Python prompt
>>> Y = 'eggs'
>>> X, Y = Y, X
5.
Dictionary keys. Consider the following code fragments:
>>> D = {}
>>> D[1] = 'a'
>>> D[2] = 'b'
We learned that dictionaries aren’t accessed by offsets; what’s going on here? Does the following shed any light on the subject? (Hint: strings, integers, and tuples share which type category?)
>>> D[(1, 2, 3)] = 'c'
>>> D
{1: 'a', 2: 'b', (1, 2, 3): 'c'}
6. Dictionary indexing. Create a dictionary named D with three entries, for keys 'a', 'b', and 'c'. What happens if you try to index a nonexistent key (D['d'])? What does Python do if you try to assign to a nonexistent key d (e.g., D['d']='spam')? How does this compare to out-of-bounds assignments and references for lists? Does this sound like the rule for variable names?
7.
Generic operations. Run interactive tests to answer the following questions.
a) What happens when you try to use the + operator on different/mixed types (e. g., string + list, list + tuple)?
b) Does + work when one of the operands is a dictionary?
c) Does the append method work for both lists and strings? How about the using the keys method on lists? (Hint: What does append assume about its subject object?)
d) Finally, what type of object do you get back when you slice or concatenate two lists or two strings?
8.
String indexing.
Define a string S of four characters: S = "spam". Then type the following expression: S[0][0][0][0][0]. Any clues
as to what’s happening this time? (Hint: recall that a string is a collection
of characters, but Python characters are one-character strings.) Does this
indexing expression still work if you apply it to a list such as: ['s', 'p', 'a', 'm']? Why?
9.
Immutable types. Define a string S of 4 characters again: S =
"spam". Write an assignment that changes the string to "slam", using
only slicing and concatenation. Could you perform the same operation using just
indexing and concatenation? How about index assignment?
10.
Nesting.
Write a data-structure that represents your personal information: name (first,
middle, last), age, job, address, email ID, and phone number. You may build the
data structure with any combination of built-in object types you like: lists,
tuples, dictionaries, strings, numbers. Then access the individual components
of your data structures by indexing. Do some structures make more sense than
others for this object?
11.
Files. Write
a script that creates a new output file called myfile.txt and writes the string "Hello
file world!" in it. Then write
another script that opens myfile.txt, and reads and prints its contents. Run your two
scripts from the system command line. Does the new file show up in the
directory where you ran your scripts? What if you add a different directory
path to the filename passed to open?
Note: file write methods do not add newline characters to your strings;
add an explicit ‘\n’ at the end of the string if you want to fully terminate
the line in the file.
12.
The dir function. Try typing the following expressions at the interactive prompt. Starting
with Version 1.5, the dir builtin function has been generalized to list all
attributes of any Python object you’re likely to be interested in. If you’re
using an earlier version than 1.5, the __methods__ scheme has the same effect. If you’re using Python
2.2, dir is probably the only of these that will work.
[].__methods__ # 1.4 or 1.5
dir([]) # 1.5 and later
{}.__methods__
dir({})
Lab 3: Basic statements
1. Coding basic loops.
a) Write a for loop which prints the ASCII code of each character in a string named S. Use the built-in function ord(character) to convert each character to an ASCII integer (test it interactively to see how it works, or see the Python library manual).
b) Next, change your loop to compute the sum of the ASCII codes of all the characters in a string.
c) Finally, modify your code again to return a new list, which contains the ASCII codes of each character in the string. Does this expression have a similar effect—map(ord, S)? (Hint: map applies a function to all nodes of a sequence in turn, and collects all the results.)
2. Backslash characters. What happens on your machine when you type the following code interactively?
for i in range(50):
print 'hello %d\n\a' % i
Warning: Outside IDLE, this example may beep at you, so you may not want to run it in a crowded lab (unless you happen to enjoy getting lots of attention). Within IDLE, you’ll get odd characters instead. Hint: see the full set of backslash escape characters in the string literals section of Python’s language reference manual.
3. Sorting dictionaries. In lecture 2, we saw that dictionaries are unordered collections. Write a for loop which prints a dictionary's items in sorted (ascending) order. Hint: use the dictionary keys and list sort methods.
4. Program logic alternatives. Part of learning to program in Python is learning which coding alternatives work better than others. Consider the following code, which uses a while loop and found flag to search a list of powers-of-2, for the value of 2 raised to the power 5 (32). It's stored in a module file called power.py.
