
|
|
Python
|
|---|
Latest substantial revision: July 2025
This page documents and critiques changes made to Python from 2014 to 2024 and between the 5th and 6th Editions of the book Learning Python. Because that book's 5th Edition was updated for Pythons 3.3 and 2.7 and the 2.X line is effectively frozen, this page covers Pythons 3.4 through 3.12, the latter of which is integrated into the 6th Edition. Earlier changes are documented in the book's 5th Edition, but for brief summaries, see its Appendix C or this site's pages for Python 3.3, 3.2, and 2.7. A separate page for Python 3.13+ changes may appear in time.
There's a wealth of content here for Python readers, but if your time is tight and you're looking for suggested highlights, be sure to catch the intro, the coverage of new formatting tools in 3.6 and 3.5, recent news here and here, and the essays on 3.5+ type hints and coroutines. For the full story, browse this page's contents:
Changes in Python 3.10+ (Jan-2022+)
Changes in Python 3.9 (Oct-2020)
Changes in Python 3.8 (Oct-2019)
Changes in Python 3.7 (Jun-2018)
Changes in Python 3.6 (Dec-2016)
Changes in Python 3.5 (Sep-2015)
The 5th Edition of Learning Python published in mid-2013 has been updated to be current with Pythons 3.3 and 2.7. Especially given its language-foundations tutorial role, this book should address the needs of all Python 3.X and 2.X newcomers for many years to come.
Nevertheless, the inevitable parade of changes that seems inherent in open source projects continues unabated in each new Python release. Many such changes are trivial—and often optional—extensions which will likely see limited use and may be safely ignored by newcomers until they become familiar with fundamentals that span all Pythons.
But not all changes are so benign; in fact, parades can be downright annoying when they disrupt your day. Those downstream from developer cabals have legitimate concerns. To some, many recent Python extensions seem features in search of use cases—new features considered clever by their advocates but which have little clear relevance to real-world Python programs and complicate the language unnecessarily. To others, recent Python changes are just plain rude—mutations that break working code with no more justification than personal preference or ego.
This is a substantial downside of Python's dynamic, community-driven development model, which is most glaring to those on the leading edge of new releases, and which the book addresses head-on, especially in its introduction and conclusion (Chapters 1 and 41). As told in the book, apart from the lucky few who are able to stick with a single version for all time, Python extensions and changes have a massive impact on the language's users and ecosystem. Language mods must be:
While the language is still usable for a multitude of tasks, Python's rapid evolution adds additional management work to programmers' already-full plates and often without clear cause.
Perhaps worst of all, newcomers face the full force of accumulated flux and growth in the latest and greatest release at the time of their induction. Today, the syllabus for new learners includes two disparate lines, with incompatibilities even among the releases of a single line; multiple programming paradigms, with tools advanced enough to challenge experts; and a torrent of feature redundancy, with 4 or 5 ways to achieve some goals—all fruits of Python's shifting story thus far.
In short, Python's constant change has created a software Tower of Babel, in which the very meaning of the language varies per release. This leaves its users with an ongoing task: even after you've mastered the language, new Python mutations become required reading for you if they show up in code you encounter or use and can become a factor whenever you upgrade to Python versions in which they appear.
Consequently, this page briefly chronicles changes that appeared in Python after the 5th Edition's June 2013 release, as a sort of virtual appendix to the book. Hopefully, this and other resources named here will help readers follow the route of Python change—wherever the parade may march next.
An editorial note up front: because changing a tool used by many comes with accountability, this page also critiques while documenting. Though subjective, its assessments are both fair and grounded in technical merit, and they reflect the perspective of someone who has watched Python evolve and been one of its foremost proponents since 1992 and still wishes only the best for its future. Despite what you may have heard, informed criticism is both okay and crucial when its goal is improvement.
Programming language design is innately controversial, and you should weigh for yourself the potential benefits of each change noted here against its impacts on knowledge requirements and usability. At the end of the day, though, we can probably all agree that critical thinking on this front is in Python's best interest. The line between thrashing and evolution may be subjective, but drawing it carefully is as vital to the language's future as any shiny new feature can be.
Wherever you may stand on a given item below, this much seems certain: a bloated system that is in a perpetual state of change may eventually be of more interest to its changers than its prospective users. If this page encourages its readers to think more deeply about such things while learning more about Python, it will have discharged its role in full.
The latest from the kitchen-sink design school: Python 3.10 is out, with the usual set of opinion-based changes and deprecations—including the usual set of painfully academic tweaks to 3.X's constantly morphing type hints and coroutines. Most 3.10 changes aren't worth covering here, but one merits a callout.
Python 3.10 has sprouted a multiple-choice match/case
statement—a sort of "switch" on steroids—after getting by quite well
without one for three decades.
As usual, the new statement convolutes the language and adds to its learning
requirements for no better reason than the mood of a handful of developers.
And as usual, this addition was justified by the non-sequitur argument
that other languages do it too; per the PEP:
Motivation (Structural) pattern matching syntax is found in many languages, from Haskell, Erlang and Scala to Elixir and Ruby. (A proposal for JavaScript is also under consideration.) [...]
More fundamentally, this is yet another redundant extension sans user need. Structural pattern matching is a wildly ad-hoc answer to a question nobody seems to have asked, and there have always been simple ways to code multiple-choice logic in Python—all of which will certainly continue to see more widespread use than the new and curiously complex alternative. Python, after all, managed to rise to the top of the programming-languages heap and become the go-to tool for everything under the sun, without the new statement. This is surely not the hallmark of a utility deficit.
All of which has been said here before (see the 3.9 review
for an expanded cut). In the interest of brevity,
this page isn't going to legitimize the latest superfluous add-on
by covering it further; read about it
here and
here
if you wish.
But please remember: using match/case means your program
can be run only on Python 3.10 or later. Being divisive and exclusionary may be
a norm in Python 3.X's culture, but it doesn't have to be one in your own code.
The real problem with Python, of course, is that its evolution is largely driven by narcissism, not user feedback. That inevitably makes your programs beholden to ever-shifting whims and ever-hungry egos. Such dependencies might have been laughable in the past. In the age of Facebook, unfortunately, this paradigm permeates Python, open source, and the computer field. In fact, it extends well beyond all three; narcissism is a sign of our times.
That said, fixing bugs in human nature also goes well beyond this page's mission, so we'll have to leave this thread here. As always, dear reader, the future of Python, like that of the human story at large, must rest in part with you.
Etcetera:
this page stopped receiving updates at this point, but the parade marched on.
Pythons 3.11 and 3.12 added exception groups (a tangled extension
with narrow roles), as well as a type statement that obviates simple
assignments (and yes, there are now optional, convoluted, and wholly unused type
declarations in a dynamically typed language!).
These Pythons also come with opinionated deprecations and removals of a host of longstanding tools. Among these are:
cgi module—whose cut is a colossal
douche move that breaks reams of existing
code but can thankfully be worked
around with a third-party patch via
pip3 install legacy-cgi
\other that were valid and widely used
for some three decades—whose drop has dire and far-reaching impacts on docstrings
for no other reason than a few core devs' opinions
\377—whose trim purportedly owes to
their being too big for bytes... even though these name code points in text strings,
not bytes (RTFM anyone?)
Later Pythons continued the ascent of Mt. Convolution, including 3.14's arguably
comical t'...' string-formatting twist that's officially out of scope here
(but see the blurb ahead).
In the end, Python remains a constantly morphing sandbox of ideas, which is great if you just want to play in the sandbox but lousy if you're trying to engineer reliable and durable software. Vetter and downstream user beware.
Per its What's New,
Python 3.9 is a minor release with a relatively small set of changes, which is
about what you'd expect from a project that now issues a new release
each year.
It does, however, manage to both inject the usual batch of superfluous
language convolutions and extend the paradigm of
thrashing-based—if not troll-driven—engineering.
Among the morph:
Perhaps most elaboration worthy among 3.9's changes is the addition of union-like
Takeaway: Python 3.X now thrashes so much that it eventually contradicts itself.
In this case, there was pushback on
multiple grounds,
all of which were well reasoned and need no elaboration here—and as usual, were
outshouted by the agenda of a few convoluters.
The rejection of calls to avoid
redundancy
with appeals to tenets of the Python
Zen,
however, warrants an underscore. Quoting from the change's PEP:
And somewhere, angels surely must weep (and Perl folk surely must
smirk).
Feature bloat kills usability, and past mistakes do not justify new ones.
More to the point: needlessly changing a tool used by millions may be rude,
but knowingly rejecting past wisdom is juvenile.
This page hopes to continue sparking discourse on the perils of
thrashing in engineering projects. But this will likely be its final entry.
There will, of course, be a Python 3.10, and a 3.11, and a 3.12.
And they will, of course, add redundant functionality, break existing
code, and impose the constantly morphing whims of the few on the many.
Popularity implies neither quality nor courtesy, and candidly, there
are better things to do in the last quadrant of life
than document this stuff.
In the end, the convolution of Python was not a technical story. It was
a sociological story and a human story. If you create a work with qualities
positive enough to make it popular but also encourage it to be changed for
a reward paid entirely in the dark currency of ego points, time will inevitably
erode the very qualities which made the work popular originally. There's no
known name for this law, but it happens nonetheless and not just in
Python. In fact, it's the very definition of open source, whose
paradigm of reckless change now permeates the computing world.
Some of this law's consequences are less abstract than others.
While Python developers were busy playing in their sandbox,
web browsers mandated JavaScript, Android mandated Java,
and iOS became so proprietary and closed that it holds almost
no interest to generalist developers. Indeed, many of the
open-source movement's original ideals of developer freedom
are now perilously close to being dismissed as sacrifice on
the altar of ego-based churn.
The sage should know when to stop. Python never did. This page does.
Never say never: almost immediately after the preceding
was posted, this site received feedback from readers hoping that this page's
updates will continue. It's possible that this page may be back for 3.10 and beyond,
though this depends upon both whether there's anything useful to add and how well
the sedatives work...
| and |= operators
purportedly meant to add set union to
dictionaries...
though the second is just an in-place version of the first; this is
just one of many set operations and isn't the same as union at all; and the
mod just adds redundant and obscure functionality that is imagined to
be better than other redundant and obscure functionality added to 3.X
in the past.
Wisdom Deprecated
| operators for dictionaries.
In truth, this is really just a trivial key-based merge, with an operator syntax
borrowed from sets.
It's also about as irregular and redundant as it gets; it:
dict.update() and the already-redundant
and cryptic {**dict1, **dict2} unpacking star syntax added earlier
on 3.X's meandering path
(and critiqued formerly on this page)
More Than One Way To Do It
Okay, the Zen doesn't say that there should be Only One Way To Do It.
But it does have a prohibition against allowing "more than one way to do it".
Response
There is no such prohibition. The "Zen of Python" merely expresses a preference
for "only one obvious way":
There should be one-- and preferably only one --obvious way to do it. [...]
In practice, this preference for "only one way" is frequently violated in Python. [...]
We should not be too strict about rejecting useful functionality because it
violates "only one way".
Closing Words?
![]()
Python 3.8 is now in beta. It's scheduled for release in October 2019, and it's documented in full by its What's New. As is now the norm, it also comes with the latest batch of language changes born of opinion-based thrashing. In fact, this page is starting to sound like a broken record (and the changes are starting to sound like flamebait), but a brief review of this version is in order for readers of the book. Among 3.8's lowlights:
(x := y), that millions of Python programmers
somehow managed to make do without for nearly three decades.
Typing x = y separately was never hard,
but code with obscurely nested :=
assignments will almost certainly be brutal.
def f(x, y=None, /),
whose odd / both qualifies as
kludge
and forces preceding function arguments to be passed by position only—a
wildly special-case role so important that it went unnoticed
since the early 1990s (yes, sarcasm intended).
f'{x*y + 15=}',
whose weird = invokes an implicit and unexpected
evaluation and format and adds yet another special case
to 3.6's f-strings extension described ahead...
which was itself fully redundant 3.X morph that mushroomed Python's
string-formatting story badly and needlessly. F-strings are now
officially ad-hoc stacked!
PYTHONPYCACHEPREFIX,
which allows the location of the 3.X __pycache__ bytecode
folder to vary per program, thereby breaking any tools that assume
its formerly fixed location and further convoluting the ever-changing
3.X module tale.
time.clock function,
a tool which has been widely used by Python programmers from
day one and whose deletion will break reams of Python code
(including some benchmarking examples in the
book
and other programs published
online).
In short, 3.8 is mostly more of the accumulation-instead-of-design model of language evolution championed by the 3.X line. As usual, some will rush to use the new items in a strange effort to prove that they are somehow smarter than others—thereby sentencing their code to work on 3.8 and later only. As noted repeatedly on this page, you don't have to be one of them; these are optional extensions that most users are better off avoiding.
The pigheaded removal of the widely used time.clock,
however, just seems sad. Rather than improving a go-to tool that
was supported for some 30 years, it's
been deleted altogether in favor of something different.
As foreshadowed in the book, this means that very many users
of Python 3.8 and later will have to change their code to use alternative
tools in the time module that very few opinionated
others have now mandated.
Friendly not, that, but typical of the Python 3.X culture.
It's easy to see this culture at work for yourself. Well-reasoned objections
to the subjective removal of time.clock were indeed registered
here,
here, and
elsewhere;
but they were outshouted by the aesthetic preferences of a stubborn and myopic
few, whose ego investment in the incompatible change clearly outweighed the
consequences for other peoples' code. This is how open source does not work.
In this specific case, the book was able to
give work-arounds for future time.clock deprecation (see
New Timer Calls in 3.3 on page 655; in short, you must use
time.perf_counter wherever time.clock is absent).
In general, though, Python 3.X's rate of
change far outpaces its learning resources (see the similar fate of
imp.reload in 3.7 ahead), and neither documentation
nor deprecation protocols qualify as justification; warning people that you're going
to be rude doesn't make it okay to be rude.
This writer wishes to reiterate that he still uses and enjoys Python regularly. It remains a great tool for programming in most or all application domains—even some that mutate just as carelessly as Python (per the link, thrashing is both endemic and chronic in today's software world).
But this writer also doesn't use the pointless products of flux that are now cranked out annually and doesn't recommend that book readers use these extensions either. Ego-driven churn may be an inherent downside of open-source projects, but it can also be largely ignored. You can't do much about changes that break existing programs, of course (apart from releasing work-arounds or freezing support levels); optional language extensions, however, are optional.
As always, the best advice is to avoid the extraneous new stuff, and stick to the very large subset of Python that has proved to be so valuable across decades and domains. Your code will be much more widely usable, and your coworkers will be much less inclined to grab the pitchforks.
Postscript: during 3.8's tenure, python.org also ended its support for the still-widely-used Python 2.X—and inserted a rude denigration banner at the top of every page in 2.X users' docs. You can read expanded coverage of this unfriendly move here; alas, 2.X users seem no longer invited to the club.
As of February 2018, Python 3.7 is in beta and scheduled for release
in June 2018. Per its
What's New document,
this looks to be a relatively minor update in terms of language change
(e.g., __getattr__ now works in
modules
too, but it probably shouldn't, and you'll probably never care).