L = [1, 2, 4, 8, 16, 32, 64]
X = 5
found = i = 0
while not found and i < len(L):
if 2 ** X == L[i]:
found = 1
else:
i = i+1
if found:
print 'at index', i
else:
print X, 'not found'
C:\code> python power.py # run this in a system prompt
at index 5
As is, the example doesn’t follow normal Python coding techniques. Follow the steps below to improve it; for all of the transformations, you may type your code interactively, or store it in a script file run from the system command line (though using a file will make this exercise much easier).
a) First, rewrite this code with a while loop else, to eliminate the found flag and final if statement.
b) Next, rewrite the example to use a for loop with an else, to eliminate the explicit list indexing logic. Hint: to get the index of an item, use the list index method (L.index(X) returns the offset of the first X in list L).
c) Now, remove the loop completely by rewriting the examples with a simple in operator membership expression (to see how, interactively type this: 2 in [1,2,3]).
d) Finally, use a for loop and the list append method to generate the powers-of-2 list (L), instead of hard-coding a list constant.
e) Deeper thoughts: (1) Do you think it would improve performance to move the 2**X expression outside the loops? How would you code that? (2) As we saw in exercise 1, Python also includes a map(function, list) tool which could be used to generate the powers-of-2 list too, as follows: map((lambda x: 2**x), range(7)). Try typing this code interactively; we’ll meet lambda more formally in the next lecture.
Lab 4: Functions
1. Basics. At the Python interactive prompt, write a function which prints its single argument to the screen, and call it interactively, passing a variety of object types: string, integer, list, dictionary. Then try calling it without passing any argument: what happens? What happens when you pass two arguments?
2. Arguments. Write a function called adder in a Python module file. adder should accept two arguments, and return the sum (or concatenation) of its two arguments. Then add code at the bottom of the file to call the function with a variety of object types (two strings, two lists, two floating-points), and run this file as a script from the system command line. Do you have to print the call statement results to see results on the screen?
3. Varargs. Generalize the adder function you wrote in the last exercise to compute the sum of an arbitrary number of arguments, and change the calls to pass more or less than two. What type is the return value sum? (Hints: a slice like S[:0] returns an empty sequence of the same type as S, and the type built-in function can be used to test types, but the max function we wrote in class provides an easier approach). What happens if you pass in arguments of different types? What about passing in dictionaries?
4. Keywords. Change the adder function from exercise (2) to accept and add three arguments: "def adder(good, bad, ugly)". Now, provide default values for each argument, and experiment with calling the function interactively. Try passing 1, 2, 3, and 4 arguments. Then, try passing keyword arguments. Does the call "adder(ugly=1, good=2)" work? Why? Finally, generalize the new adder to accept and add an arbitrary number of keyword arguments, much like exercise (3), but you’ll need to iterate over a dictionary, not a tuple (hint: the dictionary.keys() method returns a list you can step through with a for or while).
5. Write a function called copyDict(dict), which copies its dictionary argument. It should return a new dictionary with all the items in its argument. Use the dictionary keys method to iterate. Copying sequences is easy (X[:] makes a top-level copy); does this work for dictionaries too?
6. Write a function called addDict(dict1, dict2) which computes the union of two dictionaries. It should return a new dictionary, with all the items in both its arguments (assumed to be dictionaries). If the same key appears in both arguments, feel free to pick a value from either. Test your function by writing it in a file and running the file as a script. What happens of you pass lists instead of dictionaries? How could you generalize your function to handle this case too? (Hint: see the type built-in function used earlier). Does the order of arguments passed matter?
7. Argument matching. First, define the following six functions (either interactively, or in an importable module file):
def f1(a, b): print a, b # normal args
def f2(a, *b): print a, b # positional varargs
def f3(a, **b): print a, b # keyword varargs
def f4(a, *b, **c): print a, b, c # mixed modes
def f5(a, b=2, c=3): print a, b, c # defaults
def f6(a, b=2, *c): print a, b, c # defaults + positional varargs
Now, test the following calls interactively, and try to explain each result; in some cases, you'll probably need to fall back on the matching algorithm shown in the lecture. Do you think mixing matching modes is a good idea in general? Can you think of cases where it would be useful anyhow?
>>> f1(1, 2)
>>> f1(b=2, a=1)
>>> f2(1, 2, 3)
>>> f3(1, x=2, y=3)
>>> f4(1, 2, 3, x=2, y=3)
>>> f5(1)
>>> f5(1, 4)
>>> f6(1)
>>> f6(1, 3, 4)
8. List comprehensions. Write code to build a new list containing the square roots of all the numbers in this list: [2, 4, 9, 16, 25]. Code this as a for loop first, then as a map call, and finally as a list comprehension. Use the sqrt function in the builting math module to do the calculation (i.e., import math, and say math.sqrt(x)). Of the three, which approach do you like best?