As usual, though, this latest Python continues to rehash its "features,"
and breaks existing programs in the name of subjective "improvements."
This section briefly summarizes both categories and calls out one of
their most crass members.
1. General Rehashings and Breakages
In the rehashings department, Python 3.7 is yet again changing its handling of Unicode locales and bytecode files—perennial sources of revisions in recent versions. It's also once more modifying or deprecating portions of its implementations of both type hints and coroutines—convoluted 3.X extensions that have been in a perpetual state of flux since they were introduced a few versions ago (see this and this for background).
Dictionaries also suddenly maintain their keys in insertion order—which is not
quite sequence-y and invalidates scads of docs which documented the former random order.
And modules have suddenly sprouted __getattr__ and __dir__
functions called for attribute unknowns and listings—which conflate classes
with modules and seem to assume that you have to already know Python to use Python.
In the breakages column, 3.7's changes are numerous and widespread and require
case-by-case analysis. As examples, its standard library changes to the
subprocess
module's stream defaults and the
shuil.rmtree()
function's error-handler arguments seem likely to impact programs like those this page's author
has written in recent years. For such programs, revalidation and
redistribution costs make a 3.7 upgrade impossible.
As a specific example of a breakage that's directly relevant to the
book, Python 3.7 also now
issues a deprecation warning when code imports the imp.reload
module-reloading tool; you'll soon need to change the first of the following to the
second everywhere:
$ python3 Python 3.7.4 (default, Jul 28 2019, 22:33:35) >>> from imp import reload __main__:1: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses >>> from importlib import reload >>>Sadly, this widely used built-in has now been senselessly moved twice in Python 3.X—from built-in function, to the
imp module, and now to the
importlib module—breaking all code that relies on formerly documented
locations on each hop. This is careless in the extreme and motivated by nothing more
than the personal preferences of those with time to impose their opinions on
others' programs.
From the broader view, Python 3.7 is really just the latest installment of the constant churn that is the norm in the 3.X line. Because this is pointless (and just no fun) to document, this page's 3.7 coverage will stop short here. Readers are encouraged to browse Python's What's New documents for more details on 3.7 and later.
Better still, avoid the bleeding-edge's pitfalls altogether by writing code that does not depend on new releases and their ever-evolving feature sets. In truth, the latest Python version is never required to implement useful programs. After all, every Python program written over the last quarter century has managed to work well without Python 3.7's changes. Yours can too.
In the end, new does not necessarily mean better—despite the software field's obsession with change. Someday, perhaps, more programmers will recognize that volatility born of personal agenda is not a valid path forward in engineering domains. Until then, the path that your programs take is still yours to choose.
2. StopIteration Busted in Generator Functions
After the preceding summary was written, a reader's errata post in autumn 2019 revealed an insidious Python 3.7 change that merits retroactive and special coverage here. In short, 3.7 also included a change that needlessly and intentionally broke the behavior of exceptions in generator functions and requires modifications to existing 3.X code. That behavior and its dubious alteration in 3.7 are both subtle, but one partial example in the book fell victim to the thrashing.
Details: In Pythons 3.0 through 3.6, a StopIteration
raised anywhere in a generator function suffices to end the generator's
value production because that's just what an explicit or implicit
return statement does in a generator. For example,
in the following code from a sidebar on page 645 of the book,
the next(i) inside the loop's list
comprehension will trigger StopIteration when any
iterator is exhausted, thereby implicitly terminating the generator
function altogether—as intended—through Python 3.6:
>>> def myzip(*args): ... iters = list(map(iter, args)) # make iters reiterable ... while iters: # guarantee >=1, and force looping ... res = [next(i) for i in iters] # any empty? StopIteration == return ... yield tuple(res) # else return result and suspend state ... # exit: implied return => StopIteration >>> list(myzip((1, 2, 3), (4, 5, 6))) [(1, 4), (2, 5), (3, 6)] >>> [x for x in myzip((1, 2, 3), (4, 5, 6))] [(1, 4), (2, 5), (3, 6)]
If such code has to run on 3.7 and later, however, you'll need to
change it to catch the StopIteration manually inside the
generator, and transform it into an explicit return
statement—which just implicitly raises
StopIteration again:
>>> def myzip(*args): ... iters = list(map(iter, args)) ... while iters: ... try: ... res = [next(i) for i in iters] ... except StopIteration: # StopIteration won't propagate in 3.7+ ... return # how generators should exit in 3.7+ ... yield tuple(res) # but exit still == return => StopIteration ... >>> list(myzip((1, 2, 3), (4, 5, 6))) [(1, 4), (2, 5), (3, 6)] >>> [x for x in myzip((1, 2, 3), (4, 5, 6))] [(1, 4), (2, 5), (3, 6)]
If you don't change such code, the StopIteration
raised inside the generator function is covertly changed to a
RuntimeError as of 3.7, which won't terminate the
generator nicely, but will pass as an uncaught exception causing
code failures in most use cases. Here's the impact on the book
example's original code when run in 3.7:
>>> list(myzip((1,2,3), (4,5,6))) Traceback (most recent call last): ... StopIteration The above exception was the direct cause of the following exception: Traceback (most recent call last): ... RuntimeError: generator raised StopIteration
Importantly, this change applies to both implicit and explicit
uses of StopIteration: any generator function that
internally triggers this exception in any way will now likely
fail with a RuntimeError.
This is a major change to the semantics of generator
functions. In essence, such functions in 3.7 and later
can no longer finish with a StopIteration but must
instead return or complete the function's code.
The following variant, for instance, fails the same way in 3.7:
>>> def myzip(*args): ... iters = list(map(iter, args)) ... while iters: ... try: ... res = [next(i) for i in iters] ... except StopIteration: ... raise StopIteration # this also fails: return required ... yield tuple(res) # even though return raises StopIteration!
And bizarrely, changing the first of the following lines in the code
to the second now causes a different exception to be raised in 3.7:
despite the semantic equivalence, you'll get a StopIteration
for the first but a RuntimeError for the second,
and may have to catch both in some contexts to accommodate the
new special case:
... res = [next(i) for i in iters] # StopIteration ... res = list(next(i) for i in iters) # RuntimeError (!)
In other words, 3.7 swaps one subtle and implicit behavior for another subtle and implicit behavior—which also manages to be inconsistent. It's tough to imagine a better example of pointless churn in action.
Worse, the replacement knowingly breaks much existing and formerly valid 3.X code and as usual reflects the whims of a small handful of people with time to chat about such things online. In this case, developers lamented the need to maintain backward compatibility—and then went ahead and broke it anyhow. As part of their reckless bargain, even code in Python's own standard library which relied on the former 3.6-and-earlier behavior had to be changed to run on 3.7.
Lesson: You can read more about this change at its PEP, find examples of programs it broke with a web search, and draw your own conclusions along the way. Regardless of your take, though, users of Python 3.X should clearly expect that deep-rooted language semantics may change out from under them arbitrarily; with minimal warning and even less user feedback; and according to the opinions of a few people who have no vested interest in your code's success.
Simply put, in the absence of version freezes, your Python programs will probably break eventually through no fault of your own. Buyer, be warned.
At this writing in October 2015, Python 3.5 is less than one month old, yet a PEP for Python 3.6 is already in production with both a schedule and an initial changes list. So far, just one significant change is accepted—a proposal to add a fourth and painfully redundant string formatting scheme—but others will surely follow. It's impossible to predict what the final release will entail, of course, so please watch the PEP or this spot for more details as the 3.6 story unfolds.
Update As of May 2016, Python 3.6 is now in alpha release, with a mid-December 2016 target for its final version, still-emerging documentation here, and the fairly complete changes story in the 3.6 What's New. The list of changes below is being updated as 3.6 solidifies and time allows.
Update As of the October 2017 refresh of this page, Python 3.6 has been released (of course), and Python 3.7 is already on the horizon (of course). Watch this page, the 3.7 release schedule, and 3.7's What's New document for more inevitable changes, coming to a backwards-incompatible install near you in June 2018.
1. Yet Another String Formatting Scheme: f'...'
This section was expanded in December 2019.
Python 3.6 plans to add a fourth string formatting scheme, using new f'...' string literal syntax.
Provisionally known as f-strings, this extension will perform string interpolation—replacing variables
named by expressions nested in the new literal with their runtime values. Technically, the nested expressions
may be arbitrarily (and perhaps overly) complex; are enclosed in {} braces with an optional format specifier
following a : separator; and are evaluated where the literal occurs in code. For instance, here are a
few basic f-strings in action:
>>> spam = 'SPAM'
>>> items = [1, 2, 3, 4]
>>> intvalue = 1023
>>> f'we get {spam} alot.' # uses variable 'spam' in this scope
'we get SPAM alot.'
>>> f'size of items: {len(items)}' # ditto, but 'items' and an expression
'size of items: 4'
>>> f'result = {intvalue:#06x} in hex' # formatting syntax is allowed here too
'result = 0x03ff in hex'
Interesting, perhaps (especially to readers who've used something similar in other languages), but this is wholly redundant with Python's existing string tools. The following, for example, are the equivalents using the string-formatting expression that's been around since the earliest of Python's days:
>>> 'we get %s alot.' % spam # traditional formatting equivalents 'we get SPAM alot.' >>> 'size of items: %d' % len(items) 'size of items: 4' >>> 'result = 0x%04x in hex' % intvalue # '%s' % hex(intvalue) works too 'result = 0x03ff in hex'
Redundancy aside, the following example demonstrates just how complex the expressions nested in an f-string can be. This works (and will probably excite those bent on writing unreadable code that nobody else can possibly understand), but it comes with both great potential to obfuscate code, as well as special-case syntax constraints—including unique rules about nested quotes for this tool alone:
>>> f'a manual dict: {{k: v for (k, v) in (("a", spam), ("b", intvalue))}}' # hmm...
"a manual dict: {'a': 'SPAM', 'b': 1023}"
>>> f'a manual dict: {{k: v for (k, v) in (('a', spam), ('b', intvalue))}}'
SyntaxError: invalid syntax
>>> f'a manual dict: {{k: v for (k, v) in (("a", spam), (\'b\', intvalue))}}' # flat is better
SyntaxError: f-string expression part cannot include a backslash
In such cases, pulling complex expressions out of the format string altogether would both avoid quote issues and make code much more readable and maintainable. Because f-strings are based on nesting, though, they will also encourage nesting by design; Python's existing formatting tools do not. In fact, f-strings on this dimension seem a careless disregard of Python's core design principles: see Flat is better than nested in the Zen.
You can read more about this new scheme at its PEP. In sum, f-strings will be provided in addition to existing formatting tools, yielding a set of four with broadly overlapping scopes:
format % values expression
string.Template module-based utility
str.format() method
f'...' interpolation literal
As usual, this new scheme is imagined to be simpler than those that preceded it, and it is justified in part on grounds of similar tools in other programming languages—arguments so common to each new formatting tool that reading the new proposal's PEP is prone to elicit strong déjà vu. But as also usual, the difference between the proposed and established is mind-numbingly trivial:
'we get %s alot' % spam # the original expression
'we get {} alot'.format(spam) # the later method
f'we get {spam} alot' # yet another way to do the same thing...
In a tool as widely used as Python, neither special case nor personal preference should suffice to justify
redundant extension. This proposal almost completely duplicates existing functionality, especially for Python
programmers who know about vars()—a built-in which allows variables to be named by
dictionary key in both the original formatting expression and the later formatting method and template tool,
and suffices for the vast majority of interpolation-style use cases:
>>> name = 'Sue'
>>> age = 53 # keys/values in vars()
>>> jobs = ['dev', 'mgr']
>>> '%(name)s is %(age)s and does %(jobs)s' % vars() # expression: original
"Sue is 53 and does ['dev', 'mgr']"
>>> '{name} is {age} and does {jobs}'.format(**vars()) # method: later addition
"Sue is 53 and does ['dev', 'mgr']"
>>> from string import Template # Template: wordier option
>>> t = Template('$name is $age and does $jobs')
>>> t.substitute(vars())
"Sue is 53 and does ['dev', 'mgr']"
>>> f'{name} is {age} and does {jobs}' # do we really need a 4th?
"Sue is 53 and does ['dev', 'mgr']"
Better yet, skip the vars() hack above, the new f-strings in 3.6,
and the innately convoluted expression nesting of interpolation in general,
and code Python in Python—using the tools it has provided since its genesis:
>>> '%s is %s and does %s' % (name, age, jobs) # simpler is still better "Sue is 53 and does ['dev', 'mgr']"
Though rationalized on grounds of other languages and obscure use cases, in truth the new
f'...' scheme simply provides roughly equivalent functionality with roughly
equivalent complexity and is largely just another minor variation on the formatting theme.
The f-string's only real distinction from existing tools is its extra and intrinsic
support for writing nested and unreadable code.
Moreover, the f-string proposal's entire basis seems a massive red herring: realistic programs record and process their information in larger data structures—not individual variables—and are unlikely to rely on direct variable substitution in the first place. In practice, f-strings seem destined to be at most a redundant solution for limited roles and artificial use cases.
Worst of all, the net effect of this proposal is to saddle Python users with four formatting
techniques, when just one would suffice. The new approach adds more heft to the language without clear
cause; increases the language's learning requirements for newcomers; and expands the size of the
knowledge base needed to reuse or maintain 3.X code—even if you don't use it, you can't prevent
others from doing so. Frankly, the str.format() method was already redundant; adding yet
another alternative seems to be crossing over into the realm of the reckless and ridiculous.
If you're of like opinion, this page's author suggests registering a complaint with Python's core developers before 3.6 gels too fully to make this a moot point. The pace of change in the 3.X line need be only as absurd as its users allow.
Update The f-string proposal was eventually adopted in 3.6, so there's not much you can do about lobbying for its omission today. Alas, this sadly redundant extension will probably endure as Python baggage forever. You can, however, still vote with your code; given that none of the very many programs written in Python's first quarter century used f-strings, yours may find themselves in very good company.
2. Yet Another String Formatting Scheme: i'...'?
Actually, the prior item's story gets worse. Since the f-string note above was written,
a new Python 3.6 PEP has been hatched to add yet another special-case string form—the i-string,
described as "general purpose string interpolation" and coded with a leading "i" (e.g., i'Message with {data}');
which is almost like the already accepted f-string above, new in 3.6 and coded with a leading
"f" (e.g., f'Message with {data}'); but not exactly.
This page won't lend credence to this proposal by covering it further here; please see its PEP for details—and be sure to note its C#-based justification. It follows the regrettably now-established Python tradition of bloating the language with new syntax for limited use cases which could be easily addressed by existing tools and a modest amount of programming knowledge. In this case, Python 3.6 is already expanding on itself in utero, sprouting new special-case tool atop new special-case tool.
This PEP is not yet accepted for 3.6 (and may not make the cut in the end) but if ever made official will bring the string formatting options count to a spectacularly redundant five. One might mark this up to a bad April Fools' Day joke, but it's still February...
Update
The i'...' string notation still hasn't made it into Python as of late 2019.
F-strings, however, have already managed to carve out a kludge-ridden path all their
own; see the Python 3.8 notes above.
Update
Although i'...' failed to launch, a t'...' string notation
did touch down much later in Python 3.14 (and after this book's 6th Edition was
written). This syntax creates a template object with
obscure, esoteric, and superfluous roles that were not important for over three decades
of Python's history. Nevertheless, it increments the number of redundant formatting
tools yet again, and like so many Python extensions, adds to the language's heft just to
placate the whims of a very few developers.
When are Pythonfolk going to buy a vowel about this stuff?
3. Windows Launcher Hokey Pokey: Defaults
Per its early documentation,
Python 3.6 will change its py Windows launcher to default to an installed Python 3.X
instead of a 2.X when no specific version is specified, in some contexts. For background
and discussion on the change, see here
and here.
Here's how 3.6's What's New describes the change at this writing:
The py.exe launcher, when used interactively, no longer prefers Python 2 over Python 3 when the user doesn’t specify a version (via command line arguments or a config file). Handling of shebang lines remains unchanged - “python” refers to Python 2 in that case.
The launcher's prior policy of defaulting to 2.X—in place since 2012's Python 3.3—made little sense, given that the launcher was shipped with 3.X only. As this page's author pointed out 4 years ago in this article (and later in the book), users installing a Python 3.X almost certainly expected it to be the default version used by a launcher that comes with the 3.X install. Choosing 2.X meant that, by default, many 3.X scripts would fail immediately after a 3.X was installed. The remedy of setting an environment variable (or other) to force 3.X to be selected was less than ideal and arguably no better than the case with no launcher at all.
The new 3.6 behavior improves on this in principle. Unfortunately, though, it seems both too
little and too late—this is a backward-incompatible change that will complicate matters by
imposing launcher defaults that vary per 3.X version. Worse, the default policy is unchanged for #!
(a.k.a. "shebang") lines that name no specific version, leaving users with
three rules to remember instead of one:
#! version-agnostic launches prefer a 2.X
#! version-agnostic launches prefer a 3.X
#! version-agnostic launches prefer a 2.X
The former single rule—always preferring a 2.X if installed—may have been subpar, but it was certainly simpler to remember and has become an expected norm widely used for the last 4 years. The 3.6 change's net result is to complicate the story for 3.X users; triple the work of 3.X documenters; and frustrate others tasked with supporting Python program launches on Windows across the 3.X line.
There was a time when convolution was an explicit anti-goal in the Python world. Alas, the methodology of perpetual change in Python 3.X today seems something more akin to a development hokey pokey (insert audio clip here).
4. Tk 8.6 Comes to Mac OS Python—DOA
The Mac OS X version of Python from python.org may finally support version 8.6 of the TK GUI library used by Python's tkinter module. This is welcome news, given the confused and tenuous state of tkinter on that platform in recent years. As it stands today, tkinter programs largely work on Macs but require careful installation of an older Tk 8.5 from a commercially oriented vendor and exhibit minor but unfortunate defects that don't exist on Windows or Linux and can be addressed only by heroic workarounds when addressable at all—not exactly ideal for Python's standard portable GUI toolkit.
Hopefully, a Tk 8.6 port will address these concerns. With any luck, the Python 3.6 installer will also include Tk 8.6 on the Mac as it does on Windows, to finally resolve most version jumble issues. There is also a rumor that Tk 8.7 may support the full UTF-16 range of Unicode characters—including those beyond Tk's current UCS-2 BMP range—but this is a story for 2017 (or later) to tell. For now, Tk requires data sanitization if non-BMP characters may be present (scroll down to PyEdit's About emojis notebox for a prime example).
Update Except it didn't happen: as of 2017, the Tk 8.6 update hasn't appeared—python.org's Mac Python 3.6 still links to and requires Tk 8.5, unfortunately. Maybe in 3.7? Till then, Homebrew Python might be an option for accessing more recent Tks... but for the fact that Homebrew Python+Tk is currently broken as this update is being written in June 2017. The Mac could really use more attention from open-source projects, especially given the increasingly dark agendas in Windows.
Update At long last?: as of spring 2018 and Pythons 3.6.5 and 2.7.15, python.org now offers installers for Mac OS 10.9 and later that bundle Tcl/Tk 8.6. An alternative Python 3.6 installer for 10.6+ still requires a third-party Tcl/Tk 8.5 as before. You can read the release notes here and here (and the Mac Python comic here).
Assuming the new 10.9+ installs' Tks work properly, this means that Mac users of many popular GUI programs—including Python's own IDLE and the source-code versions of all those available on this site—no longer need to fetch and install a Tcl/Tk separately; are ensured of having a recent release of these libraries without navigating iffy third-party options; and have finally achieved install parity with Python users on Windows. And there was much rejoicing...
Update Except it doesn't work: per preliminary testing in May 2018, it looks like the Tk 8.6 shipped with python.org's new Python 3.6 for Mac OS 10.9+ is at best different enough to require code changes and workarounds and at worst too buggy to use. This is irrelevant on Windows and Linux and does not impact Mac apps that bundle their own Python and Tk, but Mac source-code users should carefully evaluate the new install before adopting it.
In testing against the apps hosted on this site: immediately after installing the new Python/Tk, it ran into a hard crash while trying to post a simple file-save dialog in the PyEdit program. This crash was severe enough to kill Python altogether, trigger the dreaded ignore/report system dialog, and post the following console message:
2018-05-16 11:21:36.290 Python[501:12731] *** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: 'File types array cannot be empty' ...details cut... libc++abi.dylib: terminating with uncaught exception of type NSException Abort trap: 6
This may reflect a change in Tk 8.6, but the code that posts the file-save dialog is straightforward; passes its file-types argument correctly; and has worked flawlessly on all prior Python and Tk versions used in the past—including those on Mac OS. This is clearly an issue in the new install and probably a bug in its bundled Tk 8.6. Because they are packaged as a unit, though, the new install's Python inherits all the defects of the bundled Tk.
You can read more about the crash (plus hints of additional issues) among the comments and full console log in this file. Technically, the crash occurred on High Sierra using the bundled Tk 8.6.8, but a similar file-save dialog crash has been seen on Sierra using a Tk 8.6.7 built with Homebrew. Not surprisingly, Tk has been thrashing over Mac OS file dialogs since 8.6.6, per the treads here and here.
You should also test against your own programs, of course, and may be able to address this particular crash by code changes. For programs here, though, it's a showstopper. The new Mac Python/Tk failed right out of the gate on a basic and fundamental GUI task. That hardly instills confidence in its robustness; most likely, this is indicative of major issues and a cautionary symptom of an install that may break as much as it fixes (see also the Tk 8.6 thread crashes ahead).
All of which is a perfect example of an all-too-common dilemma facing software developers today. When new releases of tools are incompatible or buggy, the costs of coding new workarounds and rereleasing products can easily preclude software upgrades. The net effect is to freeze programs and their users in the past—no matter how hard those tools may strive to erase it.
5. Coding Underscores in Numbers
This section was expanded in November 2019.
As a minor but purportedly useful extension, numeric literals in 3.6 will allow embedded underscores,
to clarify digits grouping. For example, a 9999999999 can now be coded as
9_999_999_999 to help the reader parse the magnitude. Clever, perhaps, though
use of this extension will naturally make your code incompatible with—and unable to
run on—any other version of Python released in the last quarter century.
More fundamentally, this change seems far too narrow in scope and utility to justify the baggage it adds to the language. It's rare in the extreme for Python programs to include large numeric literals in their code: numbers are normally input and computed, not hardcoded in source files. Example: it would probably take no more than one hand to count the number of such literals coded over this developer's 35-year software career.
Moreover, while this might be of interest to people who use Python's interactive prompt like a calculator (perhaps in concert with numeric libraries), the underscores are still purely cosmetic and temporary in this role: Python won't insert them in results echoed back to you, and its string-formatting support for digit groupings requires manual program requests and doesn't normally print underscores in any event:
>>> x = 9_999_998 # your number with "_"s for digit groupings
>>> x # but displays drop the groupings anyhow
9999998
>>> x + 1 # ditto for derived computation results
9999999
>>> '{:,}'.format(x + 1) # and even if you request them, it's commas
'9,999,999' # not very symmetric, that
On top of that, Python does not check or require that the underscores make sense as thousands separators; in fact, there's no error checking at all, except for disallowing leading, trailing, and multiple appearances. The underscores are really just digit "spacers" that can be used—and misused—arbitrarily:
>>> 99_9 # no position-error checking provided 999 >>> 1_23_456_7890 # err, what? 1234567890 >>> _9 NameError: name '_9' is not defined >>> 9_ SyntaxError: invalid token >>> 9_9__9 SyntaxError: invalid token >>> 9_9_9 # syntax oddities checked, semantics not 999
Interestingly, the underscores can be used in all sorts of numeric literals. Floating-point numbers allow them on either side of the decimal point, and they can also show up in integers coded in other bases—though neither does any sort of sanity check on the usage, and neither retains the underscores you code:
>>> 1_234_567.99 # floating points: thousands grouping 1234567.99 >>> 1_234_567.987_654_3 # anywhere after the "." too 1234567.9876543 >>> 3.1_415_9e+100 # but anything goes, and "_"s are discarded 3.14159e+100 >>> 0b1111_1111_1111_1111 # binary integers: hex groupings 65535 >>> 0b111_111_111_111_111_1 # octal groupings, more or less? 65535 >>> 0xf_ff_fff_f_f # hex integers: anything goes here too 4294967295 >>> hex(0xf_ff_fff_f_f) # and Python won't retain your "_"s '0xffffffff'
Underscores or not, numeric objects always store their values in binary form in computer memory. Decimal digits and commas are just human-readable formatting, and 3.6+ underscores are just a human-readable input notation—discarded once your code is read, never checked for actual human readability, and of little use outside programs that are somehow able to hardcode all the data they'll process:
>>> x = 9_999_998 # underscores are temporary in-code notation
>>> x # prints display integers as decimal digits
9999998
>>> '{:,}'.format(x) # formats transpose numeric values on demand
'9,999,998'
>>> bin(x) # but numbers are always stored in binary form,
'0b100110001001011001111110' # like this (or something a bit more complex)
In fact, the only context in which underscores seem a candidate
feature is for programs that read textual values from a data file
and convert them to numeric objects with tools like
int() and its ilk (which have all been extended
with underscore support in 3.6 too). Even here, though, the utility
gain seems a weak argument: human readability is usually not a concern
in raw data written by one program and read by another, and this
would require programs to insert underscores that
appease both Python's rules and readers' expectations:
>>> int('1_234_567') # works in text read from data files too
1234567
>>> eval('1_234_567') # though subject to the syntax rules above
1234567
>>> float('1_2_34.567_8_90') # and does raw-data readability matter?
1234.56789
In the end, underscores in numeric literals seem likely to be an
obscure and scantly used tool in Python and little better than using
a # program comment to clarify digit groupings in the very rare
cases where large numeric literals crop up in a program. Their addition
may make for some interesting final-exam questions but otherwise
complicates the language pointlessly.
You can read more about this change at its PEP. While you're there, be sure to note its prior-art rationale—yet another case of "other languages do it too" reasoning. This tired argument is both non-sequitur and bunk; other languages also have brace-delimited blocks, private declarations, common areas, goto statements, and other oddments that Python seems highly unlikely to incorporate.
Wherever you might weigh-in on this particular change, Python developers do seem to prefer following to leading today much more often than they should. Why the rush to make all languages the same? Python is Python—a tool which has been sufficiently interesting by itself to attract a broad user base; stop muddling it to mimic other tools!
6. Etcetera: the Parade Marches On
Regrettably, it now appears that Python 3.6 will go even further down the rabbit holes of asynchronous programming and type declarations begun in Python 3.5, with new obscure syntax for both asynchronous generators and comprehensions, and generalized variable type declarations. You can read about these changes in 3.6's What's New document and their associated PEPs called out there.
To be blunt: these explicitly provisional extensions have the feel of student research projects, with terse documentation, absurd complexity, and highly limited audience. This is now the norm in 3.X—each new release sprouts wildly arcane "features" that reflect the whims of an inner circle of core developers but make the language less approachable to everyone else. This pattern has grown tedious, and this writer is disinclined to document its latest byproduct cruft any further than their earlier 3.5 notes on this page here and here.
Instead, this page will close its 3.6 coverage by simply reiterating that Python 3.X is still both remarkably useful and arguably fun, if programmers are shrewd enough to stick with its large subset that does not add needless intellectual baggage to the software development task. As chronicled here, the leading edge of Python now sadly entails so much thrashing that its role as a rational basis for software projects is fairly debatable.
Indeed, today's Python ironically stands charged with the same unwarranted complexity that its advocates once criticized in other tools. In a stunning reversal of goals past: it grows less designed and more accumulated with each new release.
But you don't have to use the new stuff. As always, keep it simple—both for yourself and for others who will have to understand your programs in the future. In the final analysis, your code's readability is still yours to decide.
As for Python's own tortured evolution, though... Frankenthon Lives!
Python's next release, version 3.5, has been scheduled for mid-September 2015. It's shaping up to be a major set of language extensions—some of which are not backward compatible even within the 3.X line and many of which cater to a narrow audience. This note is a work in progress and its most recent update reflects 3.5's beta preview releases as of August 2015, so take it with the usual grain of salt.
The official plans for 3.5 live here, and many of its changes are enumerated in its What's New document. In short, though, the major anticipated 3.5 language changes include the items in the following list. Among these, many are not without the usual controversy, most add to language heft, and three (#4, #5, and #7) break backward compatibility within the 3.X line itself.
Update Python 3.5 is now officially released, Python 3.6 is already en route, and all the items previewed in this section wound up being added as described. The tense here should probably be changed from future to present, but the past is the past...
1. Matrix Multiplication Operator: "@"
This Python will add a new @ binary operator, which will perform matrix multiplication,
formerly the realm of numeric libraries such as NumPy. This operator also
comes with a @= augmented assignment form and a new operator overloading method named __matmul__
(along with the normal "r" and "i" method variants). By its detractors, the new @ matrix multiplication
has been called an overly niche tool that expands Python's complexity and learning curve needlessly and may
be too underpowered to be useful when applied to Python's native object types.
You can read more about the proposal in its PEP.
Curiously, though, the @ matrix multiplication operator won't be implemented by any built-in object types such
as lists or tuples in 3.5. Instead, it is being added entirely for use by external, third-party libraries like NumPy.
The latest revision of its PEP discusses this
limitation,
but here's the short story in 3.5.0 final:
C:\Code> py -3.5 >>> [1, 2] @ [3, 4] Traceback (most recent call last): File "In other words, the Python core language has been extended with a new operator that is completely unused by the Python core language. There is nothing else quite like this in Python 3.X; it's as if syntax were being added solely for use by animation libraries or web toolkits which are not part of Python itself. While the new operator can be put to use for application-specific roles with operator overloading, it's pointless syntax and serves no purpose as shipped (except, perhaps, in unreasonably cruel job-interview questions).", line 1, in TypeError: unsupported operand type(s) for @: 'list' and 'list' >>> [1, 2] @ 3 Traceback (most recent call last): File " ", line 1, in TypeError: unsupported operand type(s) for @: 'list' and 'int' >>> [1, 2] * 3 [1, 2, 1, 2, 1, 2] # this is still repetition, not multiplication
Although numeric programming is clearly an important Python domain, the 3.5 @ operator seems an excursion up the very
slippery slope of application-specific language extensions—and leaves most Python users with an oddball expression
in their language which means absolutely nothing.