Lab 5: Modules
1. Basics, import. Write a program that counts lines and characters in a file (similar in spirit to “wc” on Unix). With your favorite text editor, code a Python module called mymod.py, which exports three top-level names:
a) A countLines(name) function that reads an input file and counts the number of lines in it (hint: file.readlines() does most of the work for you, and len does the rest)
b) A countChars(name) function that reads an input file and counts the number of characters in it (hint: file.read() returns a single string)
c) A test(name) function that calls both counting functions with a given input filename. Such a filename generally might be passed-in, hard-coded, input with raw_input, or pulled from a command-line via the sys.argv list; for now, assume it’s a passed-in function argument.
All three mymod functions should expect a filename string to be passed in. If you type more than two or three lines per function, you’re working much too hard—use the hints listed above!
Now, test your module interactively, using import and name qualification to fetch your exports. Does your PYTHONPATH need to include the directory where you created mymod.py? Try running your module on itself: e.g., test("mymod.py"). Note that test opens the file twice; if you’re feeling ambitious, you may be able to improve this by passing an open file object into the two count functions (hint: file.seek(0) is a file rewind).
2. from/from*. Test your mymod module from Exercise 1 interactively, by using from to load the exports directly, first by name, then using the from* variant to fetch everything.
3. __main__. Now, add a line in your mymod module that calls the test function automatically only when the module is run as a script, not when it is imported The line you add will probably test the value of __name__ for the string "__main__", as shown in this unit. Try running your module from the system command line; then, import the module and test its functions interactively. Does it still work in both modes?
4. Nested imports. Write a second module, myclient.py, which imports mymod and tests its functions; run myclient from the system command line. If myclient uses from to fetch from mymod, will mymod’s functions be accessible from the top level of myclient? What if it imports with import instead? Try coding both variations in myclient and test interactively, by importing myclient and inspecting its __dict__.
5. Package imports. Finally, import your file from a package. Create a subdirectory called mypkg nested in a directory on your module import search path, move the mymod.py module file you created in exercises 1 or 3 into the new directory, and try to import it with a package import of the form: import mypkg.mymod.
You’ll need to add an __init__.py file in the directory your module was moved to in order to make this go, but it should work on all major Python platforms (that’s part of the reason Python uses “.” as a path separator). The package directory you create can be simply a subdirectory of the one you’re working in; if it is, it will be found via the home directory component of the search path, and you won’t have to configure your path. Add some code to your __init__.py, and see if it runs on each import.
6. Reload. Experiment with module reloads: perform the tests in the changer.py example, changing the called function’s message and/or behavior repeatedly, without stopping the Python interpreter. Depending on your system, you might be able to edit changer in another window, or suspend the Python interpreter and edit in the same window (on Unix, a Ctrl-Z key combination usually suspends the current process, and a fg command later resumes it).
7. [Optional] Circular imports (and other acts of cruelty). In the section on recursive import gotchas, importing recur1 raised an error. But if we restart Python and import recur2 interactively, the error doesn’t occur: test and see this for yourself. Why do you think it works to import recur2, but not recur1? (Hint: Python stores new modules in the built-in sys.modules table (a dictionary) before running their code; later imports fetch the module from this table first, whether the module is “complete” yet or not.) Now try running recur1 as a top-level script file: % python recur1.py. Do you get the same error that occurs when recur1 is imported interactively? Why? (Hint: when modules are run as programs they aren’t imported, so this case has the same effect as importing recur2 interactively; recur2 is the first module imported.) What happens when you run recur2 as a script?
Lab 6: Classes
Note: The last 2 (or 3) are the most fun of this bunch; you might want
to start with these first, and then come back to work top down.
1.
Inheritance.
Write a class called Adder that exports a method add(self,
x, y) that prints a “Not Implemented”
message. Then define two subclasses of Adder that implement the add method:
a) ListAdder, with an add method that returns the concatenation of its two list arguments
b) DictAdder, with an add method that returns a new dictionary with the items in both its two dictionary arguments (any definition of addition will do)
Experiment
by making instances of all three of your classes interactively and calling
their add
methods.
Now,
extend your Adder superclass to save an object in the instance with a constructor (e.g.,
assign self.data a list or a dictionary) and overload the + operator with an __add__ to automatically
dispatch to your add methods (e.g., X+Y triggers X.add(X.data,Y)). Where is the best place to put the constructors and
operator overload methods (i.e., in which classes)? What sorts of objects can
you add to your class instances?
In practice, you might find it easier to code your add methods to accept just
one real argument (e.g., add(self,y)), and add that one argument to the instance’s current
data (e.g., self.data+y). Does this make more sense than passing two
arguments to add? Would you say this makes your classes more “object-oriented”?
2.