Update
As a fine point for language lawyers, it can be argued that ellipsis (...) comes close in this department, both in heritage
and pointlessness. That may be so in 2.X, but not in 3.X, the subject of this page.
As described in the book,
in Python 3.X this term has been
generalized to serve perfectly valid roles for all language users—as a
placeholder object (like None)
and a placeholder statement (like pass):
C:\Code> py -3
>>> tbdlist = [...] * 100
>>> def tbdfunc():
...
>>>
>>> tbdlist[-1] # it's a placeholder object in 3.X
Ellipsis
>>> tbdfunc() # it's a no-op statement in 3.X (see p390 in LP5E)
>>>
That is, ellipsis is no longer syntax used only by third-party libraries.
Even so, this misses the whole point; one bad idea surely does not justify another!
2. Bytes String Formatting: "%"
This section was rewritten in full July 2016 (and tweaked later). For a primer on Python strings, see this.
Python 3.5 extends the % binary operator to perform text-string formatting for bytes
objects—an operation formerly limited to str objects. It's suggested that this will
aid migration of 2.X code, and in byte-oriented domains be a simpler alternative to existing tools
such as concatenation and bytearray processing or conversions to and from str.
On the other hand, extending % string formatting to bytes has been questioned on grounds
of fundamental incompatibility of text and bytes in Python 3.X's type model:
bytes objects represent raw byte values (including encoded text) but not decoded Unicode text.
str objects represent decoded Unicode text strings (a.k.a. code points) but not byte-sized data.
Because of these core differences, bytes and str cannot be mixed in most Python 3.X operations.
Extending text-oriented formatting to bytes in 3.5 can be fairly described as a break with this
deliberate dichotomy and a throwback to 2.X's very different and ASCII-focused string model.
This extension's motivation also seems on shaky ground: grafting 2.X's string semantics onto 3.X in the
name of 2.X porting ease is akin to adding private declarations to simplify the translation of C++
programs; the combination dilutes and muddles 3.X's own semantics.
On top of all this, the extension comes with glaring inconsistencies that convolute
the Python string story at large.
Let's see what this means in terms of code. In brief, % string formatting is defined for str
(i.e., text) strings in all 3.X but only for str prior to 3.5. This scope makes sense, given that text
in bytes is still encoded per any Unicode encoding and cannot really pass for "text" in this form at all.
By contrast, text in str is true Unicode characters; each character may map to multiple bytes both when
decoded and encoded but is simply a Unicode text character in a str:
C:\Code> py -3.3 >>> 'a %s parrot' % 'dead' # for str in all 3.X: decoded Unicode text 'a dead parrot' # but not for bytes: text encoding unknown >>> b'a %s parrot' % 'dead' TypeError: unsupported operand type(s) for %: 'bytes' and 'str' >>> b'a %s parrot' % b'dead' TypeError: unsupported operand type(s) for %: 'bytes' and 'bytes'In 3.5 and later,
% works on bytes strings too, but its behavior and requirements are type-specific
and subtly different than for str. For example, the general %s formatting code is retained
by bytes for porting 2.X code, but it's just a synonym for a %b bytes substitution which always
expects a bytes string and inserts its bytes—whether they are ASCII-encoded text or other:
C:\Code> py -3.5
>>> b'a %s parrot' % b'dead' # new in 3.5: bytes, %s == %b
b'a dead parrot'
>>> b'a %s parrot' % bytes([0xFF, 0xFE]) # works for non-ASCII bytes too
b'a \xff\xfe parrot'
>>> b'a %s parrot' % 'dead' # but %s (%b) allows bytes only!
TypeError: %b requires bytes,... not 'str'
>>> b'a %s parrot' % 'dead'.encode('ascii') # manually encode str to bytes
b'a dead parrot'
Really, % isn't defined for bytes at all through 3.4 regardless of types and conversion
codes—% requires and runs method __mod__, which is missing in bytes before 3.5
(Python 2.X has % for both bytes and str but only because its bytes
is its str; % is also supported for its unicode type which corresponds
to 3.X's str):
C:\Code> py -3.3 >>> '__mod__' in dir(str), '__mod__' in dir(bytes) # never works through 3.4 (True, False) C:\Code> py -3.5 >>> '__mod__' in dir(str), '__mod__' in dir(bytes) # sometimes works in 3.5+ (True, True)
And oddly, this extension applies to the % expression only, not the format()
method—an inconsistency which further bifurcates the language and
seems to forget that string formatting now comes in multiple flavors:
C:\Code> py -3.5
>>> 'format' in dir(str), 'format' in dir(bytes) # but % only, not format(): why?
(True, False)
>>> 'a {} parrot'.format('dead') # a special-case rule is born...
'a dead parrot'
>>> b'a {} parrot'.format(b'dead')
AttributeError: 'bytes' object has no attribute 'format'
Bifurcations aside, the 3.5 extension for % seems to build on the preexisting
but arguably confusing rule that allows bytes objects to be made from a plain text string:
as long as a bytes literal contains only ASCII characters inside its quotes, a bytes
object is created with an implicit encoding of the characters to their ASCII byte values.
Without this all-ASCII constraint, there would be no way to map characters to single
byte values. bytes is still just bytes (a sequence of 8-bit values) but allows ASCII
text and converts it to bytes in this special-case context only:
C:\Code> py -3.5
>>> b'a %s parrot' % 'dead' # str characters don't map to bytes
TypeError: %b requires bytes,... not 'str'
>>> b'a %s parrot' % b'dead' # but ASCII character bytes ok here?
b'a dead parrot'
>>> ('a %s parrot'.encode('ascii') % # it's really doing this implicitly
... 'dead'.encode('ascii')) # but ASCII seems too narrow in 3.X
b'a dead parrot'
>>> b'a %b parrot' % bytes([0xFF]) # ditto for binary byte values (%b=%s)
b'a \xff parrot'
>>> 'a %b parrot'.encode('ascii') % bytes([0xFF])
b'a \xff parrot'
Surprisingly, numeric values can be inserted as either binary-value bytes or ASCII-encoded
digit strings—the latter of which seems at odds with both bytes-based data and the
much broader Unicode model of text. In the following, %c inserts a number's binary byte value
from an int or 1-item bytes, but numeric codes like %d and %X expect a number and
insert its ASCII digit string instead. In fact, numeric codes work for bytes as they do
for str, but they perform an extra and implicit ASCII encoding for the result as in the last
example here:
C:\Code> py -3.5
>>> (b'a %c parrot' % 255), (b'a %c parrot' % b'\xFF') # inserts byte values
(b'a \xff parrot', b'a \xff parrot')
>>> (b'a %d parrot' % 255), (b'a %d parrot' % b'\xFF'[0]) # inserts ASCII digits!
(b'a 255 parrot', b'a 255 parrot')
>>> (b'a %04X parrot' % 255), ('a %04X parrot' % 255).encode('ascii') # ditto
(b'a 00FF parrot', b'a 00FF parrot')
While using ASCII for %d and %X may reflect some use cases, ASCII is an arbitrary
choice in this context and may be invalid for byte strings containing text encoded
per other Unicode schemes. bytes objects with UTF16-encoded text, for example,
may require manual steps instead of ASCII-digits insertion. Still, this may be a
moot point: it's impossible for the 3.5 bytes % operation to even recognize an
embedded %d or any other format code unless the bytes object's content is
ASCII-compatible in the first place:
C:\Code> py -3.5
>>> 'a %d parrot'.encode('ascii') % 255 # only an ASCII "%<code>" works!
b'a 255 parrot'
>>> 'a %d parrot'.encode('utf8') % 255 # utf8 is compatible; utf16 is not!
b'a 255 parrot'
>>> 'a %d parrot'.encode('utf16') % 255
ValueError: unsupported format character ' ' (0x0) at index 7
Because bytes don't carry information about text encoding, there is no way
to detect any substitution format code such as %d unless it is in ASCII form.
Hence: 3.5's bytes string % formatting works only for bytes objects
containing ASCII-compatible text.
This is where the extension seems to break down in full: in 3.X's Unicode world,
encoded text must always be qualified with an encoding type, and ASCII is far too
narrow an assumption. Trying to emulate 2.X's ASCII constraints in 3.X
doesn't quite work and leaves us with a semantic black hole:
C:\Code> py -3.5
>>> 'a %b parrot'.encode('latin1') % b'dead' # ASCII-compatible text only!
b'a dead parrot'
>>> 'a %b parrot'.encode('utf16') % b'dead'
ValueError: unsupported format character ' ' (0x0) at index 7
>>> 'a %d parrot'.encode('utf16')
b'\xff\xfea\x00 \x00%\x00d\x00 \x00p\x00a\x00r\x00r\x00o\x00t\x00'
In fact, this extension's all-ASCII and 2.X-like assumptions can yield
nonsensical results when applied in the context of 3.X's more general
Unicode text paradigm. In the first part the following, the ASCII-format-code
and numeric-digit-insertion rules conspire to cause ASCII-encoded text to be
inserted in UTF16-encoded text; in the second part, we wind up with UTF16 in
ASCII, both implicitly and explicitly—the former of which seems especially
error-prone, and all of which underscores the problems inherent in processing
still-encoded text as text:
C:\Code> py -3.5
>>> s = ('a '.encode('utf16') + b'%d' + ' parrot'.encode('utf16')) % 255
>>> s
b'\xff\xfea\x00 \x00255\xff\xfe \x00p\x00a\x00r\x00r\x00o\x00t\x00'
>>> s.decode('utf16')
UnicodeDecodeError: 'utf-16-le' codec can't decode byte 0x00 in position 24:...
>>> b'a %s parrot' % 'dead'.encode('utf16')
b'a \xff\xfed\x00e\x00a\x00d\x00 parrot'
>>> 'a %b parrot'.encode('ascii') % 'dead'.encode('utf16')
b'a \xff\xfed\x00e\x00a\x00d\x00 parrot'
In the process of stretching and weakening 3.X's string model, this extension also
manages to yield new special-case rules that seem sure to trip up
programmers. Among them are the same-type requirements shown
earlier (bytes requires bytes), and the very different behavior of the
%s string substitution code in bytes and str—it inserts byte
values for bytes but a print string for str, making string formatting
an operation whose meaning now varies per string type:
C:\Code> py -3.5 >>> b'a %s parrot' % b'dead' # %s inserts byte values for bytes b'a dead parrot' >>> 'a %s parrot' % b'dead' # but a print string for str! "a b'dead' parrot" >>> b'a %s parrot' % bytes([0xFF]) # ditto for non-ASCII bytes b'a \xff parrot' >>> 'a %s parrot' % bytes([0xFF]) # % is now a type-specific operation! "a b'\\xff' parrot"In sum, 3.5's
bytes string formatting has a strong ASCII orientation:
it assumes ASCII in the subject bytes object's content; produces ASCII in digit
strings for some conversion codes; and builds on the already-implicit ASCII encoding
in bytes literals. To be sure, the only way text formatting can work for
bytes at all is by limiting it to text encoded in trivial 8-bit schemes. The net
result of this constraint, however, confuses 3.X's richer Unicode world with 2.X's
ASCII-focused world and adds new special-case rules in the bargain.
In all 3.X, text string formatting is intrinsically better suited to str
objects—already-decoded Unicode text, whose original source encoding
is no longer present, and whose content may include any characters in the Unicode universe.
Formatting fails for bytes for the simple reason that its text is still encoded: there's
no way to process encoded text correctly without allowing for its encoding, and
restricting bytes to ASCII is dated, artificial, and extreme in Python's
Unicode-aware line (run the following in IDLE if your Äs don't Ä):
C:\Code> py -3
>>> spam = 'sp\xc4\u00c4\U000000c4m' # text formatting is for text: decoded str
>>> spam # original Unicode encoding is irrelevant
'spÄÄÄm'
>>> 'ham, %s, and eggs' % spam
'ham, spÄÄÄm, and eggs'
>>> code = '%s'.encode('utf16') # format codes: decoded Unicode text
>>> code # ASCII requirements don't apply to str
b'\xff\xfe%\x00s\x00'
>>> ('ham, ' + code.decode('utf16') + ', and eggs') % spam
'ham, spÄÄÄm, and eggs'
>>> 'Ä %d parrot' % 255 # digits: Unicode characters (code points)
'Ä 255 parrot' # not ASCII-encoded text: this is 3.X!
>>> 'Ä %04X parrot' % 255
'Ä 00FF parrot'
In the end, text code points are not bytes, and encoded text is not text;
treating these as the same works only in a limited ASCII-based world,
which no longer exists either in Python 3.X or the software field at large:
C:\Code> py -3
>>> s = 'Ä %d parrot \U000003A3 ᛯ \u3494' % 255
>>> s
'Ä 255 parrot Σ ᛯ 㒔'
>>> s.encode('utf8')
b'\xc3\x84 255 parrot \xce\xa3 \xe1\x9b\xaf \xe3\x92\x94'
And if you're still unconvinced (and readers new to Unicode may be), consider
this: even in the very rare cases where bytes formatting might be useful, all that this
extension really saves is two essentially no-op method calls to decode from and encode
to ASCII around a str formatting step—hardly a justification for its paradigm splitting:
C:\Code> py -3.5
>>> b = b'the %s side of %04X' # with the extension: ASCII implicit
>>> b % (b'bright', 255)
b'the bright side of 00FF'
>>> s = b.decode('ascii') # without the extension: ASCII explicit
>>> s = s % ('bright', 255) # just decode + use str % + encode
>>> s.encode('ascii') # and this form works in all 3.X!
b'the bright side of 00FF'
Or simply use simpler tools: formatting is never strictly required, and
component concatenation, substring replacement, and bytearray processing usually
provide alternatives that—like the preceding example—make the
ASCII assumption explicit
(see EIBTI);
do not complicate the language when existing tools suffice
(see KISS);
and are portable across all Python 3.X releases
(see the last 8 years):
C:\Code> py -3
>>> p1 = b'bright' # or KISS: these work in all 3.X too!
>>> p2 = '%04X' % 255
>>> b'the ' + p1 + b' side of ' + p2.encode('ascii')
b'the bright side of 00FF'
>>> b'the $1 side of $2'.replace(b'$1', p1).replace(b'$2', p2.encode('ascii'))
b'the bright side of 00FF'
>>> b = bytearray(b'the side of ')
>>> b[4:4] = p1
>>> b.extend(p2.encode('ascii'))
>>> b
bytearray(b'the bright side of 00FF')
See the 3.5 formatting change's PEP for the full story on its behavior and rationale which we'll cut short here. There may be valid use cases for binary data formatting (e.g., the PEP mentions byte-and-ASCII data streams like email and FTP), but it remains to be seen whether their prevalence justifies a change that blurs the text/binary dichotomy that is one of Python 3.X's hallmarks.
What is clear, though, is that this change comes with constraints and exceptions that seem complex enough to qualify as still-valid counter arguments—especially for an extension whose results can be easily produced with existing tools. Unfortunately, Python 3.X has a growing history of welcoming special-case solutions to tasks that could be solved with general programming techniques. While such solutions may appeal to a subset of Python's user base, they come at the expense of language learning curve at large.
3. Unpacking "*" Generalizations
As covered in Learning Python, in Python 3.4 and earlier,
the special *X and **X star syntax forms can appear in 3 places:
*X in the recipient collects unmatched items in a new list (3.X sequence assignments)
In Python 3.5, this star syntax will be generalized to also be usable within data structure literals—where it will unpack collections into individual items, much like its original use in function calls (#3 above). Specifically, the unpacking star syntax will be allowed to appear in the literals of lists, tuples, sets, and dictionaries, where it will unpack or "flatten" another object's contents in-place. For example, the following contexts will all unpack starred iterables or dictionaries:
[x, *iter] # list: unpack iter's items
(x, *iter, y) # tuple: ditto (parenthesis or not)
{*iter, x} # set: ditto (values unordered and unique)
{x:y, **dict} # dict: unpack dict's keys/values (rightmost duplicate key wins)
These are in addition to the star's original 3 roles in assignments and function headers and
calls. Here is the new behavior in Python 3.5 and later:
C:\code> py -3.5
>>> x, y = [1, 2], (3, 4)
>>> z = [*x, 0, *y, *x] # unpack iterables
>>> z
[1, 2, 0, 3, 4, 1, 2]
>>> m = {'a': 1}
>>> n = {'b': 2, **m} # unpack dictionary
>>> n
{'a': 1, 'b': 2}
>>> n = {'b': 2, **{'b': 3}, **{'b': 4}} # rightmost duplicate key wins
>>> n
{'b': 4}
This change is imagined as a way of flattening structures that requires less
code than traditional tools such as concatenation and method calls, and yields
coding possibilities that some may consider clever. It remains to be seen,
though, whether Python programmers perceive this as an academic curiosity with a
still-limited and special-case scope or adopt it as a broadly applicable tool.
As usual with such extensions, it's straightforward to achieve the same effects with other tools that have long been a standard part of the language and are available to users of all recent Python versions. And also as usual, the new star syntax expands an already large set of redundancy in the language for the sake of stylistic preferences of a handful of proponents:
>>> x, y = [1, 2], (3, 4)
>>> z = x + [0] + list(y) + x # unpack iterables -- without "*"
>>> z
[1, 2, 0, 3, 4, 1, 2]
>>> m = {'a': 1}
>>> n = {'b': 2}
>>> n.update(m) # unpack dictionary -- without '**'
>>> n
{'a': 1, 'b': 2}
>>> n = {'b': 2}
>>> n.update({'b': 3, 'b': 4}) # ditto
>>> n
{'b': 4}
The original proposal for this change also called for adding it to comprehensions:
[*iter for iter in x] # unpacking in comprehensions: abandoned in 3.5But this was dropped in 3.5 due to readability concerns (though this change in general may still raise an eyebrow or two). Moreover, the change's proposed relaxation of ordering rules in function calls was also abandoned in the end due to lack of support. It does, however, allow for multiple star unpackings in function calls—syntax that is an error in 3.4 and earlier:
>>> print(1, *['spam'], *[4, 'U'], '!') 1 spam 4 U !This proposal has been debated since 2008, was originally scheduled for Python 3.4 and later bumped to 3.5, and it may yield more changes in the future. For more details, see Python 3.5's What's New document or the change's PEP document.
On the upside, this is an extension to the core language itself, but it is not a change that is likely to break existing code. Still, its multiple-unpackings in function calls may have consequences for some function-processing tools. More fundamentally, this change overall seems to trade a minor bit of general code for obscure new syntax, in support of a very rare operation—a regrettably recurring theme in Python 3.X.
All opinions aside, such change inevitably sacrifices language simplicity for special-case tools. While the jury is still out on this change, its consequences for both beginners and veterans should be a primary concern. To put that another way: unless you're willing to try explaining a new feature to people learning the language, you just shouldn't do it. Tickets to this one being put to that test would be well worth their price.
4. Type Hints Standardization [ahead]
The Python language may also adopt a standard syntax for type declarations in 3.5, using—and limiting—function annotations. This is so potentially major and controversial a development that it merits its own section ahead.
5. Coroutines: "async" and "await" [ahead]
The Python language may also adopt coroutines with async and await syntax in 3.5
for just one concurrent coding paradigm of limited scope.
Like the prior item, this change is sufficiently broad and contentious to warrant its own
section ahead.
6. Faster Directory Scans with "os.scandir()"?
Spoiler: this story has evolved. Per the updates ahead, the os.scandir() gain
initially noted here is platform-specific and is actually a loss on Macs tested. Even where
os.scandir() helps, its speedup can be fully matched—and perhaps beaten—by simply
using os.stat()/lstat() directly instead of os.path.*() calls. Given that both
schemes require similar changes to os.path.*()-based code, the os.stat()/lstat() solution
seems at least as good in general, and it may be better for some use cases and platforms.
Initial description
Though not a language change per se, there will be a new os.scandir() call in the standard
library, which is reported to be substantially faster than the longstanding and still-supported
os.listdir() and will speed Python's os.walk() directory walker client by proxy.
In a nutshell,
the new call replaces name lists with an object-based API that retains listing state, thereby eliminating
some system calls for attributes such as type, size, and modtime. For example, the traditional way
to process directories is by names:
#!/usr/bin/python3.5
import os, sys
dirname = sys.argv[1] # command-line arg
for name in os.listdir(dirname): # use name strings
path = os.path.join(dirname, name) # type, name, path, size, modtime
if os.path.isfile(path):
print(name, path, os.path.getsize(path), os.path.getmtime(path))
The new alternative in 3.5 produces the same results, but it may cache information gleaned from initial listing
and other system calls on a result object to save time (caution: is_file in the following requires
parenthesis—if used without them as though it were a property, you'll simply reference the method object
which is always True!):
#!/usr/bin/python3.5
import os, sys
dirname = sys.argv[1] # command-line arg
for dirent in os.scandir(dirname): # use dirent objects
if dirent.is_file(): # type, name, path, size, modtime
stat = dirent.stat()
print(dirent.name, dirent.path, stat.st_size, stat.st_mtime)
This change adds useful functionality, rather
than deprecating any, and seems a clear win—it claims to make os.walk() 8 to 9 times faster on
Windows and 2 to 3 times quicker on POSIX systems. Recoding some os.listdir() calls to use
os.scandir() directly as above can yield similar speed improvements. Given that directory walks and
listings pervade many programs, this change's benefits may be widespread. See the new call's
PEP,
benchmarks, and
documentation.
Update 1
As an example use case, testing shows that the comparison phase of the
Mergeall directory tree
synchronizer runs 5 to 10 times
faster
on Windows 7 and 10 with os.scandir(). The savings is especially
significant for large archives—runtime for a 78G target use case's comparison of 50k files in 3k folders
fell from 40 to 7 seconds on a fast USB stick (6x) and from 112 to 16 seconds on a slower stick (7x).
Also note that the scandir() call is standard in the os module in 3.5, but it can also be had for older
Python releases, including 2.7 and older 3.X, via a PyPI package;
Mergeall uses either form if present and falls back on the original os.listdir() scheme as a last resort
for older Pythons. All of which seems proof that language improvement and backward compatibility are not necessarily
mutually exclusive.
Update 2
Or not!—per Mergeall 3.0's Feb-2017
release notes
and
code files,
Python 3.5's os.scandir() does indeed run faster than os.listdir() on both Windows
(5X to 10X) and Linux (2X), but it runs 2 to 3 times slower on Mac OS X, as the call
is used by the Mergeall program and on platforms and filesystems tested. Specifically, these results
were seen when using Mac OS El Capitan and its HFS+ filesystem, with external drives hosting exFAT
and others; here are the times for Mergeall comparison-phase runs on the same data set and drives,
without and with os.scandir():
/Admin-Mergeall/kingston-savagex256g/feb-2-17$ diff \
noopt1--mergeall-date170202-time091326.txt \
opt2--mergeall-date170202-time092217.txt
0a1
> Using Python 3.5+ os.scandir() optimized variant.
4053c4054
< Phase runtime: 5.286043012980372
---
> Phase runtime: 10.12333482701797
Hence, this call is an anti-optimization on Macs, and it should generally not be used there, subject to your code's usage patterns. Alas, one platform's improvement may be another's regression!
Update 3
A final twist: in support of symbolic links, the non-scandir() version of
Mergeall's comparison-phase code was ultimately
changed to use os.lstat() and the stat objects it returns,
instead of os.path.*() calls. It uses code of this form (but
in a more complex context and run very many times for large folder trees):
#!/usr/bin/python3.5
import os, sys, stat
dirname = sys.argv[1] # command-line arg
for name in os.listdir(dirname): # use name strings + stat object
path = os.path.join(dirname, name) # type, name, path, size, modtime
sobj = os.lstat(path)
if stat.S_ISREG(sobj.st_mode):
print(name, path, sobj.st_size, sobj.st_mtime)
This code works the same as the os.path.*() and os.scandir() variants above
(saved as files ls1.py and ls2.py, respectively; the new
os.lstat() version is ls3.py here):
~/Code$ py3 ls1.py /MY-STUFF/Code/mergeall > ls1.txt ~/Code$ py3 ls2.py /MY-STUFF/Code/mergeall > ls2.txt ~/Code$ py3 ls3.py /MY-STUFF/Code/mergeall > ls3.txt ~/Code$ diff ls1.txt ls2.txt ~/Code$ diff ls2.txt ls3.txt ~/Code$ cat ls1.txt .DS_Store /MY-STUFF/Code/mergeall/.DS_Store 20484 1507832280.0 .htaccess /MY-STUFF/Code/mergeall/.htaccess 921 1507665774.0 __sloc__.py /MY-STUFF/Code/mergeall/__sloc__.py 2356 1497536861.0 backup.py /MY-STUFF/Code/mergeall/backup.py 44994 1496262548.0 ...etc...
As a major side effect, though, this new os.lstat() coding made Mergeall's
non-scandir()-based comparison phase as fast or faster than the
scandir() variant on Windows too.
The non-scandir() variant remained 2X quicker on Macs, and in fact improved slightly.
Here are the final numbers for Mergeall 3.0's comparison phase run on a 60k-file archive
on the platforms and filesystems tested (these should naturally be verified on yours):
On Windows, the non-scandir() and scandir() variants now both take 10 seconds, with the
non-scandir() version sometimes checking in at 9.N. Linux times are proportionally similar.
On Mac OS X, the scandir() variant takes 9 seconds; the prior non-scandir() version
(os.path.*()) takes 4 seconds;
and the final non-scandir() version
(os.lstat()) takes just 3.8 seconds.
Consequently, Mergeall was able to drop the redundant and now-superfluous scandir()-based
variant altogether, as it was both anti-optimization on Mac and bested by stat-based code on Windows.
This eliminated a major maintenance and testing overhead of prior releases.
In the end, scandir() now seems an extraneous tool. It can indeed speed programs that formerly
used multiple os.path.*() calls on some platforms but requires program changes no less extreme
than os.stat()/lstat(). Moreover, it performs worse on Mac OS X, and elsewhere
it does no better
and perhaps worse than programs coded to use stat objects directly. Given that programs must
be changed or coded specially to use either scandir() or os.stat()/lstat(),
the latter seems the more effective way to optimize cross-platform code.
The scandir() call's internal use by os.walk() seems its only remaining justification—though
os.walk() also could have simply used stat objects to achieve the same performance gain. While
this is now officially hindsight, augmenting the os.path.*() calls' documentation to note the
stat-based alternative's speed boost may have been shrewder than adding a redundant tool
with similar coding requirements but uneven and platform-dependent benefit.
7. Dropping ".pyo" Bytecode Files
Also in the non-language department:
Python 3.5 will abandon .pyo optimized bytecode files altogether, instead naming optimized bytecode
files specially with an opt- tag, which makes the file similarly distinct from non-optimized bytecode.
For instance, after starting Python and importing a mymod.py, the __pycache__ subfolder's bytecode file
content now varies between Python 3.3 and 3.5 (use a command line like py -3.5 -OO -c "import mymod" to
run and import in a single step):
mymod.cpython-33.pyc # from "py -3.3" mymod.cpython-33.pyo # from "py -3.3 -O" and "py -3.3 -OO" mymod.cpython-35.pyc # from "py -3.5" mymod.cpython-35.opt-1.pyc # from "py -3.5 -O" mymod.cpython-35.opt-2.pyc # from "py -3.5 -OO"Though this is a CPython implementation-level change, it will likely have major backward incompatibility consequences—
.pyo files have been around forever and are almost certainly assumed and used by very
many tools. Moreover, the change may seem largely cosmetic on a first-level analysis—trading a name
extension for a name tag. See the PEP for full details.
Update, Feb-2018
In the same department: Python 3.7 will further muddle the bytecode-file story,
by introducing a hash-based mechanism for detecting out-of-date .pyc files.
Read the details here.
This is an alternative to the original timestamp-based detection (which is still the default)
and comes in two different flavors (one of which doesn't check files at all).
So... despite the long-successful prior model, .pyo is now dropped,
and .pyc has grown from one variant to three.
See how we thrash!
8. Windows Install-Path Changes
On Windows, Python 3.5.0 by default now installs itself in the user's normally hidden
AppData folder, with a unique folder name for 32-bit installs, instead of using
the former and simpler scheme. The impacts of this path change are compounded by the
fact that Python's install folder is not added to the user's PATH setting by default.
Especially for novices, these changes make common tasks such as studying the standard
library and running python command lines more difficult and invalidate much
existing beginners documentation. In practice, many Python users won't even be able
to find Python 3.5 on their machine after installing it.
You (and your code) can inspect the install path with sys.executable. A default install of
Python 3.4 lives at the following simple path, the scheme used for all recent Python 3.X and
2.X installs (if you're checking this live, Python displays \\ as an escape for a \):
C:\Python34\python.exe # original, through 3.4By contrast, a 3.5 default install—selected by an immediate "Install Now"—winds up in one of the following much longer and normally hidden paths, depending on whether you run the 64- or 32-bit installer:
C:\Users\yourname\AppData\Local\Programs\Python\Python35\python.exe # 64-bit C:\Users\yourname\AppData\Local\Programs\Python\Python35-32\python.exe # 32-bitTechnically, this reflects the 3.5 installer's single-user default. It's possible to use custom install options to choose different schemes. For instance, an all-users install—selected by "Custom installation", "Optional Features", and "Install for all users" in "Advanced Options"—stores Python in a shorter and non-hidden path (minor update: in Python 3.5.1, the "Python 3.5" in the following may become "Python35" in a token nod to consistency):
C:\Program Files\Python 3.5\python.exe # 64-bit, 32-bit on recent Windows C:\Program Files (x86)\Python 3.5\python.exe # 32-bit on some machinesIt's also possible to select any install path in "Advanced Options" (including that used in 3.4 and earlier), but this is 3 or 4 levels deep in the installer's screens. Realistically, because single-user installs without
PATH settings are the default, they are also likely to be the
norm for most people new to Python—the very group that will struggle most with hidden
folders and paths.