Operator overloading. Write a class called Mylist that shadows (“wraps”) a Python list: it should
overload most list operators and operations—+, indexing, iteration, slicing, and list methods such
as append and sort. See the Python
reference manual for a list of all possible methods to support. Also provide a
constructor for your class that takes an existing list (or a Mylist instance) and copies its components into an instance member. Experiment
with your class interactively. Things to explore:
a) Why is copying the initial value important here?
b) Can you use an empty slice (e.g., start[:]) to copy the initial value if it’s a Mylist instance?
c) Is there a general way to route list method calls to the wrapped list?
d) Can you add a Mylist and a regular list? How about a list and a Mylist instance?
e) What type of object should operations like + and slicing return; how about indexing?
f) If you are working with a more recent Python release (version 2.2 or later), you may implement this sort of wrapper class either by embedding a real list in a stand-alone class, or by extending the built-in list type with a subclass. Which is easier and why?
3.
Subclassing.
Now, make a subclass of Mylist from Exercise 2 called MylistSub, which
extends Mylist to print a message to stdout before each
overloaded operation is called and counts the number of calls. MylistSub should inherit basic method behavior from Mylist. For
instance, adding a sequence to a MylistSub should print a message, increment the counter for + calls, and perform the
superclass’s method. Also introduce a new method that displays the operation
counters to stdout and experiment with your class interactively. Do
your counters count calls per instance, or per class (for all instances of the
class)? How would you program both of these? (Hint: it depends on which object
the count members are assigned to: class members are shared by instances, self
members are per-instance data.)
4.
Metaclass methods. Write a class called
5.
Set objects.
Experiment with the set class described in this unit. Run commands to do the
following sorts of operations:
a) Create two sets of integers, and compute their intersection and union by using & and | operator expressions.
b) Create a set from a string, and experiment with indexing your set; which methods in the class are called?
c) Try iterating through the items in your string set using a for loop; which methods run this time?
d) Try computing the intersection and union of your string set and a simple Python string; does it work?
e) Now, extend your set by subclassing to handle arbitrarily many operands using a *args argument form (hint: see the function versions of these algorithms in the functions unit). Compute intersections and unions of multiple operands with your set subclass. How can you intersect three or more sets, given that & has only two sides?
f) How would you go about emulating other list operations in the set class? (Hints: __add__ can catch concatenation, and __getattr__ can pass most list method calls off to the wrapped list.)
6. Composition. Simulate a fast-food ordering scenario by defining four classes:
a) Lunch: a container and controller class
b) Customer: the actor that buys food
c) Employee: the actor that a customer orders from
d) Food: what the customer buys
To get you started, here are the classes and methods
you’ll be defining:
class Lunch:
def __init__(self) # make/embed Customer and Employee
def order(self, foodName) # start a Customer order simulation
def result(self) # ask the Customer what kind of Food it has
class Customer:
def __init__(self) # initialize my food to None
def placeOrder(self, foodName, employee) # place order with an Employee
def printFood(self) # print the name of my food
class Employee:
def takeOrder(self, foodName) # return a Food, with requested name
class Food:
def __init__(self, name) # store food name
The order simulation works as follows:
a) The Lunch class’s constructor should make and embed an instance of Customer and Employee, and export a method called order. When called, this order method should ask the Customer to place an order, by calling its placeOrder method. The Customer’s placeOrder method should in turn ask the Employee object for a new Food object, by calling the Employee’s takeOrder method.
b) Food objects should store a food name string (e.g., "burritos"), passed down from Lunch.order to Customer.placeOrder, to Employee.takeOrder, and finally to Food’s constructor. The top-level Lunch class should also export a method called result, which asks the customer to print the name of the food it received from the Employee via the order (this can be used to test your simulation).
c) Note that Lunch needs to either pass the Employee to the Customer, or pass itself to the Customer, in order to allow the Customer to call Employee methods.
Experiment
with your classes interactively by importing the Lunch class, calling its order method to run an
interaction, and then calling its result method to verify that the Customer got what he or
she ordered. If you prefer, you can also simply code test cases as self-test
code in the file where your classes are defined, using the module __name__ trick we met in
the modules unit. In this simulation, the Customer is the active agent; how would your classes change if
Employee were
the object that initiated customer/ employee interaction instead?
7.
Zoo Animal Hierarchy: (If this example was skipped in
class) Consider the class tree sketched in the figure below. Code a set of
6 class
statements to model this taxonomy with Python inheritance. Then, add a speak method to each of
your classes which prints a unique message, and a reply method in your top-level Animal superclass which simply calls self.speak to invoke the category-specific message printer in a
subclass below (remember, this will kick off an independent inheritance search
from self).