The default install path was reportedly changed for security reasons on multiple-user machines,
though this rationale is likely irrelevant to the vast majority of Python users.
The new path isn't a problem for launching Python if you always use either filename associations,
the Start button's menu, or py executable command lines (e.g., py, py -3.5 script.py);
in these contexts, paths and PATH settings are not required. But this implies multiple and
platform-dependent launching techniques to learn and use, when python and PATH settings
are more generic. Moreover, the use of hidden folders seems hardly in the spirit of open source;
users should be encouraged to view Python's own code, not hindered.
There seems no ideal remedy for this change. Beginners are probably best advised to either perform a
custom all-users install with PATH setting enabled; or avoid python command lines,
and change the folder view to show hidden files—and hence Python 3.5. See Python 3.5's
Windows install docs
for more details on the new installer's policies. As this change seems prone to invoke complaints,
also watch for news on this front.
Update The 32-bit Windows installer for the new 3.0.0 Pillow imaging library on Python 3.5 appears to be broken on 3.5.0 too, and the new Python installer and its new install paths seem prime suspects, though there are already bug reports regarding the installer's system settings (as well as posts on forums from confused users unable to find Python 3.5 after an install...).
Update
As of Python 3.8 in 2020, you can still forcibly install Python to C:\Python
to emulate its former location, by simply using the custom screens of the Python installer,
like this.
There are no known negative consequences of doing so, and your Python paths will
be much shorter—an advantage that will become glaringly obvious the
first time you go hunting for an under-documented library module's code.
The python.org Windows installers also now have a scantly publicized option
to lift path-length limits but haven't fully fixed blurry tkinter GUIs on Windows 10;
see this site's coverage here and
here.
9. Tk 8.6 and tkinter: 👍 PNGs and File Dialogs, 👎 Color Names
Python 3.5 supports Tk 8.6—the latest version of the GUI library underlying the tkinter module—and provides
it automatically with the standard Windows installer at
python.org. Tk 8.6 was first adopted this way in Python 3.4
so most of this note applies to that release too, though some installs of both Python 3.4 and 3.5 may use older Tks
(e.g., Mac OS X); check your Tk version with tkinter.TkVersion after importing tkinter to see if this note
applies to you. While largely compatible, Tk 8.6 has some noteworthy changes.
In the plus column, Tk 8.6's native PhotoImage object now
supports PNG images in addition to GIF and PPM/PGM, making some installs
of the Pillow (a.k.a. PIL)
image library for Python unnecessary for programs that simply display images.
On the other hand, Pillow does much more than display;
Tk 8.6 still lacks JPEG and TIFF support; and PNGs without Pillow are naturally available only
for users of Tk 8.6+ (e.g., Python 3.4+ on Windows). As an example, the latest release of the
Frigcal calendar GUI
leverages this to display PNG month images in Pythons using Tk 8.6 and later.
Also an improvement, the version of Tk 8.6 used by the standard Windows install in Python 3.5 (but not 3.4) now uses true native file and folder dialogs on Windows. For example, the folder-chooser dialog has changed from Python 3.4 to Python 3.5. Basic file open and save dialogs on Windows have also morphed and gone more native in Python 3.5; run programs live for a look, and see the Tk change note for more details.
In the minus column, Tk 8.6 changes some color name meanings to conform to a Web
standard, oddly abandoning those it used for the last 25 years. This makes some color names
render differently and often too dark to be used as label backgrounds. Specifically,
"green", "purple", "maroon", and "grey/gray" are now much darker before. You must use
"medium purple" for the former "purple", "silver" for what was "gray", and "lime" to get
the prior "green"—though "silver" and "lime" don't work in prior releases, making
these colors now platform-specific settings! The best advice here: to make your code immune
to such breakages and portable across Pythons, use hex "#RRGGBB" strings instead of names for
colors in tkinter. For background details, see the
Tk change proposal
and this Python issue tracker post.
Update
Per a reminder from a
Frigcal
user on Mac OS X, a Python version number does not always imply a Tk version number outside the standard Windows install.
Specifically, the C-language code of Python 3.5's tkinter module gives just this constraint:
Only Tcl/Tk 8.4 and later are supported. Older versions are not supported. Use Python 3.4 or older if you cannot upgrade your Tcl/Tk libraries.In the Frigcal user's case, Python 3.5 on a Mac was using Tk 8.5, not 8.6. Hence, this note applies to Tk version, not necessarily Python version, and has been edited accordingly. In more detail: the python.org Mac Python installer currently requires Tk 8.5 (and recommends ActiveState's install of it); if you wish to use Tk 8.6 with Python on the Mac today, the Homebrew installation system may be the leading option (see the web and this). See also the note about new Tk 8.6 support in Mac Python 3.6 above.
10. Tk 8.6 Regression: PyEdit GUI Thread Crashes in Python 3.5
Preface: this note has evolved over the course of multiple years, from a 2016 initial description, to a first update which proposed a cause that proved irrelevant, to a 2017 second update that describes the final workaround. In the end, it was necessary to replace threads with processes to sidestep the crash altogether. The issue has not resurfaced since this change per the 2018 postscript, though its likely cause is a major tkinter bug triggered by Tk 8.6 per the 2019 epilog. The full tale is a saga typical of realistic programming, which underscores the perils of software dependencies; read it linearly for full dramatic effect (and see also the unrelated Tk 8.6 Mac crash).
Initial description, Aug-2016
Now for the "worse news" on Tk 8.6.
It appears that the version of the Tk GUI library shipped with the standard
version of Python 3.5 (and perhaps 3.4) for Windows has sprouted a new and
serious bug related to threading. This may or may not be fixed in
future Tk versions shipped with future Pythons, but it can lead to
pseudo-random crashes in formerly working Python tkinter GUI code
when run on standard Python 3.5 on Windows and Pythons using Tk 8.6
anywhere.
This issue was first observed on Windows in the "Grep" external file/folder search tool of the text-editor program PyEdit—a program whose prior version was a major example in the book PP4E (the bug impacts the book's version, not later standalone PyEdit releases). Specifically, the "Grep" tool spawns a producer thread to collect matching files and lines and post them on a queue, while the main GUI thread watches for the result to appear on the queue in a timer loop. Per the usual coding rules, the producer thread does nothing GUI-related; all window construction and destruction happens in the main GUI thread only.
This tool worked without flaw since Python 3.1 but started experiencing random crashes under Python 3.5. When using 3.5 on Windows, the program's console records the following strange Tcl/Tk error message just before a hard crash that kills the entire PyEdit process, causing any unsaved file changes to be silently lost:
Tcl_AsyncDelete: async handler deleted by the wrong thread
The vast majority of PyEdit still works correctly on Python 3.5 and Tk 8.6, but Grep usage is prone to fail this way sporadically but eventually. This issue is still being explored, but here are the details so far:
Per the second bullet above, the crash occurs in the Tcl/Tk 8.6 library shipped with python.org's Python 3.5 for Windows and used by Python on some other platforms. Python 3.4 for Windows uses this same Tk, but it's not yet known if the crash occurs in 3.4 too; if not, Python 3.5's Tk interface (or threading) code is suspect. Further findings will be posted here as they appear.
Unfortunately, there is no clear fix for this problem. The best options for PyEdit
users are to: avoid using Grep in Python 3.5 (which reduces utility); run PyEdit
under Python 3.3 or earlier (which a #!python3.3 line can force on Windows);
use an older Tk (which is easier on some platforms than others); or hope that the issue
will be repaired in a future Python and Tk. For the present, though, an apparent bug
introduced in Tk may have impacted very many down-stream programs, products, and users.
All of which should also serve as a lesson to the prudent reader about the darker side of the "batteries included" paradigm of Python and open source in general. External code can be a great time-saver when it works, and it often does. But the more your program depends on such code, the more likely it is to be crippled by a regression in an underlying layer over which you have no control—a potential for disaster which is only compounded by the rapid change inherent in open source projects. Unless you are able to stick with older working versions for all time, you should be aware that software "batteries" can also be your project's weakest link.
Update 1, Sep-2016 (This update's suspicion later proved irrelevant; skip ahead to the next update if you're looking for this bug's resolution.) On further investigation, it appears that the Tk 8.6 thread crash described above may be triggered by the insertion of a pathologically long line of text into a listbox. The crash is roughly reproducible for a folder having a Grep result line that is 423k characters long—a saved web page (that is presumably trying to hide something?):
>>> lens = [] >>> for line in open(r'the-crashing-folder\the-offending-file.html', encoding='utf8'): ... lens.append(len(line)) ... >>> lens.sort() >>> lens [1, 1, 1, 16, 34, 41, 44, 54, 59, 79, 81, 82, 98, 100, 357, 1054, 1754, 8950, 423556]
Tk has historically had issues with long text lines. Per the new theory, the main GUI thread adds this absurdly long line to the results listbox, which in turn somehow causes the bizarre Tk abort on most tries. In other words, this may not be a broad and general threading bug in Tk, because it may require a very specific trigger. The fact that other programs using the same queue-based threading code structure work correctly in Tk 8.6 adds support to this explanation (see PyMailGUI and Mergeall for examples).
On the other hand, this crash is still a Tk regression, and it is still related to Tk's threading model:
Further clarity on this crash may have to await Tk and/or Python developers. Regardless of that outcome, though, this remains a problem caused by upgrading to a new Python—a dire but common pattern and an example of the tradeoffs inherent in reliance upon constantly changing, community-developed software. In this case, the "batteries" gone bad are a fundamental Python GUI toolkit used by very many systems, which cannot be replaced without costly redevelopment. The net result for PyEdit is that a Grep in the latest Pythons is a use-at-your-own-risk proposition. More on this update's findings after a workaround can be coded and tested.
Update 2, Jan-2017 Never mind: the prior update's theory eventually proved to be incorrect. This crash was later observed on Mac OS too and found to be triggered by the fully non-GUI code of the Grep's spawned file searcher. This strongly suggests that this is indeed a random thread bug in the underlying Python 3.5/Tk 8.6 combination, best addressed by a non-threaded coding alternative of the sort described here.
The proposed long-line explanation in the first update above was addressed in code but proved irrelevant—the crash still occurred, albeit rarely enough to evade normal testing. After additional research, it was determined that the crash happened before the GUI's timer-loop polling consumer ever received the queued result, ruling out the handling of fetched lines. Moreover, recodings of the producer thread to both avoid uncaught exceptions and explicitly close input files in all cases also appeared to have no effect. The former should not impact the main GUI thread; the latter should have happened automatically in CPython, and it should not trigger a hard and chaotic crash in either Python or Tk in any event.
Though evidence is still scant—as it's prone to be in a fiendishly random and
brutally dormant crash—Python's threading module now seems a prime suspect,
given that the simpler _thread module has been long used without any such issue
in the PyMailGUI program. The higher-level
threading module adds substantial administrative code for features unused by PyEdit's Grep
(and others), which could conceivably interact poorly with Tk/tkinter's event loop or threading.
In the end, a workaround was coded in PyEdit to completely sidestep the issue,
by using the multiprocessing module's processes, instead of the
threading module's threads. This proved a workable solution, given
the simple list of strings passed from the non-GUI producer to GUI consumer; unlike PyMailGUI,
PyEdit's Grep does not pass unpickleable objects, such as bound-method callbacks, that require
the full shared memory state of threads.
Most importantly, by removing the threading variable in this bug's equation,
multiprocessing removes the guesswork of other theories.
As an added bonus, multiprocessing also may run faster because it allows Grep tasks to
better leverage the power of multicore CPUs. On one Windows test machine, each Grep
process receives its own 13% slice of the CPU, while Grep threads receive
just a portion of the single process's 13% allocation. The net effect is that N parallel
Greps can run roughly N times faster when they are processes. The story is similar
on Mac OS X: processes can consume substantially more CPU time than threads and
finish noticeably faster.
Readers interested in the workaround can find it in the newly released version 3.0
of PyEdit. As explained by resources on that
page, PyEdit is currently shipped both standalone and as part of the standalone
PyMailGUI release.
The crucial code of the fix that chooses from the three spawn options is in the
following snippet. Spawn mode is now configurable in PyEdit and defaults to
multiprocessing, but thanks to interface compatibility, the
code outside this
snippet is unchanged (for the full story, search for "multiprocessing" in PyEdit's main
source file):
class TextEditor:
...
def onDoGrep(self, dirname, filenamepatt, grepkey, encoding):
...
# start the non-GUI producer thread or process [2.2]
spawnMode = configs.get('grepSpawnMode') or 'multiprocessing'
grepargs = (filenamepatt, dirname, grepkey, encoding)
if spawnMode == '_thread':
# basic thread module (used in pymailgui with no crashes)
myqueue = queue.Queue()
grepargs += (myqueue,)
_thread.start_new_thread(grepThreadProducer, grepargs)
elif spawnMode == 'threading':
# enhanced thread module (original coding: crashes?)
myqueue = queue.Queue()
grepargs += (myqueue,)
threading.Thread(target=grepThreadProducer, args=grepargs).start()
elif spawnMode == 'multiprocessing':
# thread-like processes module (slower startup, faster overall?)
myqueue = multiprocessing.Queue()
grepargs += (myqueue,)
multiprocessing.Process(target=grepThreadProducer, args=grepargs).start()
else:
assert False, 'bad grepSpawnMode setting'
# start the GUI consumer polling loop
self.grepThreadConsumer(grepkey, filenamepatt, encoding, myqueue, mypopup)
Although the thread crash was primarily observed on Windows, the
multiprocessing module's portability to Windows, Linux, and Mac OS X makes this
workaround a cross-platform solution.
The multiprocessing module's chief downside seems to be its bizarre implications for
internal imports in frozen executables, but that, sports fans, is a tale for another day—and
the following update.
Postscript, Jan-2018 Following the process-based recoding fix just described, this PyEdit crash did not recur in one year of heavy usage—and has never appeared again. Much of that heavy usage was on Mac OS where the initial Grep crash was also seen, and PyEdit underwent additional changes, including the addition of a warning popup to avoid hangs when the number of matches is very large. Usage and mutation aside, this issue has been filed as fixed and closed. Along with the Mac OS issues noted above, though, it remains a caution regarding "batteries" in general and Tk 8.6 robustness in particular.
It's also worth noting that PyEdit eventually minimized battery dependence by providing stand-alone "frozen" executable packages for each desktop platform, which embed specific and validated versions of Python and Tk and are thus immune to changes in either system. These come with major additional requirements for development and limit programs to frozen versions for all time. On the other hand, their additional benefits of simple installs and enhanced GUI-paradigm integration may justify the extra effort.
For more details on PyEdit's usage of multiprocessing
and frozen executables and their inherent tradeoffs both alone and in combination,
visit PyEdit's home page;
search its main source file for "multiprocessing;"
study its multiprocessing frozen patch file;
and browse its
build folder for additional background.
Epilog, Dec-2019
Per
this Dec-2019 thread
on Tkinter-discuss,
it now looks likely that the thread crash which derailed PyEdit's Grep may be a result
of Python's cyclic garbage collector deleting tkinter objects while non-GUI
threads are running. This in turn triggers code in Tk 8.6 which is
not supposed to be run outside the main GUI thread. For more details,
search for __del__ destructors in tkinter's main
source file
(they clearly interact with Tk),
and see Python's docs for more on the subtle interplay between cyclic garbage collection and
destructors
(the former may indeed run the latter in any thread).
If this is the true cause of the random thread crashes, it
is a serious structural bug in tkinter triggered by threading
changes in Tk 8.6 and will hopefully be repaired soon
(search the PEPs).
Until then, Python's gc garbage-collection control
module
may offer additional workarounds (e.g., forcing or disabling the collector).
For PyEdit's purposes, though, this finding is irrelevant: the recoding to
run workers as processes instead of threads avoided the crash entirely
and also allowed workers to run much faster on
multi-core machines. This scheme isn't applicable to use cases which
require shared thread state, but it seems preferable in cases that do not.
11. File Loads Appear to be Faster (TBD)
When running the Frigcal
calendar GUI program, the time required to initially load calendar files has been substantially reduced
in Python 3.5—from 5 seconds to 3 seconds in one use case and from 13 to 8 in another. It's not
yet clear where the improvement lies, as the load must both read .ics calendar files and parse and
index their contents. Either way, 3.5 has clearly optimized a common task—another great
example of how a programming language can be improved without breaking existing code.
12. The Docs are Broken on Windows and Incomplete
The Python standard manuals included with the Python 3.5.0 Windows installer have issues when some items are selected. For example, on the most-used computer of this page's author, the coroutine documentation in the What's New section yields this politically grievous failure—with an error message that complains about browsers (despite the fact that the Windows 7 host machine's default browser is the latest version of the popular and open-source Firefox) and seems to express a bias for Microsoft and Google (though the Microsoft link simply disses IE 6 which isn't even installed on the machine, and the Google link fails completely).
On top of that, the docs have JavaScript errors (which may or may not trigger the browser confusion)
and don't fully integrate the new 3.5 coroutine changes
(async, for instance, is absent in the function definitions section of compound statements).
Glitches happen, of course, and these may be repaired. But between the bugs and the omissions,
this really seems half-baked;
if you're going to change things radically, you should at least document your work fully.
13. Socket sendall() and smtplib: Timeouts
The sendall() call in Python's standard library
socket
module has subtly changed the interpretation of timeouts as of 3.5, as noted
here.
In short, the limit given by a timeout's value
is now applied to a full sendall() operation, rather than to each individual data
transfer executed during the operation. In some contexts this may mean that
timeout values must be increased for the new semantics. As an example, because
Python's own smtplib module,
used for sending email, internally uses socket.sendall() to transfer the full contents
of an email message, some email clients may require higher timeout values in 3.5 and later.
For more details on this 3.5 change, see the PyMailGUI email client's related change log entry. A change to behavior that has been in place for very many years should come with very strong rationales, especially when the change impacts existing code; you'll have to judge whether this one passes the test.
Update, Feb-2018 On a semi-related note, Python 3.5 also lacks support for FTP session resumption, a mode now required by some FTP servers in the name of enhanced security. You can read the PEP describing the issue here and follow discussion here. Support for this new FTP mode was hashed out during Python 3.5's reign and was supposed to be added to Python 3.6. Unfortunately, the fix never made it into 3.6 and is still languishing in limbo as 3.7 is in beta release. This matters; as is, Python 3.X cannot be used to FTP large files to the GoDaddy server hosting this website, without generating an exception on exit. Isn't fixing the FTP library a better use of Python developers' time than all the experimental feature creep?
14. Windows Installer Drops Support for XP
Beginning with 3.5, the Python Windows installer no longer supports Windows XP. If you want to use Python 3.X on an XP machine, you must use Python 3.4 or earlier. This is despite the very wide usage that XP still enjoys—including, reportedly, half the computers in China as of 2014. Per Python's PEP 11, Python will follow Microsoft's lead on the issue and support only Windows versions that Microsoft still does. To quote the PEP: "A new [Python] feature release X.Y.0 will support all Windows releases whose [Microsoft] extended support phase is not yet expired". So much for open source being free from the whims of commercially interested vendors...
To draw your own conclusions on these and other Python 3.5 changes, watch the What's New and emerging documentation. The next two sections give focused treatment to two of the more controversial 3.5 extensions.
Python 3.5 may adopt a standard syntax for type "hints" (a.k.a. optional declarations), using 3.X
function annotations. There is no new syntax in this proposal and no type checker per se—just
a use case for existing 3.X annotations that precludes all others, and a new typing standard library module
which provides a collection of metaclass-based type definitions for use by tools. The module would be introduced
in Python 3.5, and annotation role limitations would be mandated over time. You can read about this change at its
PEP. In brief, the proposal standardizes
annotating function arguments and results with either core or generic types:
def spam(address: str) -> str: # core types
return 'mailto:' + address
from typing import Iterable # new module's types
from functools import reduce
def product(vals: Iterable[int]) -> int:
return reduce(lambda x, y: x * y, vals)
Interestingly, parts of this proposal are similar to this type-testing decorator, derived from a similar example in Learning Python, 5th Edition. As stated in that book, a major drawback of using annotations this way is that they then cannot be used for any other role. That is, although they are a general tool, annotations directly support just a single purpose per appearance, and hence will be usable only for type hints if this proposal's model becomes common in code. In contrast, a decorator-based solution would instead support multiple roles both by choice and nesting 1.
Python developers seem to be aware of this problem—in fact, they propose to deal with it by simply deprecating all other uses of annotations in the future. In other words, their proposed solution is to oddly constrain a formerly general tool to a single use case. The net effect is to introduce yet another incompatibility in the 3.X line; take away prior 3.X functionality that has been available for some 7 years; and rudely break existing 3.X code for the sake of a very subjective extension. Anyone who is using annotations for other purposes is out of luck; they will have to change their code in the future if it must ever run on newer Pythons—a task with potentially substantial costs created by people with no stake in others' projects.
This seems a regrettably common pattern in the 3.X line; its users must certainly be learning by now that it is a constantly moving target, whose evolution is shaped more by its few developers than its many users. For more on this decision, see this section of the PEP.
Thrashing (and rudeness) aside, the larger problem with this proposal's extensions is that many
programmers will code them—either in imitation of other languages they already know or in a misguided
effort to prove that they are more clever than others. It happens. Over time, type declarations will start
appearing commonly in examples on the web and in Python's own standard library. This has the effect of making
a supposedly optional feature a mandatory topic for every Python programmer. This is exactly what
happened with other advanced tools that were once billed as "optional," such as metaclasses, descriptors,
super(), and decorators; they are now required reading for every Python learner.
In this case, the proliferation of type declarations threatens to break the flexibility provided by Python's dynamic typing—a core property and key benefit of the language. As stated often in the book, Python programming is about compatible interfaces, not type restrictions; by not constraining types, code applies to more contexts of use. Moreover, Python's run-time error checking already detects interface incompatibility, making manual type tests redundant and useless for most Python code. See the decorator mentioned earlier for concrete examples; manual type tests usually just duplicate work Python does automatically.
In Python, constraining types limits code applicability and adds needless complexity. Worse, it contradicts the very source of most of the flexibility in the language. This proposal will likely escalate these mistakes to best practice. We'd be left with a dynamically typed language that strongly encourages its users to code type declarations, a combination that will seem paradox to some and pointless to others.
If you care about keeping Python what it is, please express an opinion in the developers forums 2. If we let this one sneak in, anyone who must upgrade to a new Python 3.X release in the future will likely find themselves with a language whose learning curve and de facto practice are growing to be no simpler—and perhaps more complex—than those of more efficient alternatives like C and C++.
Let's stop doing that. Needless change doesn't make a language relevant; it makes it unusable (see Perl 6).
Footnotes
1 For an example of existing practice that employs multiple-role decorators instead of single-use annotations for optional type declarations, see the Numba system. This system actually does something with the declarations—allowing numerically oriented functions to be compiled to efficient machine code—without imposing the model on every Python user.
2 This change was adopted in 3.5 (which is hardly surprising), but a well-reasoned critique of deprecating other roles for annotations was posted on the python-dev list in October 2015—read the thread here. This post was greeted with a curiously defensive us-versus-them dismissal, along with a suggestion to raise the complaint again after people start complaining. Full points to readers who spot the logic problem there.
In support of the cooperatively concurrent paradigm of coroutines,
this large batch of changes, adopted fairly late in the 3.5 cycle, introduces new syntax for def,
for, and with;
an entirely new await expression; and two new reserved words, async and await,
that will be in a strange new soft keyword category and phased in over time.
This proposal is the latest installment in the volatile and scantly read tale of Python generators,
whose backstory is told here.
Python has long supported interleaved execution of coroutines in both 2.X and 3.X with yield generator functions
and task switchers, as demonstrated in simple terms by this code. Python 3.5 expands on this
and earlier 3.X additions, to convolute the model further with extensions that will be available only to code
run on 3.5 and later.
In short, new syntax in def declares a native coroutine (as opposed to former
generator-based coroutines), and the new await expression suspends execution of
the coroutine function until the awaitable object completes and returns results (similar
in spirit to the yield from available only in 3.3 and later). In code:
async def processrows(db):
...
data = await db.fetch(querystring) # suspend and wait
...
This can be used in conjunction with event loops, of the sort afforded by the asyncio
module added recently in Python 3.4. Former generator-based coroutines coded with yield can interoperate
with the new native coroutines coded with async and await, by using a new
@types.coroutine decorator.
And yes, you read that right: there are now two different and incompatible flavors of coroutines in Python 3.X—generator and native, with subtly divergent semantics. Moreover, coroutines themselves are a very old idea; come with well-known and inherent constraints on code (they generally cannot monopolize the CPU, as the multitasking model is nonpreemptive); and are just one of a variety of ways to avoid blocking states—along with tried-and-true options like threads, which many would consider more general, and which have no special syntax in Python.
Two additional syntax extensions—for with and for—are also part of this
proposal. Presumably, they are the reason developers opted for new def syntax instead
of a simpler built-in async function used as a decorator (though "C# has it" is also
strangely given as an explicit basis in the PEP; more on this ahead). In the abstract:
async with expr as var: # async context managers
suite
async for target in iter: # async iteration loops
suite
else:
suite2
In addition, there is a set of new __a*__ special method names for use by classes that wish
to tap into the new syntax's machinery, a draconian list of
special cases
for programmers to remember—and
a whole lot more.
As this extension seems likely of interest to only a very small fraction of the Python user base, this page won't cover its technical components any further. Please see the PEP on python.org, especially its networking example; its perhaps inadvertent illustration of the proposal's redundancy; and its full changes list. Python 3.5's standard docs are still a bit lacking on this front but may improve with time.
This extension's non-technical aspects, though, deserve all Python users' attention: this change adds yet another layer of complexity to the Python language without clearly valid cause. It seems another example of language design gone bad, on three grounds:
The last point has become an unfortunate pattern. This specific extension seems to have been lifted almost verbatim from other languages including C#/VB and PHP/Hack, so much so that those languages' documentation applies to Python. In the Python world, core developer focus seems to have shifted quickly from functional programming to type declarations and coroutines; where it moves next depends not on users but only on who shows up to change it—and what other language they wish to imitate.
There is still a large subset of Python 3.X which is quite usable (and even fun) for applications development. See the programs here for typical examples; if programmers have enough common sense to stick to this subset, Python is what it always has been. However, Python 3.X also resolutely continues to be a bloated sandbox of often-borrowed ideas, where each current set of people with time to kill and academic concept to promote inserts changes based entirely on personal interest, that inevitably become required knowledge for all.
The end result of this constant-change model is that those who have used Python for decades can now be given a piece of Python 3.X code to use or maintain—and have absolutely no clue what it means. That's even true of programmers who have used only former releases in the 3.X line. This may boost the egos of a small number of individuals responsible for a change, and it ultimately might just serve to maintain the power of a self-sustaining inner circle possessing the latest obscure "special" knowledge.
But it's not necessarily good engineering.
The following sections provide brief looks at noteworthy changes in Python 3.4, released in March 2014 and covered more fully in Python's What's New document for this release. In terms of language changes, Python 3.4 proved to be a fairly minor release, though the later Python 3.5 resumed the 3.X rapid-change paradigm.
Update See also the new Python Pocket Reference, 5th edition, revised for Python 3.4 and 2.7 and available January 2014. It covers some 3.4 topics discussed here.
1. New Package Installation Model: pip
Shortly after this edition was published, Python's core developers
finally settled on pip as the officially sanctioned system for
installing 3rd-party Python packages, with setuptools and other
3rd-party systems recommended for package creation. These are envisioned as
superseding the longstanding distutils. Specifically (and currently):
pip system available
automatically and comes with updated installation manuals that
reference it almost exclusively.
pip instead of distutils but will not ship with pip included.
This step seems still pending; as this note is being written in July 2014, 2.7's manuals
reference distutils.
setuptools are in the 3rd-party domain and not
shipped with Python but can be installed with pip.
distutils will still be
available in the standard library of all Pythons.
This is a tools issue, unrelated to the language or its
standard library directly. As such, it has little impact on the book,
except for the reference to distutils—and its impending
deprecation in favor of a then-named distutils2—in the sidebar
on the subject on pages 684-685 and brief references on pages 731, 1159,
and 1455. The book correctly predicted distutils' demise but could
not foresee pip.
For more details on pip and this change, see the install manuals
for Python 3.4 or later (and perhaps 2.7), as well as the change's
PEP and recommended tools lists:
Of note: unlike the formerly standard distutils, pip is not in the
standard library but is a separate system bundled with Python as of
3.4 only. It must be retrieved and installed by the user in Python
2.7 or 3.3, which makes its uptake uncertain. Or, to quote from the
new Python 3.4 install documentation developed by a new group with the
curious (and perhaps even Orwellian) title
"Python Packaging Authority":
* pip is the preferred installer program. Starting with Python 3.4, it is included by default with the Python binary installers. * distutils is the original build and distribution system first added to the Python standard library in 1998. While direct use of distutils is being phased out, it still laid the foundation for the current packaging and distribution infrastructure, and it not only remains part of the standard library, but its name lives on in other ways (such as the name of the mailing list used to coordinate Python packaging standards development).
In other words, the net effect is yet another new and redundant way to achieve a goal—and a potential doubling of the knowledge requirements in this domain. Improvements are warranted and welcome, of course. Regrettably, though, change in open source projects is often more focused on the personal preferences of a few developers, than on current user base or complexity growth. As always, the merits of such mutations are best decided by practice in the larger Python world.
2. Unpacking "*" Generalizations? (Postponed to 3.5)
After being debated since 2008, a subset of the unpacking * syntax generalization
originally slated for release 3.4 was finally implemented in 3.5—albeit with a limited
scope to make it a bit more palatable.
Namely, the unpacking stars (*) will work in function calls as before. With this
change, they will also work in data-structure literals but not in comprehensions due to
readability concerns. Moreover, the full proposed relaxation of ordering rules in function
calls was also abandoned in the end due to lack of support. Stars also still work to collect
items in function headers and assignments as before.