Finally, remove the speak method from your Hacker class, so that it picks up the default above it. When
you’re finished, your classes should work this way:
% python # start Python: "%" means your shell prompt
>>> from zoo
import Cat, Hacker
>>> spot = Cat()
>>> spot.reply() # Animal.reply, calls Cat.speak
meow
>>> data = Hacker() # Animal.reply, calls Primate.speak
>>> data.reply()
Hello world!
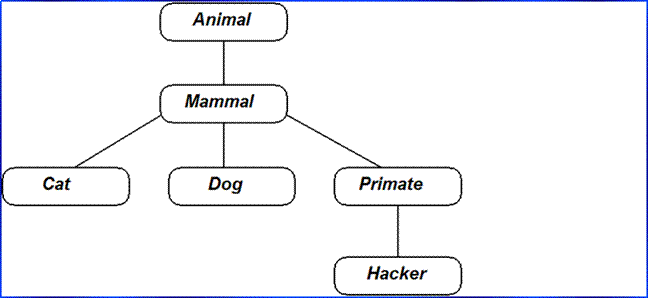
A Zoo Hierarchy
8.
The Dead Parrot Skit: (If this example was skipped in
class) Consider the object embedding structure captured in the figure below.
Code a set of Python classes to implement this structure with composition. Code
your Scene
object to define an action method, and embed instances of Customer, Clerk, and Parrot classes—all three of
which should define a line method which prints a unique message. The embedded
objects may either inherit from a common superclass that defines line and
simply provide message text, or define line themselves. In the end, your classes should operate
like this:
% python
>>> import parrot
>>> parrot.Scene().action() #
activate nested objects
customer: "that's one ex-bird!"
clerk: "no it isn't..."
parrot: None
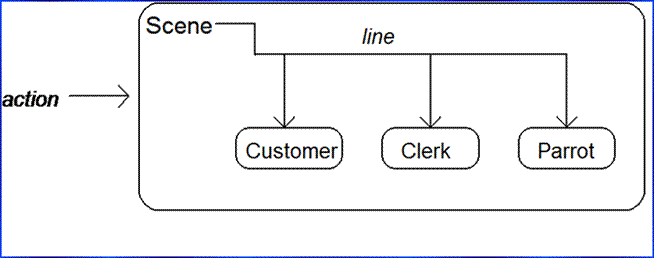
A Scene Composite
Lab 7: Exceptions and
built-in tools
1. try/except. Write a function called oops that explicitly raises an IndexError exception when called. Then write another function that calls oops inside a try/except statement to catch the error. What happens if you change oops to raise KeyError instead of IndexError? Where do the names KeyError and IndexError come from? (Hint: recall that all unqualified names come from one of four scopes, by the LEGB rule.)
2. Exception objects and lists. Change the oops function you just wrote to raise an exception you define yourself, called MyError, and pass an extra data item along with the exception. You may identify your exception with either a string or a class. Then, extend the try statement in the catcher function to catch this exception and its data in addition to IndexError, and print the extra data item. Finally, if you used a string for your exception, go back and change it be a class instance; what now comes back as the extra data to the handler?
3. Error handling. Write a function called safe(func,*args) that runs any function using the func(*args) call syntax (formerly known as the apply built-in function), catches any exception raised while the function runs, and prints the exception using the exc_info() call in the sys module. Then, use your safe function to run the oops function you wrote in Exercises 1 and/or 2. Put safe in a module file called tools.py, and pass it the oops function interactively. What sort of error messages do you get? Finally, expand safe to also print a Python stack trace when an error occurs by calling the built-in print_exc() function in the standard traceback module (use exc_info()[2], and see the Python library reference manual for details).
4. Error handling: the Pdb debugger. Run the “oops” function from (1) or (2) under the pdb debugger interactively. Import pdb and “oops”, run a call string, and type “c” (continue) commands till the error occurs. Where are you when the debugger stops? Type a ‘where’ command to find out. Now, type ‘quit’ and rerun the program: set a break point on the “oops” function, and single-step up to the error. Experiment with “up” and “down” commands—they climb and descend the Python call stack. See the library manual for more details on pdb debugging, or use the point-and-click debugger interface in the IDLE GUI.
5. Built-in tools. Study the tables of built-in tools in the Python library manual: functions, exceptions, modules, and special attribute names. Experiment interactively with some of the built-in functions we didn’t cover in the lectures yet (e.g., use “raw_input” to prompt for an input string, call “type” to inspect the type of objects, and so on). Python’s library reference manual provides the most up-to-date listing of available tools, but you may need to hunt for some of them the first time around.
6. The sys module. The “sys.path” list is initialized from the PYTHONPATH environment variable. Is it possible to change it from within Python? If so, does it effect where Python looks for module files? Run some interactive tests to find out.
Lab 8: System interfaces and
GUIs
1. Shell tools. (1) Test the pack/unpack example scripts: run pack to pack files, and unpack to unpack in another directory. (2) Now, modify pack and unpack to package their functionality as functions, instead of top-level code. For instance, add a ‘pack_files’ function in the pack script, which encloses the packing logic, and accepts two arguments: a list of input file-names and an output file-name. Wrap the unpack logic in a function that takes an input file name as its argument. (3) Finally, write code at the bottom of your new pack/unpack files which calls the new functions only when the file is run as a script. Test your new files by running them as scripts, and then by importing them and calling their functions interactively.
2. Shell tools. Set up a directory structure, and run the regression tester (example “regtest.py”) on some of the scripts you’ve developed so far.
3. Basic GUIs. Write a simple script that creates a GUI with three buttons—‘curly’, ‘moe’, and ‘larry’, each of which prints a different message on the ‘stdout’ stream. Use simple Tkinter class calls to build the GUI, but don’t code your GUI as a new class. Run this file as a script, from the system shell’s command line.
4. Frames. Now, rewrite your 3-button GUI from (3) as a subclass of the Frame container class, and test it again.
5. Extending GUIs. Extend the 3-button GUI class from (4) by subclassing it, to include a Label. Pack your Label before the superclass’s widgets; then try packing it after. What happens?
6. Attaching GUIs. Extend the 3-button GUI class from (4) to include a Label, by attaching it to an enclosing frame. You can code the enclosing Frame as another class, or by using simple widget creation calls. Try attaching the original class instance both before and after the label in the containing Frame; what happens this time?
7. File processing: readline. Write a script called “cat.py”, which defines a function called “lister”. The script should take 1 command-line argument—a text file name—and pass it as a function argument to “lister” only when the file is run as a script. The “lister” function should read a text file line-by-line with the “readline” method, and print each line in upper-case, with a line number prefix before each output line. Use the ‘string’ module to do the case conversion. Test your script file by running it on itself: “python cat.py cat.py”. Then import and test lister interactively: “cat.lister(‘cat.py’)”.
8. File processing: readlines, read. Change your “lister” function from (7) to use the “readlines” file method instead of “readline”, and retest. Then change “lister” to read the file all at once with “read”, and detect line boundaries manually. You may either scan for the end-of-line characters yourself by indexing or slicing, use the “string.index/find” functions to find each one, or call “string.split” (see the library manual for more details). Retest with this “read” version. Which of the approaches for finding end-of-lines is easiest? Which may be fastest?
9. Environment variables. Change your ‘USER’ environment variable, by assigning to “os.environ”, and spawn another Python program that prints the value of ‘USER’ (using fork, system, or popen). Is the modified value exported to the spawned process? Try changing a different environment variable and repeating the test.
10. File globbing. Write a script which accepts a directory name as a command-line argument, and prints a listing of all the files in that directory. Then enhance your script to also accept a search-pattern string on the command line, and use it to display matching file names in the directory.
11. Timing programs. Try changing the call order in “timeinline.py” to see if it has any effect: in you test code, call inline2 before inline1. Any effect? (Hint: might it depend on your ‘malloc’?) Then, change the example to allow the number of pushes and pops to be passed in to the “test” function instead of using global variables, and test the inline and inline2 functions interactively as follows:
>>> from testinline
import *
>>> test(1000, 1000, inline1)
[results]
>>> test(1000, 1000, inline2)
[results]
Any impact on the results? (Hint: the only way it could, is if you’re also measuring the time it takes to compile the scripts.). See also the CD’s Extras\Misc\timerseqs.py
Lab 9: Persistence
1. Shelve basics. (a) Write a function which creates a persistent shelve of lists, from a dictionary-of-lists passed in as an argument. (b) Then write a script file that accepts a shelve file name on the command line, and dumps the shelve to the screen, as “key => value” lines. (c) Now test both components: from the interactive command line, import and call the first function to load the shelve from a dictionary-of-lists you create, then change one of its entries interactively by opening the shelve yourself. Exit the interactive session, and run the script (b) to dump the updated shelve.
2. Shelve processing scripts. Write a script that updates (changes) all the entries in the shelve you created in exercise (1). Open and scan the shelve file, deleting the first node in each of the stored lists, and storing the lists back to the shelve as you go. Use your shelve dumping script from exercise (1) to verify your changes. Can you update a shelve by something like: ‘del file[key][0]’?
3. Storing class instances. Write a class called “Student” in a module called “student.py”. “Student” should model you: it’s constructor should create instance members for ‘name’, ‘age’, ‘job’, and so on, and define a method called ‘info’ which lists the member values in ‘key=>value’ form to stdout. Now, make an instance of this class interactively, and store it in a new shelve file. Exit Python, reopen your shelve, fetch back the object you stored, and inspect it by calling its ‘info’ method. Then, store a new “Student” instance object in the shelve, with fictitious member details. Did you have to import the “student” module in order to use “Student” instances fetched from the shelve? Why?