The original description of the change here has been moved to the Python 3.5 section's coverage of its final form: see above for more details, and see this change's PEP for the full proposal.
3. Enumerated Type as a Standard Library Class/Module
Since its inception, Python has allowed definition of a set
of identifiers using a simple range: for example, red, green, blue = range(3).
Similar techniques are available with basic class-level attributes, dictionary
keys, list and set members, and so on.
As of Python 3.4, a new standard library module makes this more explicit,
with an Enum class in a new enum module that offers a
plethora of functionality on this front. It employs class-level attributes to serve
as identifiers but adds support for iterations, printing, and much more.
An example borrowed from Python Pocket Reference, 5th Ed:
>>> from enum import Enum
>>> class PyBooks(Enum):
Learning5E = 2013
Programming4E = 2011
PocketRef5E = 2014
>>> print(PyBooks.PocketRef5E)
PyBooks.PocketRef5E
>>> PyBooks.PocketRef5E.name, PyBooks.PocketRef5E.value
('PocketRef5E', 2014)
>>> type(PyBooks.PocketRef5E)
<enum 'PyBooks'>
>>> isinstance(PyBooks.PocketRef5E, PyBooks)
True
>>> for book in PyBooks: print(book)
...
PyBooks.Learning5E
PyBooks.Programming4E
PyBooks.PocketRef5E
>>> bks = Enum('Books', 'LP5E PP4E PR5E')
>>> list(bks)
[<Books.LP5E: 1>, <Books.PP4E: 2>, <Books.PR5E: 3>]
As Python programmers seem to have gotten along fine without an explicit enumerated type for over two decades, the need for such an extension seems unclear. And to some, the numerous options afforded by the new class may also seem like over-engineering—extra features without clear use cases (or users). Like all additions, though, time will have to be the judge on this module's applications and merits.
For more details, see Python 3.4's What's New document or the change's PEP document. Note that this is a new standard library module, not a change to the core language itself, and so should not impact working code; some standard library modules may, however, incorporate this new module to replace existing integer constants, with effects that may remain to be seen.
4. Import-Related Standard Library Module Changes
A large number of 3.4 changes have to do with its modules related to the import operation—site of a major overhaul in 3.3 for both imports in general and the new namespace packages described in the book. As this is a relatively obscure functional area which is unlikely to impact typical Python programmers, see 3.4's What's New document for more details, especially its section Porting to Python 3.4.
5. More Windows Launcher Changes and Caveats
See this page for additional issues regarding the Windows launcher shipped and installed with Python 3.3 (and later), beyond those described in Learning Python, 5th Edition's new Appendix B. In short:
PATH settings to defaults for generic python
#! lines (only?).
#! lines for use on Windows.
Given these and other issues covered both in the book and on this page, it seems the 3.3+ Windows launcher aspires to be a tool that makes it easy to switch between installed Pythons but might have worked better as an optional extension than a mandatory change.
Update See also the later Python 3.6 launcher defaults change described above.
6. And So On: statistics Module, File Descriptor Inheritance, asyncio, pypy3, Tk 8.6, email
Other 3.4 items of interest (which didn't seem to merit full sections when first covered here):
statistics module
with statistical functions (e.g., mean, median) akin to those in a basic
calculator—a sort of lightweight alternative to tools in
NumPy, a popular and much more comprehensive
numeric toolkit which was deemed too convoluted for some in the new module's
perceived target audience. Condescending or practical?—you be the judge.
os.set_inheritable(fd: int, inheritable: bool).
asyncio,
was added to the standard library. This module offers alternatives for coding single-threaded
concurrent code using coroutines, multiplexing I/O access over sockets and other resources,
running network clients and servers, a pluggable event loop, and far too much functionality
and API detail to document here. In a nutshell, it fosters a cooperative (nonpreemptive) multitasking
model—but with code structure tradeoffs similar to those imposed by asynchronous
network servers (tasks must generally be short-lived to avoid monopolizing the CPU). See its
PEP and
documentation
for details. See also Python 3.5's async/await coroutines
which extend this extension (no, that's not a stutter).
pypy3
seems substantially slower than pypy2 at present, but this is naturally subject to change.
tkinter GUI toolkit uses the latest 8.6 release as of Python 3.4. Though largely backward compatible,
Tk 8.6 changes the meaning of some color names incompatibly and adds support for PNG image
files which obviates the need for a Pillow install for some programs. For more details, see
the further discussion of Tk 8.6 in the Python 3.5 note above.
Additionally, Tk 8.6 appears to have grown a threading-related bug which is inherited by Pythons
that make use of it, including the standard install for 3.5—and perhaps 3.4—on
Windows (and assorted issues on Mac OS); see the Python 3.5 note above.
email6
package's release may be finalized with Python 3.4; it's not clear what if any impact
this will have on Programming Python, 4th Edition's larger email
examples, which were recently released in Python 3.3 form
[edit: and later, for 3.4, 3.5, and 3.6].
This is TBD, but if the book's (or your) email code doesn't work in 3.4 or later, your most
immediate recourse is to use 3.3 or earlier instead. That's the unfortunate but reasonable
response of users confronted with rapid change in open source projects—a constant
which too often takes the form of reckless and incompatible change for change's (and ego's) sake.
That may seem harsh, but it's also true; for better or worse, Python evolution is often far more
focused on individual preference than common usage.
Update Per testing with Python 3.4, it now appears that Programming Python 4th Edition's major email (and other) examples all work correctly under Python 3.4, with no additional changes (other than those required for Python 3.3). Some minor examples in the book may behave slightly differently, but change is a normal part of the software world. A win, perhaps, though we're not yet taking any bets on 3.5...
Update
Early testing with Python 3.5 shows that the book's PyMailGUI email client also works correctly
and unchanged on that release too, with the patches applied for 3.3.
Hence, although new email coding interfaces
were added, email package breakages may have been limited to the 3.3 release and were addressable by library
patches. Nevertheless, the lesson stands—while improvements are always welcome, incompatible changes to
widely used tools should be driven by the practice of the many, not by the personal preference of the few.
Update
Ditto for Python 3.6 and 3.7: testing thus far shows that PyMailGUI works in these Pythons with no additional changes.
It seems that rumors of the prior email API's demise may have been greatly exaggerated...
For related coverage of Python changes, see also:
{kind=link}
{kind=link}
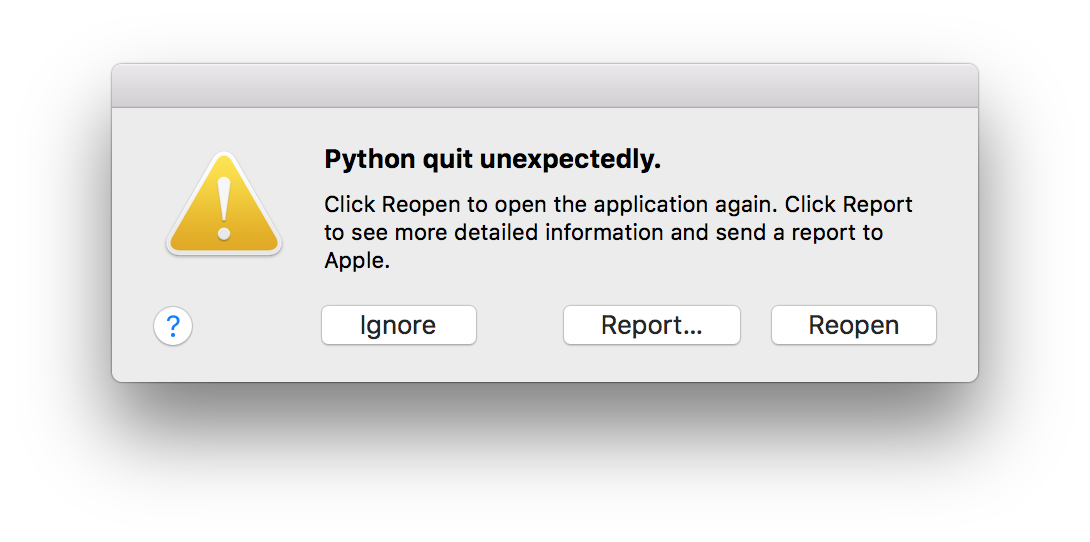{kind=link}
{kind=link}
{kind=link}
{kind=link}
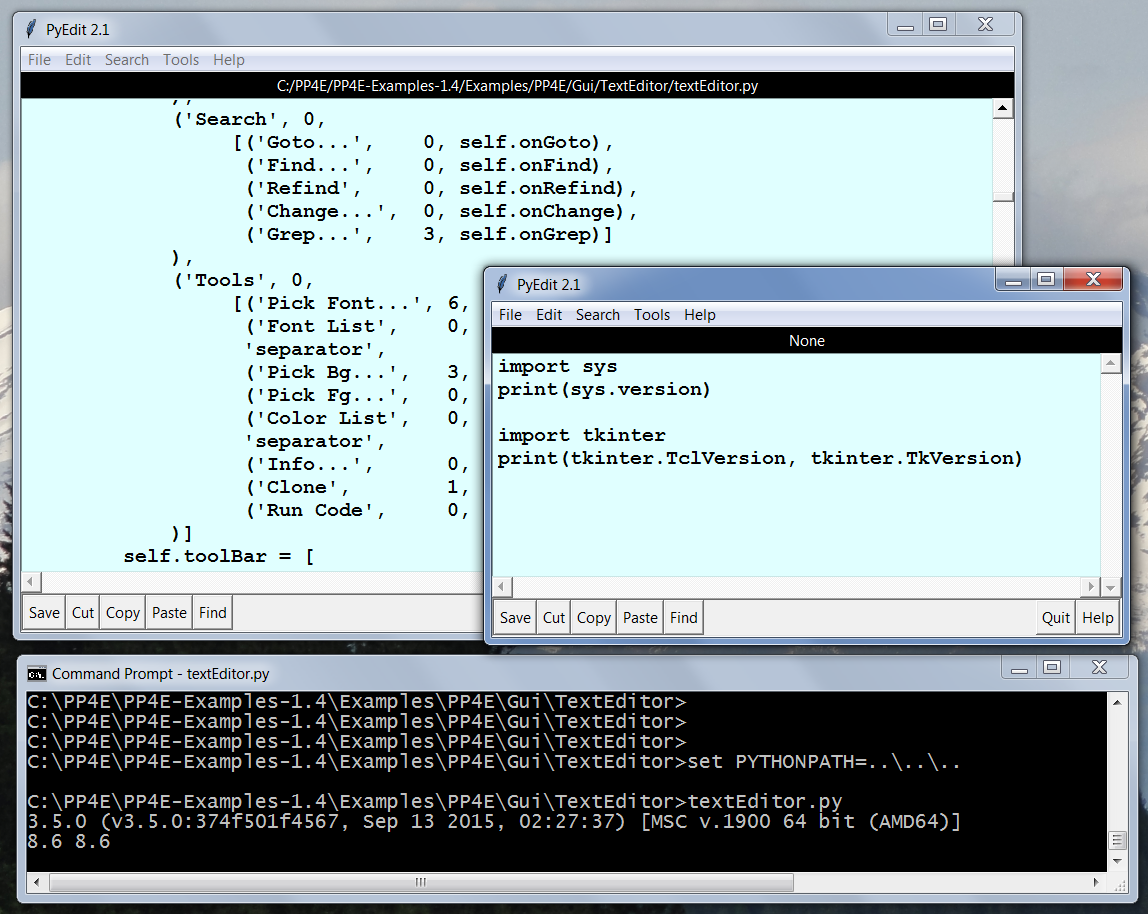{kind=link}
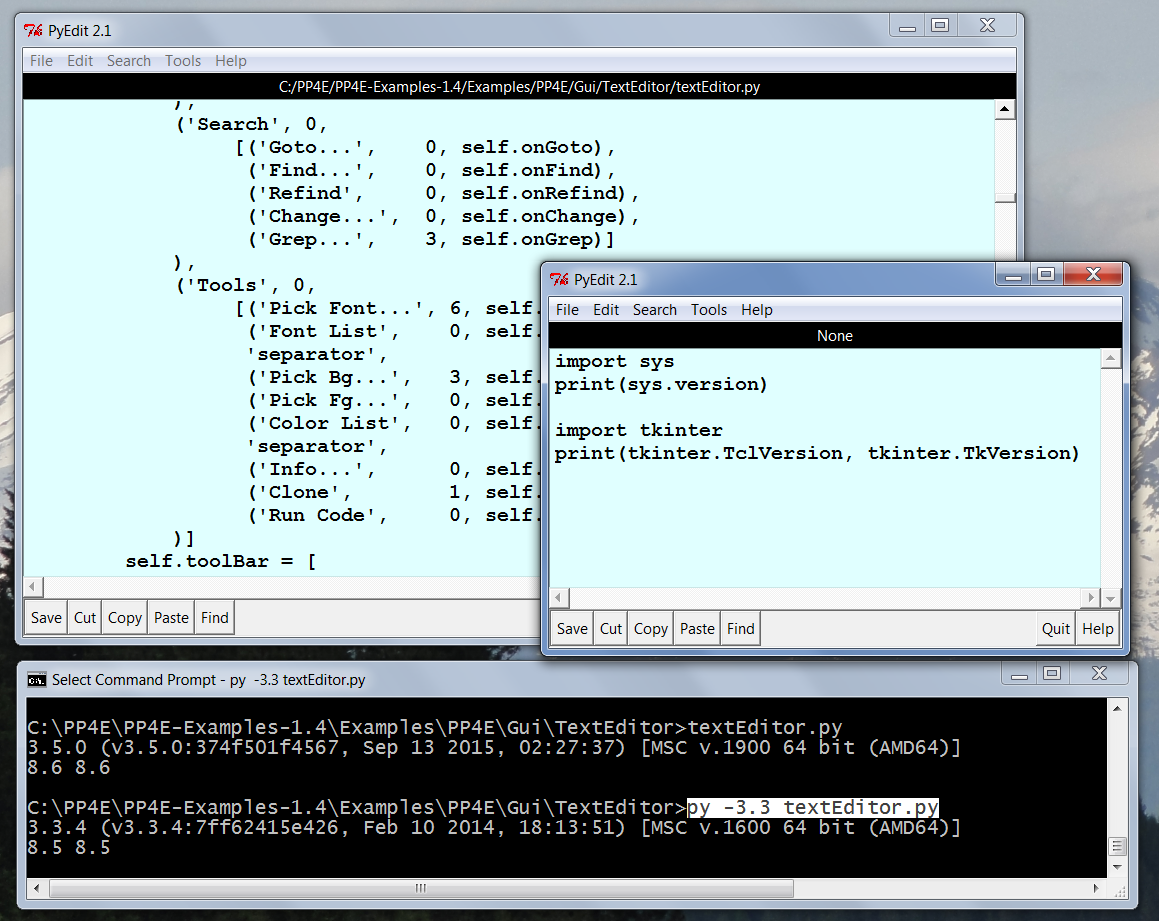{kind=link}
{kind=link}
{kind=link}
{kind=link}