4. Changing classes. Change the “Student” class you wrote in (3), such that its ‘info’ method now lists members in ‘key…value’ form to stdout. Reopen your shelve, and iterate over all the stored Students (use the dictionary ‘keys’ method to get an index list), calling the ‘info’ method for each. What happens if you repeat this experiment after renaming the “student.py” module that contains the “Student” class?
Lab 10: Text processing and
the Internet
1. String processing. Write a function which returns the reverse of a string passed in as an argument. You may use iteration and concatenation, or any other approach you think works best. (Suggestion: what about using the built-in list(sequence) conversion function to leverage the list ‘reverse’ method for this job?) Can you generalize your function to reverse any type of sequence? What type should the result be?
2. String conversions. Write a function which converts a string of digit characters (‘0’ through ‘9’) to an integer object with the corresponding numeric value. For instance, “123” should create the integer 123. Hint: use “ord(C) - ord(‘0’)” to convert each digit. Experiment with these tools interactively. Now, how would you go about doing the inverse—converting an integer to a string? Hint ‘X % 10’ returns the remainder of division by 10, and ‘X / 10’ returns the integer part, but built-in tools can help here too.
3. String splits. Write a text file containing columns of numbers, and run the “summer.py” example to tally its columns. Now, write a file of numeric expressions without embedded blanks (e.g. ‘2+1’), and try running summer on that. What happens? Why? Finally, change ‘summer.py’ to split lines on “$” column separators, change your text file to separate columns by “$”, and rerun the tests. Can your expressions contain blanks and tabs now?
4. Regular expressions. Run the “cheader1.py” example on a C file (e.g., ‘.c’ or ‘.h’) of your choosing. For instance, you might run it over a Python include file in the Python source tree. Does it handle both ‘<>’ and quoted file names in #include directives? How about #define macros with arguments and continuation lines? As is, the script doesn’t support transitively included files (it doesn’t also scan files referenced by a #include line). How would you go about adding this too? (Hint: you’ll probably need to make a recursive call, and keep track of files you’ve scanned so far; see “Tools/scripts/h2py.py” in the Python source tree.)
5. The FTP module. Write a program that fetches the file “sousa.au” from site “ftp.python.org”, in directory “pub/python/misc”. Use anonymous FTP, and binary transfer mode, and store the file on your local machine under name “mysousa.au”. If you have an audio filter, you can play this file on your machine after your script finishes. How would you go about playing it automatically from within the FTP script? (Hint: a DOS “start” command can be run by os.system, and spawned web browsers may help too.)
Lab 11: Extending Python in
C/C++
Note: most of the exercises in the next two labs (extending and embedding Python in C) are complex, and require access to a C compiler and build environment. They’re also almost never worked on during the course itself. Feel free to use these last two lab sessions to go back and finish prior lab exercises you’ve skipped, especially if you’ll be using Python in stand-alone mode (i.e., without coding any C integrations of your own). These exercises can also be tackled after the course is over, at your convenience. Be sure to at least have a look at the last two exercises in these two labs, though; they don’t require C compilation.
1. Extension modules. Add another function to the extension module example, which calls the C library’s ‘putenv’ function. It should accept a single string, and return the ‘None’ object, or a NULL pointer to report errors. Install the modified module in Python using static binding, and test your new extension function from the Python command line. How does your putenv differ from the built-in ‘os.environ’ and ‘os.putenv’? (Hint: does your function update ‘os’?).
2. Dynamic binding. If your platform supports dynamic load libraries, bind the modified ‘environ’ module from (1) to Python using dynamic binding: remove the Modules/Setup entry and remake Python, compile ‘environ.c’ into a shared library, and put the result in a directory names on $PYTHONPATH. Test the binding by importing the module and calling your ‘putenv’ function interactively.
3. Extension types. Code a ‘print’ handler function in the C stack extension type (stacktyp.c), which simply prints a “not implemented” message whenever it is called. Compile your extension type’s module and bind it to Python, either statically or dynamically, and test the handler interactively.
4. Extension types. Code the ‘length’ handler function, and the ‘push’ and ‘pop’ instance methods, and rebuild Python with these extensions. Test the new method interactively: import the stack module, make a Stack instance, and call the instance’s push, pop, length, and item (indexing) functionality. Does the type respond to ‘for’ loop iteration as is?
5. Extension types. Add a ‘set_item’ (index assignment) handler to the stack type. Code a handler function (it may simply print a message), register your function in the type descriptors, and rebuild. Test your new handler interactively, by assignments (“x[i] = value”).
6. Extension wrappers. Expand the extension type wrapper presented in the lecture to include a wrapper for the new ‘set_item’ method you implemented in exercise (5).
7. Inspecting objects. Import your extension module from exercise (1), and call the built-in ‘dir’ function on the module (‘dir(M)’). What do you see? Now, inspect the module’s ‘__dict__’ attribute. How does this differ? Next, import your stack type, make an instance, and inspect the instance’s ‘__members__’ and ‘__methods__’ attributes. What happens when you do a ‘dir’ on a type instance? How do these findings compare to Python modules, classes and class instances? Write a simple class in a module file and run interactive tests to find out.
8. Inspecting objects. Repeat all of the inspections performed in exercise (7) on the built-in ‘regex’ regular expression module: import and inspect the ‘regex’ module itself, then make a compiled expression object (by running an assignment like “x = regex.compile(‘hello’)”) and inspect its members and methods. Regex is a pre-coded C extension module/type which is a standard part of Python; compiling expressions makes a type instance object. The module’s source code is available in the Python source tree’s ‘Module’ directory. Find and study the ‘regexmodule.c’ source file.
9.
Built-in type
examples. Study the implementations
of built-in lists, integers, and dictionaries, in the “Object” directory of the
Python source tree. See the source files
‘listobject.c’, ‘intobject.c’,
and ‘mappingobject.c’. Can you locate the major type components we
studied in the lecture? Why isn’t there
a constructor module? (Hint: how do you
create lists, integers, and dictionaries?).
Lab 12: Embedding Python in
C/C++
1. Running code strings. Write a C ‘main’ program which runs a Python code string, to display the value of the “sys.path” module search path in Python. You may implement the embedding in one of three ways:
● By running simple strings like “import sys; print sys.path” (PyRun_SimpleString)
● By running “print path” in module “sys” (PyImport_ImportModule, PyRun_String)
● By using the extended API functions (Run_Codestr)
Build an executable by linking your program with Python libraries and object files, and run it from the system shell’s command line. If you choose to use the extended API tools, also compile with the “ppembed*.c” files from the CD-ROM shipped with the book Programming Python 2nd Edition. Experiment with the other modes above as time allows.
2. Calling objects. Write a C ‘main’ program which calls the “os.getcwd()” function, and prints the returned string to stdout. “os.getcwd()” takes no arguments, and returns the name of the current directory as a Python string (see p.788). Alternative approaches:
● Call getcwd manually (PyImport_ImportModule, PyEval_CallObject)
● Call getcwd with an extended API function (Run_Function)
Build your program and test it from the system command line.
3. Dynamic debugging. If you used the extended API functions in exercises (1) and/or (2), experiment with dynamic debugging of embedded code, by setting the variable “PY_DEBUG = 1” in your C program, before calling the API functions. Where are you in your embedded code, when control stops in the pdb debugger? Would dynamic reloading of the embedded code help in these programs?
4. Registration. In the registration example, suppose we wanted to change the event handlers without stopping the C program. Is there any way to force C to reload the registered function’s module at run-time? (Hint: how does C know the name of the enclosing module? And how would reloading the module update the object?) Does this sound similar to the “from” gotcha for “reload” in Python?
5. Error handling. Add code to the “objects1err.c” example to print a Python stack traceback (PyErr_Print) and fetch exception information using the “pyerrors.c” support file whenever API errors occur. Now, change your PYTHONPATH so it doesn’t include the Python module which holds the “klass” class, and rebuild/rerun your executable to trigger an API error. What happens?
Lab
13: Decorators and Metaclasses
1.
Function
decorators. Write a function decorator
that, for any decorated function or method, computes and prints the elapsed
time for each call, and keeps a total of the elapsed time consumed by all
calls. Test your decorator on both a
simple function and a class method function.
Note that to support class methods, you will probably need to use
wrapper coded as a nested “def” instead a class with
a “__call__”, because the latter will be passed the wrapper class instance in
“self”, not the instance of the subject class (there would be no way to
dispatch the call to the instance and its method). Also see Unit 9, “Built-in Tools Overview,”
as well as the sequence timer example we wrote there, for pointers in using the
“time” module to compute elapsed time.
With nested “def” codings,
you might use nonlocals or user-assigned function attributes to store state
information (total elapsed time).
2.
Metaclasses and class
decorators.
Write a metaclass or class constructor
(or both, if you have time), which applies the timing function decorator you
wrote in the prior exercise to every method in a subject class when the class
is created. Use the “types” module’s “types.FunctionType”
to test values of all attributes in the class’s attribute dictionary (a.k.a. __dict__) to detect methods to which you will apply the
decorators. To apply the decorator,
simply run the name rebinding logic manually.
Test you decorated class by making instances and calling methods.